












In der komplexen Welt des Business Process Model and Notation (BPMN) ist der Steuerungsablauf darauf ausgelegt, linear und vorhersehbar zu sein. Doch im echten Leben sind Abläufe selten so einfach. Systeme versagen, die Datenvalidierung schlägt fehl und externe Abhängigkeiten gehen offline. Genau hier werdenFehlerereignissezu kritischen Elementen. Sie bieten einen standardisierten Mechanismus innerhalb der BPMN-Spezifikation, um Ausnahmen zu verwalten, ohne die Integrität des gesamten Prozessmodells zu gefährden.
Eine effektive Ausnahmehandhabung geht nicht darum, jeden möglichen Fehler vorherzusagen. Es geht vielmehr darum, einen klaren Weg festzulegen, wenn Dinge schief laufen. Dieser Leitfaden untersucht die Funktionsweise, Konfigurationen und strategische Anwendung von Fehlerereignissen, um sicherzustellen, dass Ihre Workflows widerstandsfähig bleiben. Wir werden untersuchen, wie man verschiedene Arten von Fehlerauslösern unterscheidet, Fehlercodes korrekt konfiguriert und ein sauberes Prozessdesign aufrechterhält.
Verständnis des Kernkonzepts von Fehlerereignissen ⚙️
Ein Fehlerereignis ist eine spezifische Art von Ereignis, das durch eine Fehlerbedingung innerhalb des Prozesses oder der Umgebung ausgelöst wird. Im Gegensatz zu Nachrichtenereignissen, die auf externe Kommunikation angewiesen sind, oder Signalereignissen, die an die gesamte Engine gesendet werden, sind Fehlerereignisse eng mit dem Ausführungsablauf einer bestimmten Aufgabe oder Aktivität verknüpft.
Wenn eine Prozessinstanz auf ein Problem stößt, muss die Engine wissen, wohin die Ausführung abgeleitet werden soll. Fehlerereignisse wirken als Wegweiser für diese Umleitung. Sie ermöglichen es dem Modell, den glücklichen Pfad (normale Ausführung) vom unglücklichen Pfad (Ausnahmehandhabung) zu trennen.
Wichtige Merkmale sind:
- Spezifität: Sie sind normalerweise Aufgaben zugeordnet, die als fehleranfällig bekannt sind.
- Weiterleitung: Sie können die Hierarchie hinaufsteigen, wenn sie lokal nicht erfasst werden.
- Standardisierung: Sie folgen der BPMN 2.0-Spezifikation für Interoperabilität.
Arten von Fehlerereignissen in BPMN 📋
Es gibt zwei primäre Möglichkeiten, die Fehlerbehandlung in einem Workflow-Diagramm umzusetzen. Die Wahl der richtigen Methode hängt von der Feinheit der Fehler ab, die Sie erfassen möchten.
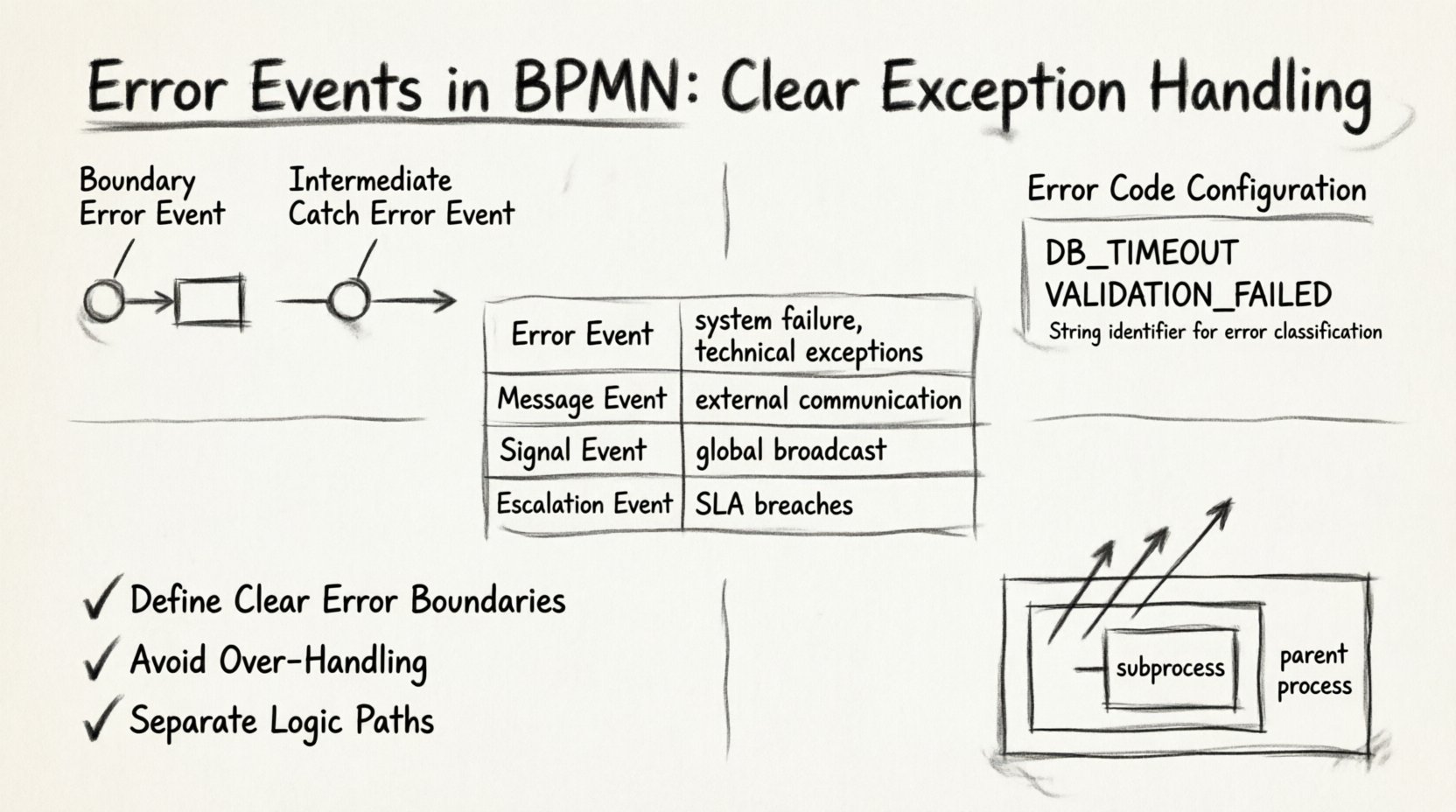
1. Grenz-Fehlerereignisse 🎯
Ein Grenz-Fehlerereignis ist direkt an der Grenze einer Aufgabe, eines Unterverfahrens oder einer Aufrufaktivität angebracht. Es stellt einen lokalen Ausnahmehandler dar. Wenn die Aufgabe ausgeführt wird und einen Fehler auslöst, wird der Ablauf sofort auf den Pfad umgeleitet, der mit dem Grenzereignis verbunden ist.
Dies ist das häufigste Muster zur Behandlung spezifischer Fehler. Es ermöglicht es Ihnen, den Fehler innerhalb des Bereichs der Aktivität zu isolieren. Wenn beispielsweise eine Datenbank-Schreiboperation fehlschlägt, kann ein Grenzereignis diesen spezifischen Fehler erfassen, ohne die gesamte Prozessinstanz anzuhalten.
Vorteile von Grenzereignissen:
- Kapselung: Die Logik zur Ausnahmehandhabung ist visuell direkt neben der Aufgabe platziert, die sie schützt.
- Nicht blockierend: Die Hauptaufgabe läuft weiter, bis der Fehler auftritt.
- Klarheit: Das Diagramm zeigt deutlich, welche Aufgaben Rückfallmechanismen besitzen.
2. Zwischenzeitlich abfangende Fehlerereignisse 🔄
Ein zwischenzeitlich abfangendes Fehlerereignis befindet sich auf der Ablaufverbindung, anstatt direkt an der Grenze einer Aufgabe angebracht zu sein. Diese Art ist weniger verbreitet, aber nützlich, um Fehler zu behandeln, die zwischen Aufgaben auftreten oder innerhalb eines Unterverfahrens auftreten, das im übergeordneten Bereich erfasst werden muss.
Dieser Ansatz wird oft verwendet, wenn Sie Fehler erfassen möchten, die aus einem Unterverfahren heraus propagieren, aber noch die Hauptprozessgrenze nicht erreicht haben. Er ermöglicht eine zentrale Fehlerverwaltung für einen bestimmten Logikblock.
Konfiguration und Attribute ⚙️
Um Fehlerereignisse funktionsfähig zu machen, erfordern sie eine spezifische Konfiguration innerhalb des Modellierungstools und der Ausführungsmaschine. Diese Konfigurationen definieren, was als Fehler gilt und wie das System reagiert.
Definition der Fehlercode
Jedes Fehlerereignis sollte einen eindeutigen Fehlercode. Dies ist ein Zeichenketten-Identifikator, der eine Art von Fehler von einer anderen unterscheidet. Ohne einen definierten Code kann die Engine nicht zwischen einem Datenbank-Timeout und einem Validierungsfehler unterscheiden.
- Zeichenketten-Identifikator: Verwenden Sie eine konsistente Namenskonvention, wie zum Beispiel
DB_TIMEOUToderVALIDATION_FAILED. - Feinheit: Vermeiden Sie generische Codes wie
ERROR_1. Verwenden Sie beschreibende Identifikatoren, die bei der Fehlersuche unterstützen. - Zuordnung: Stellen Sie sicher, dass das externe System oder Skript den exakt im Ereignis definierten Code wirft.
Nachrichten-Zuordnung
Einige Implementierungen ermöglichen es, ein Fehlerereignis einer bestimmten Nachrichtendefinition zuzuordnen. Dies verknüpft den Fehler mit einer für Menschen lesbaren Nachricht, die in einer Benutzeroberfläche angezeigt oder protokolliert werden kann.
- Benutzerfeedback: Ermöglicht dem System, dem Benutzer genau mitzuteilen, was schiefgelaufen ist.
- Protokollierung: Vereinfacht automatisierte Protokollierungssysteme, um Vorfälle nach Fehlerart zu kategorisieren.
Vergleich von Fehlerbehandlungsstrategien 📊
Es ist entscheidend, zu verstehen, wo Fehlerereignisse im größeren Kontext von BPMN passen. Unten finden Sie einen Vergleich von Ereignistypen, um klarzustellen, wann ein Fehlerereignis gegenüber anderen Optionen verwendet werden sollte.
| Ereignistyp | Auslöserquelle | Typischer Anwendungsfall | Umfang |
|---|---|---|---|
| Fehlerereignis | System-/Aufgabenfehler | Technische Ausnahmen, Validierungsfehler | Lokal oder Prozess |
| Nachrichtenereignis | Externe Kommunikation | Warten auf eine Antwort, Empfangen von Daten | Prozessinstanz |
| Signalevent | Globale Aussendung | Stornieren mehrerer Instanzen, systemweite Warnungen | Global |
| Eskalationsereignis | Prozessregeln | SLA-Verstöße, Anforderungen an manuelle Eingriffe | Prozesshierarchie |
Entwicklung für Resilienz: Best Practices 🛡️
Die Erstellung eines Prozessmodells, das Fehler reibungslos behandelt, erfordert eine strategische Herangehensweise. Es reicht nicht aus, lediglich ein Ereignis in das Diagramm zu setzen; die Logik rund um dieses Ereignis muss schlüssig sein.
1. Klare Fehlergrenzen definieren
Fangen Sie keine Fehler ab, die den Prozess beenden sollten. Einige Fehler sind nicht behebbar. Wenn ein Prozess ohne bestimmte Daten nicht weiterlaufen kann, führt das Abfangen des Fehlers und das unendliche Wiederholen dazu, dass ein Zombie-Prozess entsteht. Stattdessen sollten Sie den Fehler nach oben weiterleiten oder die Instanz sauber beenden.
- Kritische Aufgaben identifizieren:Bestimmen Sie, welche Aufgaben für die Funktion des Prozesses unerlässlich sind.
- Beenden bei schwerwiegenden Fehlern:Verwenden Sie Fehlerereignisse, um anzugeben, dass der Prozess nicht weiterlaufen kann.
- Wiederholen bei vorübergehenden Fehlern:Verwenden Sie Grenzereignisse für Netzwerk-Timeouts oder vorübergehende Unzugänglichkeit.
2. Vermeiden Sie eine Überhandhabung
Jede Aufgabe benötigt nicht unbedingt einen Fehlerhandler. Das Hinzufügen von Grenzereignissen zu jeder einzelnen Aufgabe verunreinigt das Diagramm und macht den Ablauf schwer lesbar. Hängen Sie Fehlerereignisse nur an Aufgaben an, die bekanntermaßen fehlschlagen können oder gravierende Folgen haben, wenn sie fehlschlagen.
3. Trennen Sie Logikpfade
Stellen Sie sicher, dass der Pfad nach einem Fehler vom normalen Pfad abweicht. Wenn der Fehlerpfad letztendlich in den Hauptablauf einmündet, verwenden Sie ein exklusives Gate, um sie sauber zu verbinden. Mischen Sie Fehlerbehandlungslogik nicht mit Geschäftslogik.
Datenabbildung und -weiterleitung 📡
Wenn ein Fehler auftritt, geht Daten oft verloren, es sei denn, sie werden explizit abgebildet. Eine der am häufigsten übersehenen Aspekte von Fehlerereignissen ist die Behandlung von Variablen.
Fehlerdaten-Beibehaltung
Wenn eine Ausnahme erfasst wird, speichert das System typischerweise Informationen über den Fehler. Dazu können die Fehlercode, das Zeitstempel und der Zustand der Variablen zum Zeitpunkt des Fehlers gehören.
- Variablen-Erfassung: Konfigurieren Sie die Engine, um den Zustand der Prozessvariablen bei einem Fehler zu speichern.
- Zustandsbeibehaltung: Stellen Sie sicher, dass der Fehlerhandler Zugriff auf die Daten hat, die den Fehler verursacht haben.
Fehler nach oben weiterleiten
Wenn ein Unterverfahren einen Fehler wirft und das Unterverfahren kein Grenzereignis hat, um ihn aufzufangen, steigt der Fehler zum übergeordneten Prozess auf. Dies ist eine entscheidende Funktion für die hierarchische Prozessgestaltung.
- Elternverarbeitung: Der übergeordnete Prozess kann entscheiden, wie auf einen Kindfehler reagiert wird.
- Globale Wiederherstellung: Ermöglicht eine zentrale Wiederherstellungsstrategie für eine Reihe verwandter Aufgaben.
Fehlerbehandlung bei menschlichen Aufgaben 👤
Prozessmodelle beinhalten oft menschliche Beteiligte. Wenn eine menschliche Aufgabe fehlschlägt, verhält sich das Fehlerereignis leicht anders als bei einer Systemaufgabe.
- Aufgabenverzicht: Wenn ein Benutzer eine Aufgabe aufgibt, kann dies ein Fehlerereignis auslösen.
- Zeitüberschreitungen: Wenn eine Aufgabe innerhalb einer festgelegten Zeit nicht abgeschlossen wird, kann eine Eskalation oder ein Fehler ausgelöst werden.
- Umbenennung: Fehlerereignisse können die Aufgabe an einen anderen Benutzer oder eine andere Warteschlange weiterleiten, wenn der ursprüngliche Zuweiser versagt.
Bei der Gestaltung für menschliche Aufgaben beinhaltet der Fehlerpfad oft eine Benachrichtigungsmechanismus. Dies könnte eine E-Mail-Warnung oder eine Dashboard-Benachrichtigung an einen Vorgesetzten sein.
Testen und Validierung 🔍
Sobald das Modell erstellt ist, muss es getestet werden, um sicherzustellen, dass die Fehlerpfade wie vorgesehen funktionieren. Statische Analyse reicht nicht aus.
Simulations-Szenarien
Führen Sie Prozesssimulationen durch, die absichtlich Fehler auslösen. Stellen Sie sicher, dass:
- Das Grenzereignis korrekt aktiviert wird.
- Der Prozess folgt dem Ausnahmepfad.
- Daten werden angemessen erhalten oder protokolliert.
- Der Prozess gerät nicht in eine endlose Schleife von Wiederholungsversuchen.
Codeabdeckung
Stellen Sie sicher, dass die Fehlerbehandlungslogik den erwarteten Bereich an Ausfall-Szenarien abdeckt. Dazu gehören:
- Probleme mit der Netzwerkverbindung.
- Ungültige Daten-Eingaben.
- Nichtverfügbarkeit externer APIs.
Häufige Fallen, die Sie vermeiden sollten ⚠️
Selbst erfahrene Modelleure machen Fehler bei der Implementierung von Fehlerereignissen. Die Aufmerksamkeit für häufige Probleme hilft dabei, ein robustes Modell aufrechtzuerhalten.
- Fehlende Fehlercodes:Das Auslassen der Definition des Fehlercodes in der Engine-Konfiguration führt zu stummen Fehlern.
- Unerreichbare Pfade:Erstellen von Fehlerpfaden, die aufgrund logischer Einschränkungen niemals erreicht werden können.
- Ignorieren von Protokollen:Ein Fehler wird erfasst, aber nichts wird damit gemacht. Der Fehler sollte immer eine Protokolleintragung oder Benachrichtigung auslösen.
- Komplexe Zusammenführungen:Zu viele Fehlerpfade werden ohne Unterscheidung der Fehlerursache in einem einzigen Gateway zusammengeführt.
Fazit zur Ausnahmendesign 🎓
Die Gestaltung von Fehlerereignissen erfordert ein Gleichgewicht zwischen technischer Präzision und operativer Pragmatik. Durch das Verständnis der spezifischen Ereignistypen, deren korrekte Konfiguration und die Einhaltung etablierter Best-Practices können Sie Prozesse entwickeln, die robust gegenüber Ausfällen sind.
Das Ziel ist nicht, Fehler zu eliminieren, was unmöglich ist, sondern sie effizient zu managen. Ein gut strukturiertes BPMN-Modell mit klarer Ausnahmehandhabung reduziert Ausfallzeiten, verbessert die Sichtbarkeit von Fehlern und stellt sicher, dass Geschäftsvorgänge schnell wiederhergestellt werden können. Konzentrieren Sie sich auf die spezifischen Anforderungen Ihrer Aufgaben, definieren Sie klare Codes und testen Sie die Fehlerpfade gründlich. Dieser Ansatz führt zu zuverlässigen Workflows, die der realen Komplexität standhalten.

