












Moderne Softwarebereitstellung beruht oft auf komplexen Systemen, die darauf ausgelegt sind, Code von Entwicklungs-Umgebungen in die Produktion zu überführen. Wenn diese Systeme ausfallen, kann die Auswirkung erheblich sein. Ein Bereitstellungsdiagramm dient als Bauplan für diese Infrastrukturen und zeigt Knoten, Artefakte und deren Wechselwirkungen auf. Ein Diagramm ist jedoch nur so nützlich wie seine Übereinstimmung mit der tatsächlich laufenden Umgebung. Treten Abweichungen auf, wird systematisches Troubleshooting unverzichtbar. Diese Anleitung untersucht, wie man Probleme innerhalb komplexer Bereitstellungsarchitekturen diagnostiziert und behebt, ohne sich auf spezifische Anbieter-Tools oder Produkte zu verlassen.
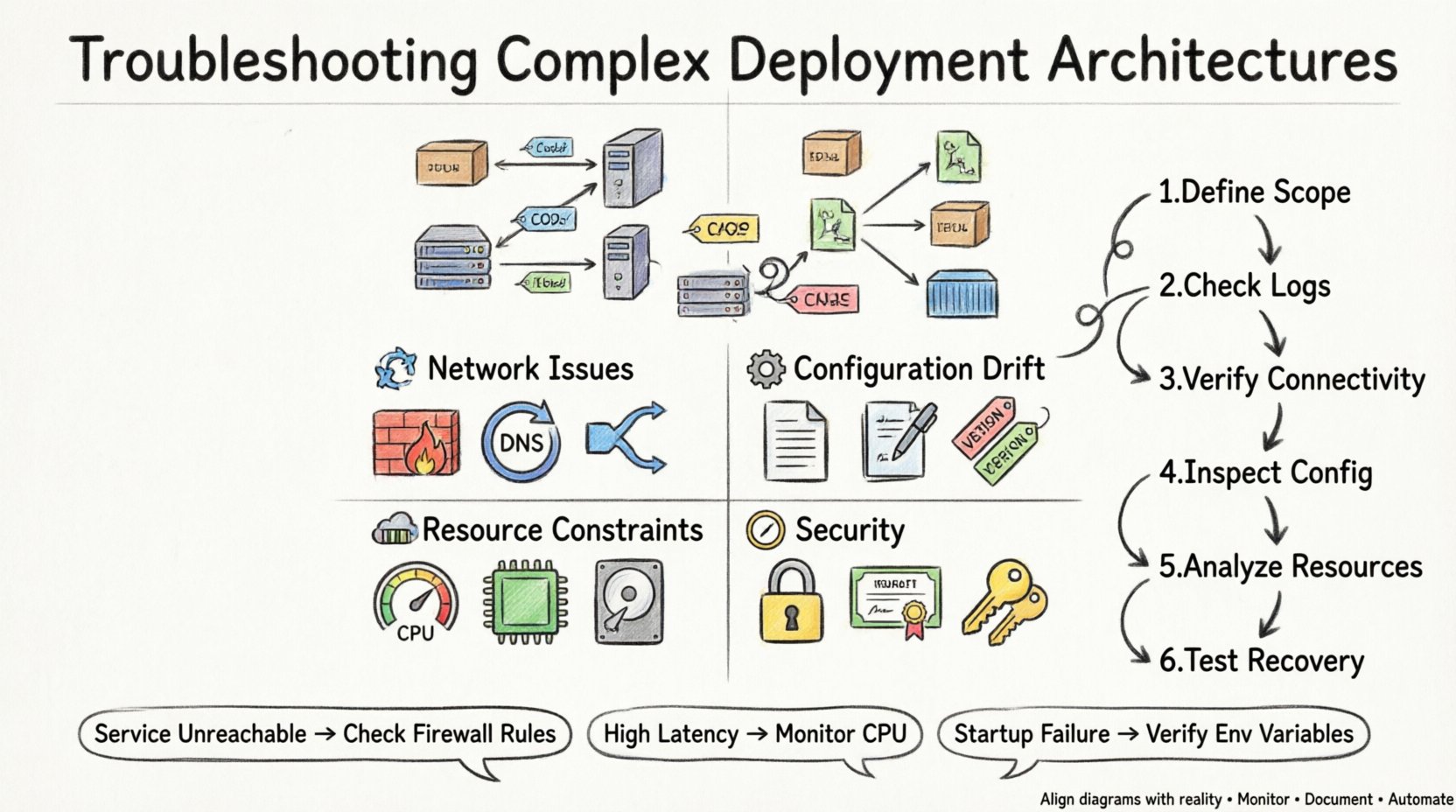
Verständnis des Bereitstellungsdiagramms 📐
Bevor man versucht, ein Problem zu beheben, muss man verstehen, was die Architektur darstellt. Ein Bereitstellungsdiagramm veranschaulicht die physische oder logische Struktur des Systems. Es beschreibt, wo sich Softwarekomponenten befinden und wie sie miteinander kommunizieren. Bei komplexen Aufbauten sind dies oft mehrere Abstraktionsebenen.
-
Knoten: Diese stellen die Rechenressourcen dar, auf denen Artefakte bereitgestellt werden. Es können physische Maschinen, virtuelle Instanzen oder Container sein.
-
Artefakte: Dies sind die Softwarepakete, die auf den Knoten installiert werden. Dazu gehören Binärdateien, Konfigurationsdateien und Bibliotheken.
-
Verbindungen: Diese definieren die Kommunikationspfade zwischen Knoten. Sie legen Protokolle, Ports und Datentypen fest.
-
Abhängigkeiten: Diese zeigen die Voraussetzungen an, die erforderlich sind, damit ein Knoten korrekt funktioniert.
Wenn ein Problem auftritt, ist der erste Schritt, das Diagramm mit dem aktuellen Zustand der Infrastruktur zu vergleichen. Abweichungen hier sind oft die Ursache für Ausfälle.
Häufige Ausfallarten ⚠️
Komplexe Architekturen führen zu mehreren Ausfallpunkten. Das Verständnis der typischen Ausfallarten hilft, die Untersuchung schnell einzugrenzen. Probleme fallen in der Regel in Kategorien, die mit der Konnektivität, Konfiguration, Ressourcen oder Sicherheit zusammenhängen.
1. Konnektivitäts- und Netzwerkprobleme 🌐
Netzwerkprobleme gehören zu den häufigsten Ursachen für Bereitstellungsfehler. Selbst wenn das Diagramm eine gültige Verbindung zeigt, könnte das Netzwerk den Datenverkehr blockieren.
-
Firewall-Regeln: Die für die Kommunikation erforderlichen Ports könnten durch Zwischen-Firewalls oder Sicherheitsgruppen geschlossen sein.
-
DNS-Auflösung: Dienste verlassen sich oft auf Domänennamen. Wenn die DNS-Konfiguration nicht korrekt ist, können Knoten sich nicht finden.
-
Subnetz-Konfiguration: Knoten in verschiedenen Netzsegmenten verfügen möglicherweise nicht über die erforderlichen Routing-Tabellen, um miteinander zu kommunizieren.
-
Lastverteilung: Die Logik zur Verteilung des Datenverkehrs könnte falsch konfiguriert sein und Anfragen an nicht funktionierende Knoten senden.
2. Konfigurationsabweichung ⚙️
Konfigurationsabweichung tritt auf, wenn der tatsächliche Zustand eines Knotens von dem im Bereitstellungsplan definierten Zustand abweicht. Dies geschieht oft, wenn manuelle Änderungen direkt in einer Produktionsumgebung vorgenommen werden.
-
Umgebungsvariablen:Fehlende oder falsche Variablen können dazu führen, dass Dienste nicht starten oder unerwartet reagieren.
-
Dateiberechtigungen: Falsche Berechtigungen in Konfigurationsdateien können verhindern, dass die Anwendung notwendige Daten lesen kann.
-
Versionsunterschiede: Bibliotheken oder Abhängigkeiten, die auf dem Knoten installiert sind, stimmen möglicherweise nicht mit der in dem Artefakt angegebenen Version überein.
3. Ressourcenbeschränkungen 💾
Selbst eine perfekt konfigurierte Architektur wird fehlschlagen, wenn die zugrundeliegende Hardware die Last nicht bewältigen kann. Ressourcenerschöpfung ist ein stiller Killer der Bereitstellungszuverlässigkeit.
-
CPU-Auslastung: Hohe Auslastung kann zu Latenz oder Dienstzeitüberschreitungen führen.
-
Speicherlecks: Anwendungen, die Speicher nicht ordnungsgemäß freigeben, können dazu führen, dass der Host keinen RAM mehr zur Verfügung hat.
-
Festplattenspeicher: Protokolle und temporäre Dateien können Speicherplatz ausfüllen und verhindern, dass neue Daten geschrieben werden.
-
Netzwerkbandbreite: Unzureichende Durchsatzkapazität kann zu Datenübertragungsfehlern zwischen Knoten führen.
4. Sicherheit und Berechtigungen 🔒
Sicherheitsprotokolle sind entscheidend zum Schutz von Daten, können aber auch legitime Datenverkehr blockieren, wenn sie zu streng konfiguriert sind.
-
Identitäts- und Zugriffsmanagement: Dienstkonten könnten die Berechtigungen fehlen, um auf andere Ressourcen zuzugreifen.
-
Zertifikatsüberprüfung:Abgelaufene oder selbstsignierte SSL/TLS-Zertifikate können verschlüsselte Verbindungen stören.
-
Authentifizierungstoken:Abgelaufene oder ungültige Token können verhindern, dass Dienste miteinander authentifiziert werden.
Diagnosemethodik 🔍
Beim Beheben von Problemen verhindert ein strukturierter Ansatz verschwendete Zeit. Folgen Sie diesen Schritten, um das Problem effizient zu isolieren.
-
Definieren Sie den Umfang: Bestimmen Sie genau, welter Teil der Architektur ausfällt. Ist es das gesamte System, ein bestimmter Knoten oder eine bestimmte Verbindung?
-
Überprüfen Sie die Protokolle: Überprüfen Sie Anwendungs- und Systemprotokolle auf Fehlermeldungen. Suchen Sie nach Zeitstempeln, die mit dem Ausfallereignis übereinstimmen.
-
Überprüfen Sie die Verbindung: Verwenden Sie Netzwerkwerkzeuge, um die Erreichbarkeit zwischen Knoten zu testen. Überprüfen Sie, ob die Ports offen sind und antworten.
-
Überprüfen Sie die Konfiguration: Vergleichen Sie die aktuelle Konfiguration mit der in der Bereitstellungsdarstellung definierten Baseline.
-
Ressourcennutzung analysieren:Überwachen Sie die CPU-, Speicher- und Festplattennutzung während des Ausfallzeitraums.
-
Recovery-Test:Versuchen Sie, Dienste neu zu starten oder Änderungen rückgängig zu machen, um zu prüfen, ob das Problem behoben wird.
Tabelle: Häufige Symptome im Vergleich zu Diagnosemaßnahmen 📋
Diese Tabelle fasst häufige Symptome und die entsprechenden Maßnahmen zur Diagnose zusammen.
|
Symptom |
Mögliche Ursache |
Diagnosemaßnahme |
|---|---|---|
|
Dienst nicht erreichbar |
Netzwerk-Firewall |
Sicherheitsgruppen und Firewall-Regeln überprüfen |
|
Hohe Latenz |
CPU-Auslastung |
CPU-Auslastungs-Metriken überwachen |
|
Startfehler |
Fehlende Konfiguration |
Umweltvariablen und Dateien überprüfen |
|
Verbindung zurückgesetzt |
Ressourcenerschöpfung |
Speicher- und Festplattennutzung überprüfen |
|
Authentifizierungsfehler |
Zertifikatsablauf |
Gültigkeit des SSL/TLS-Zertifikats überprüfen |
|
Pipeline stecken geblieben |
Abhängigkeitszeitüberschreitung |
Netzwerkverbindung zu externen Repos überprüfen |
Tiefgang: Netzwerkdiagnostics 🌐
Netzwerkprobleme sind besonders schwierig, da sie oft intermittierend auftreten. Wenn eine Bereitstellungsdarstellung eine Verbindung zwischen Knoten A und Knoten B zeigt, aber kein Datenverkehr fließt, müssen Sie den Pfad untersuchen.
1. Verfolgen der Route
Verwenden Sie Netzwerkverfolgungstools, um festzustellen, wo Pakete verloren gehen. Dies hilft dabei festzustellen, ob das Problem innerhalb des lokalen Netzwerks, über das Internet oder am Zielknoten liegt.
-
Paketabfangen:Analysieren Sie den Datenverkehr an Quelle und Ziel, um festzustellen, ob Pakete gesendet und empfangen werden.
-
Routing-Tabellen:Stellen Sie sicher, dass Knoten wissen, wie sie den Datenverkehr zueinander routen.
-
MTU-Einstellungen:Unterschiede in den Maximalübertragungseinheiten können zu Paketfragmentierung und Verlust führen.
2. DNS und Dienstentdeckung
Viele moderne Architekturen setzen auf Dienstentdeckungsmechanismen statt auf festgelegte IP-Adressen. Wenn der Entdeckungsdienst ausgefallen ist, können Knoten sich nicht mehr finden.
-
Datensatzüberprüfung:Stellen Sie sicher, dass DNS-Datensätze auf die richtigen IP-Adressen verweisen.
-
Cache-Probleme:DNS-Caching kann zu veralteten Daten führen. Leeren Sie die DNS-Caches, falls erforderlich.
-
Intern vs. Extern:Unterscheiden Sie zwischen internen Dienstnamen und externen Domänennamen.
Tiefgang: Konfigurationsmanagement ⚙️
Das Konfigurationsmanagement stellt sicher, dass alle Knoten in der Architektur in einem bekannten Zustand sind. Wenn dieser Prozess fehlschlägt, wird die Bereitstellung instabil.
1. Infrastruktur als Code
Die Definition von Infrastruktur mittels Code ermöglicht Versionskontrolle und Wiederholbarkeit. Allerdings können Syntaxfehler oder logische Fehler im Code Bereitstellungsfehler verursachen.
-
Validierung:Führen Sie Syntaxprüfungen durch, bevor Änderungen angewendet werden.
-
Statusdateien:Stellen Sie sicher, dass die Statusdatei die aktuelle Infrastruktur genau widerspiegelt.
-
Erkennung von Abweichungen:Implementieren Sie Werkzeuge, um festzustellen, wann manuelle Änderungen vorgenommen werden.
2. Geheimnisverwaltung
Sensible Daten wie Passwörter und API-Schlüssel müssen sicher gespeichert werden. Eine unsachgemäße Handhabung kann zu Sicherheitsverletzungen oder Bereitstellungsfehlern führen.
-
Verschlüsselung:Stellen Sie sicher, dass Geheimnisse ruhend und im Transport verschlüsselt sind.
-
Rotation: Rotieren Sie Zertifikate regelmäßig, um das Risiko zu minimieren.
-
Zugriffssteuerung: Beschränken Sie den Zugriff auf Geheimnisse auf nur die notwendigen Dienste.
Tiefgang: Ressourcenverwaltung 💾
Ressourcenbeschränkungen treten oft während der Spitzenzeiten auf. Die Planung der Kapazität ist entscheidend, um Ausfälle zu vermeiden.
1. Skalierungsstrategien
Architekturen sollten so gestaltet werden, dass sie je nach Bedarf horizontal oder vertikal skaliert werden können. Wenn die Skalierung fehlschlägt, kann das System unempfindlich werden.
-
Horizontale Skalierung: Fügen Sie mehr Instanzen hinzu, um erhöhte Last zu bewältigen.
-
Vertikale Skalierung: Erhöhen Sie die Ressourcen bestehender Instanzen.
-
Automatische Skalierung: Konfigurieren Sie Regeln, um Ressourcen automatisch basierend auf Metriken anzupassen.
2. Überwachung und Benachrichtigungen
Proaktive Überwachung hilft, Ressourcenprobleme zu erkennen, bevor sie zu Ausfällen führen.
-
Schwellenwerte: Legen Sie Warnungen für CPU-, Speicher- und Festplattennutzung fest.
-
Protokolle: Sammeln Sie Protokolle von allen Knoten für eine zentrale Analyse.
-
Nachverfolgung: Verwenden Sie verteilte Nachverfolgung, um Anfragen über Dienste hinweg zu verfolgen.
Tiefgang: Sicherheit und Berechtigungen 🔒
Sicherheit ist kein Nachtrag; sie muss in den Bereitstellungsprozess integriert werden.
1. Minimale Berechtigungen
Dienste sollten nur die Berechtigungen haben, die für ihre Funktion erforderlich sind. Zu viele Berechtigungen erhöhen die Angriffsfläche.
-
Rollen: Definieren Sie spezifische Rollen für verschiedene Dienste.
-
Richtlinien: Wenden Sie Richtlinien an, die den Zugriff auf bestimmte Ressourcen einschränken.
-
Prüfung: Überprüfen Sie regelmäßig die Berechtigungen, um die Einhaltung sicherzustellen.
2. Netzwerksicherheit
Netzwerksegmentierung begrenzt den Schadensradius eines möglichen Verstoßes.
-
VLANs: Trennen Sie den Datenverkehr nach Funktion oder Umgebung.
-
Firewalls: Blockieren Sie unerlaubten Datenverkehr am Netzwerkrand.
-
Verschlüsselung: Verschlüsseln Sie alle Daten, die zwischen Knoten übertragen werden.
Integrität der Pipeline und Automatisierung 🔄
Die Pipeline, die Code von der Entwicklung in die Produktion bewegt, ist eine entscheidende Komponente der Bereitstellungsarchitektur. Wenn die Pipeline ausfällt, erreicht kein Code die Umgebung.
1. Stufen der Pipeline
Teilen Sie die Pipeline in unterschiedliche Stufen auf, um Ausfälle zu isolieren.
-
Build: Kompilieren Sie den Code und erstellen Sie Artefakte.
-
Test: Führen Sie automatisierte Tests durch, um die Funktionalität zu überprüfen.
-
Bereitstellen: Stellen Sie Artefakte in die Zielumgebung bereit.
-
Überprüfen: Führen Sie Überprüfungen nach der Bereitstellung durch.
2. Rollback-Verfahren
Wenn eine Bereitstellung fehlschlägt, minimiert ein schneller Rollback die Ausfallzeit.
-
Versionsverwaltung: Halten Sie frühere Versionen von Artefakten verfügbar.
-
Automatisierung: Automatisieren Sie den Rollback-Prozess, um menschliche Fehler zu reduzieren.
-
Testen: Testen Sie die Rollback-Verfahren regelmäßig, um sicherzustellen, dass sie funktionieren.
Beobachtbarkeit und Protokolle 🔍
Beobachtbarkeit bietet Einblicke in den internen Zustand des Systems. Ohne sie ist das Troubleshooting reine Vermutung.
1. Zentralisiertes Protokollieren
Sammeln Sie Protokolle von allen Knoten an einem zentralen Ort für eine einfachere Analyse.
-
Aggregation:Verwenden Sie einen Protokollaggregator, um Daten zu sammeln.
-
Indizierung:Indizieren Sie Protokolle für eine schnelle Suche.
-
Aufbewahrung:Definieren Sie Aufbewahrungsrichtlinien zur Speicherverwaltung.
2. Metriken und Dashboards
Visualisieren Sie Schlüsselmetriken, um Anomalien schnell zu erkennen.
-
Wichtige Metriken:Verfolgen Sie Anfrageraten, Fehlerquoten und Latenz.
-
Benachrichtigungen:Richten Sie Benachrichtigungen für Metriken-Schwellenwerte ein.
-
Visualisierung:Verwenden Sie Dashboards, um Daten über die Zeit darzustellen.
Vorfalldokumentation und Wiederherstellung 🚨
Auch bei bester Planung treten Vorfälle auf. Eine Reaktionsplanung stellt eine schnelle Wiederherstellung sicher.
1. Klassifizierung von Vorfällen
Klassifizieren Sie Vorfälle basierend auf Schweregrad und Auswirkung.
-
Kritisch:Das System ist ausgefallen oder Daten sind beschädigt.
-
Hoch:Erhebliche Verschlechterung des Dienstes.
-
Mittel:Geringfügige Probleme, die eine Teilmenge von Benutzern betreffen.
-
Niedrig:Ästhetische oder nicht dringende Probleme.
2. Kommunikation
Halten Sie die Beteiligten während des Vorfalls stets auf dem Laufenden.
-
Status-Updates:Stellen Sie regelmäßige Updates zum Fortschritt bereit.
-
Nachbesprechung:Analysieren Sie den Vorfall nach der Behebung.
-
Maßnahmen:Weisen Sie Aufgaben zu, um eine Wiederholung zu verhindern.
Dokumentation und Versionskontrolle 📝
Dokumentation stellt sicher, dass Wissen erhalten und geteilt wird. Die Versionskontrolle stellt sicher, dass Änderungen verfolgt werden.
1. Architekturdokumentation
Halten Sie die Bereitstellungsdiagramme aktuell.
-
Änderungen:Dokumentieren Sie jede Änderung an der Architektur.
-
Abhängigkeiten:Listen Sie alle externen und internen Abhängigkeiten auf.
-
Verfahren:Dokumentieren Sie Standardarbeitsabläufe.
2. Änderungsmanagement
Steuern Sie, wie Änderungen an der Umgebung vorgenommen werden.
-
Überprüfung:Erfordern Sie Überprüfungen für wesentliche Änderungen.
-
Genehmigung:Holen Sie die Genehmigung ein, bevor Änderungen angewendet werden.
-
Verfolgung:Verfolgen Sie alle Änderungen in einem System.
Abschließende Überlegungen zur Bereitstellungsintegrität 🏥
Die Aufrechterhaltung einer gesunden Bereitstellungsarchitektur erfordert kontinuierliche Anstrengungen. Regelmäßige Überprüfungen und Aktualisierungen sind notwendig, um mit sich ändernden Anforderungen Schritt zu halten. Konzentrieren Sie sich auf die folgenden Bereiche, um langfristige Stabilität zu gewährleisten.
-
Regelmäßige Audits:Führen Sie periodische Audits der Architektur durch.
-
Capacitätsplanung: Planen Sie für zukünftiges Wachstum.
-
Schulung: Schulen Sie das Team in Fehlerbehebungsmethoden.
-
Automatisierung: Automatisieren Sie wiederholbare Aufgaben, um menschliche Fehler zu reduzieren.
-
Testen: Testen Sie die Architektur regelmäßig in einer Staging-Umgebung.
Durch die Einhaltung eines strukturierten Ansatzes zur Fehlerbehebung können Teams Probleme schneller lösen und Ausfallzeiten reduzieren. Das Ziel ist nicht nur, Probleme zu beheben, sondern ein System zu schaffen, das widerstandsfähig und leicht wartbar ist. Bereitstellungsdokumente sind lebendige Dokumente, die sich mit der Infrastruktur weiterentwickeln sollten. Wenn dies geschieht, bleibt die Architektur mit den geschäftlichen Anforderungen synchronisiert.
Denken Sie daran, dass jeder Ausfall eine Gelegenheit zum Lernen ist. Die Dokumentation der Ursache und der Lösung hilft, ähnliche Probleme in Zukunft zu vermeiden. Diese Wissensbasis wird zu einem wertvollen Gut für die gesamte Organisation.

