












La entrega moderna de software a menudo depende de sistemas intrincados diseñados para mover código desde entornos de desarrollo hasta producción. Cuando estos sistemas fallan, el impacto puede ser significativo. Un diagrama de despliegue sirve como plano para estas infraestructuras, representando nodos, artefactos y sus interacciones. Sin embargo, un diagrama solo es tan útil como su alineación con el entorno en ejecución real. Cuando surgen discrepancias, la solución sistemática de problemas se vuelve esencial. Esta guía explora cómo diagnosticar y resolver problemas dentro de arquitecturas de despliegue complejas sin depender de herramientas o productos específicos de proveedores.
Comprendiendo el diagrama de despliegue 📐
Antes de intentar solucionar un problema, uno debe comprender qué representa la arquitectura. Un diagrama de despliegue ilustra la estructura física o lógica del sistema. Detalla dónde residen los componentes de software y cómo se comunican. En configuraciones complejas, esto a menudo implica múltiples capas de abstracción.
-
Nodos: Estos representan los recursos informáticos donde se despliegan los artefactos. Pueden ser máquinas físicas, instancias virtuales o contenedores.
-
Artefactos: Son los paquetes de software que se instalan en los nodos. Incluyen archivos binarios, archivos de configuración y bibliotecas.
-
Conexiones: Definen las rutas de comunicación entre nodos. Especifican protocolos, puertos y tipos de datos.
-
Dependencias: Muestran los requisitos previos necesarios para que un nodo funcione correctamente.
Cuando ocurre un problema, el primer paso es comparar el diagrama con el estado actual de la infraestructura. Las discrepancias aquí suelen ser la causa raíz de los fallos.
Modos comunes de fallo ⚠️
Las arquitecturas complejas introducen múltiples puntos de fallo. Comprender los modos comunes de fallo ayuda a reducir rápidamente la investigación. Los problemas generalmente se clasifican en categorías relacionadas con conectividad, configuración, recursos o seguridad.
1. Problemas de conectividad y red 🌐
Los problemas de red son entre las causas más frecuentes de fallo en el despliegue. Aunque el diagrama muestre una conexión válida, la red podría bloquear el tráfico.
-
Reglas de firewall: Los puertos necesarios para la comunicación podrían estar cerrados por firewalls intermedios o grupos de seguridad.
-
Resolución de DNS: Los servicios dependen a menudo de nombres de dominio. Si el DNS no está configurado correctamente, los nodos no pueden localizarse entre sí.
-
Configuración de subred: Los nodos en segmentos de red diferentes podrían no tener las tablas de enrutamiento necesarias para comunicarse.
-
Balanceadores de carga: La lógica de distribución del tráfico podría estar mal configurada, enviando solicitudes a nodos no saludables.
2. Desviación de configuración ⚙️
La desviación de configuración ocurre cuando el estado real de un nodo diverge del estado previsto definido en el plan de despliegue. Esto suele ocurrir cuando se realizan cambios manuales directamente en un entorno de producción.
-
Variables de entorno: Las variables faltantes o incorrectas pueden hacer que los servicios no arranquen o se comporten de forma inesperada.
-
Permisos de archivos: Los permisos incorrectos en los archivos de configuración pueden impedir que la aplicación lea los datos necesarios.
-
Errores de versión: Las bibliotecas o dependencias instaladas en el nodo pueden no coincidir con la versión especificada en el artefacto.
3. Limitaciones de recursos 💾
Incluso una arquitectura perfectamente configurada fallará si el hardware subyacente no puede soportar la carga. La agotamiento de recursos es un asesino silencioso de la confiabilidad de la implementación.
-
Saturación de la CPU: Una alta utilización puede provocar latencia o tiempo de espera del servicio.
-
Fugas de memoria: Las aplicaciones que no liberan la memoria correctamente pueden hacer que el host se quede sin RAM.
-
Espacio en disco: Los registros y archivos temporales pueden llenar el almacenamiento, impidiendo que se escriba nueva data.
-
Ancho de banda de red: Un ancho de banda insuficiente puede causar fallas en la transferencia de datos entre nodos.
4. Seguridad y permisos 🔒
Los protocolos de seguridad son críticos para proteger los datos, pero también pueden bloquear tráfico legítimo si se configuran de forma demasiado restrictiva.
-
Gestión de identidad y acceso: Las cuentas de servicio podrían carecer de los permisos necesarios para acceder a otros recursos.
-
Validación de certificados: Los certificados SSL/TLS caducados o autofirmados pueden romper las conexiones cifradas.
-
Tokens de autenticación: Los tokens caducados o inválidos pueden impedir que los servicios se autentiquen entre sí.
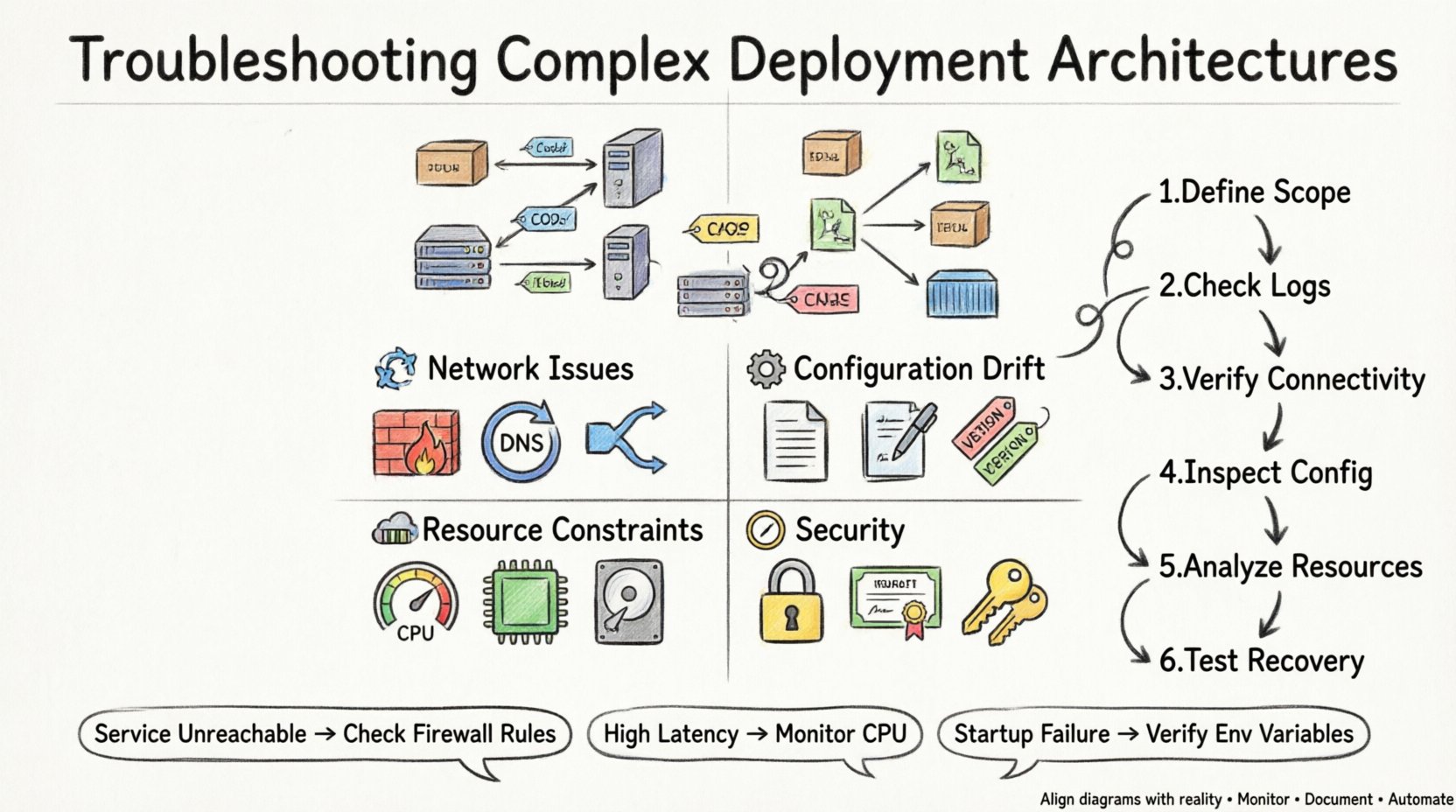
Metodología de diagnóstico 🔍
Al solucionar problemas, un enfoque estructurado evita el desperdicio de tiempo. Siga estos pasos para aislar el problema de forma eficiente.
-
Defina el alcance: Determine exactamente qué parte de la arquitectura está fallando. ¿Es todo el sistema, un nodo específico o una conexión específica?
-
Revise los registros: Revise los registros de la aplicación y del sistema en busca de mensajes de error. Busque marcas de tiempo que coincidan con el evento de falla.
-
Verifique la conectividad: Utilice herramientas de red para probar la accesibilidad entre nodos. Verifique si los puertos están abiertos y respondiendo.
-
Inspeccione la configuración:Compare la configuración actual con la línea base definida en el diagrama de despliegue.
-
Analizar el uso de recursos:Monitoree el uso de CPU, memoria y disco durante la ventana de fallo.
-
Probar la recuperación:Intente reiniciar los servicios o deshacer los cambios para ver si se resuelve el problema.
Tabla: Síntomas comunes frente a acciones de diagnóstico 📋
Esta tabla resume los síntomas frecuentes y las acciones correspondientes necesarias para diagnosticarlos.
|
Síntoma |
Causa potencial |
Acción de diagnóstico |
|---|---|---|
|
Servicio inaccesible |
Firewall de red |
Verifique los grupos de seguridad y las reglas del firewall |
|
Alta latencia |
Saturación de CPU |
Monitoree las métricas de utilización de CPU |
|
Fallo en el arranque |
Configuración faltante |
Verifique las variables de entorno y los archivos |
|
Conexión reiniciada |
Agotamiento de recursos |
Verifique el uso de memoria y espacio en disco |
|
Error de autenticación |
Caducidad del certificado |
Inspeccione la validez del certificado SSL/TLS |
|
Pipeline atascado |
Tiempo de espera agotado para dependencias |
Revise la conectividad de red con los repositorios externos |
Análisis profundo: Diagnóstico de red 🌐
Los problemas de red son especialmente complicados porque a menudo aparecen intermitentes. Cuando un diagrama de despliegue muestra una conexión entre el Nodo A y el Nodo B, pero el tráfico no fluye, debe investigar el camino.
1. Rastreando la ruta
Utilice herramientas de trazado de red para identificar dónde se pierden los paquetes. Esto ayuda a determinar si el problema radica en la red local, a través de internet o en el nodo de destino.
-
Captura de paquetes:Analice el tráfico en la fuente y el destino para ver si los paquetes se envían y reciben.
-
Tablas de enrutamiento:Verifique que los nodos sepan cómo enrutar el tráfico entre sí.
-
Configuración de MTU:Las incompatibilidades en la unidad de transmisión máxima pueden causar fragmentación y pérdida de paquetes.
2. DNS y descubrimiento de servicios
Muchas arquitecturas modernas dependen de mecanismos de descubrimiento de servicios en lugar de direcciones IP codificadas. Si el servicio de descubrimiento está caído, los nodos no pueden encontrarse entre sí.
-
Validación de registros:Asegúrese de que los registros DNS apunten a las direcciones IP correctas.
-
Problemas de caché:La caché de DNS puede provocar datos obsoletos. Vacíe las cachés de DNS si es necesario.
-
Interno frente a externo:Distinga entre nombres de servicios internos y nombres de dominios externos.
Análisis profundo: Gestión de configuración ⚙️
La gestión de configuración asegura que todos los nodos en la arquitectura se encuentren en un estado conocido. Cuando este proceso falla, la implementación se vuelve inestable.
1. Infraestructura como código
Definir la infraestructura mediante código permite el control de versiones y la reproducibilidad. Sin embargo, errores de sintaxis o fallos lógicos en el código pueden causar fallas en la implementación.
-
Validación:Ejecute comprobaciones de sintaxis antes de aplicar cambios.
-
Archivos de estado:Asegúrese de que el archivo de estado refleje con precisión la infraestructura actual.
-
Detección de desviación:Implemente herramientas para detectar cuándo ocurren cambios manuales.
2. Gestión de secretos
Los datos sensibles, como contraseñas y claves de API, deben almacenarse de forma segura. Su manejo inadecuado puede provocar brechas de seguridad o fallas en la implementación.
-
Cifrado:Asegúrese de que los secretos estén cifrados en reposo y en tránsito.
-
Rotación: Gire regularmente las credenciales para minimizar el riesgo.
-
Control de acceso: Limitar el acceso a secretos solo a los servicios necesarios.
Análisis profundo: Gestión de recursos 💾
Las limitaciones de recursos a menudo se manifiestan durante los momentos de mayor uso. Planificar la capacidad es esencial para evitar interrupciones.
1. Estrategias de escalado
Las arquitecturas deben diseñarse para escalar horizontal o verticalmente según la demanda. Si el escalado falla, el sistema podría volverse inaccesible.
-
Escalado horizontal: Agregue más instancias para manejar la carga aumentada.
-
Escalado vertical: Aumente los recursos de las instancias existentes.
-
Escalado automático: Configure reglas para ajustar automáticamente los recursos según métricas.
2. Monitoreo y alertas
El monitoreo proactivo ayuda a identificar problemas de recursos antes de que causen fallas.
-
Límites: Establezca alertas para el uso de CPU, memoria y disco.
-
Registros: Agregue registros de todos los nodos para un análisis centralizado.
-
Rastreo: Utilice el rastreo distribuido para rastrear solicitudes entre servicios.
Análisis profundo: Seguridad y permisos 🔒
La seguridad no es una consideración posterior; debe integrarse en el proceso de despliegue.
1. Menor privilegio
Los servicios solo deben tener los permisos necesarios para funcionar. Los servicios con permisos excesivos aumentan la superficie de ataque.
-
Roles: Defina roles específicos para diferentes servicios.
-
Políticas: Aplicar políticas que restringen el acceso a recursos específicos.
-
Auditoría:Audite periódicamente los permisos para garantizar el cumplimiento.
2. Seguridad de red
La segmentación de red limita el radio de propagación de una posible brecha.
-
VLANs:Separe el tráfico por función o entorno.
-
Firewalls:Bloquee el tráfico no autorizado en el borde de la red.
-
Cifrado:Cifre todos los datos en tránsito entre nodos.
Integridad de la canalización y automatización 🔄
La canalización que mueve el código desde el desarrollo hasta la producción es un componente crítico de la arquitectura de despliegue. Si la canalización falla, ningún código llega al entorno.
1. Etapas de la canalización
Divida la canalización en etapas distintas para aislar los fallos.
-
Construcción:Compile el código y cree artefactos.
-
Prueba:Ejecute pruebas automatizadas para verificar la funcionalidad.
-
Despliegue:Envíe los artefactos al entorno objetivo.
-
Verifique:Realice comprobaciones posteriores al despliegue.
2. Procedimientos de reintegración
Cuando un despliegue falla, una reintegración rápida minimiza el tiempo de inactividad.
-
Gestión de versiones:Mantenga disponibles las versiones anteriores de los artefactos.
-
Automatización:Automatice el proceso de reintegración para reducir los errores humanos.
-
Pruebas:Pruebe periódicamente los procedimientos de reintegración para asegurarse de que funcionan.
Observabilidad y registros 🔍
La observabilidad proporciona visibilidad sobre el estado interno del sistema. Sin ella, el diagnóstico de problemas es una conjetura.
1. Registro centralizado
Recopila registros de todos los nodos en una ubicación central para un análisis más fácil.
-
Agregación:Utiliza un agregador de registros para recopilar datos.
-
Indexación:Indexa los registros para una búsqueda rápida.
-
Retención:Define políticas de retención para gestionar el almacenamiento.
2. Métricas y paneles
Visualiza indicadores clave de desempeño para detectar anomalías rápidamente.
-
Métricas clave:Monitorea las tasas de solicitudes, tasas de errores y latencia.
-
Alertas:Configura alertas para umbrales de métricas.
-
Visualización:Utiliza paneles para mostrar datos a lo largo del tiempo.
Respuesta a incidentes y recuperación 🚨
Aunque se planifique lo mejor posible, los incidentes ocurrirán. Contar con un plan de respuesta garantiza una recuperación rápida.
1. Clasificación de incidentes
Clasifica los incidentes según su gravedad e impacto.
-
Crítico:El sistema está fuera de servicio o los datos están comprometidos.
-
Alto:Degradación significativa del servicio.
-
Medio:Problemas menores que afectan a un subconjunto de usuarios.
-
Bajo:Problemas estéticos o no urgentes.
2. Comunicación
Mantenga a los interesados informados durante todo el incidente.
-
Actualizaciones de estado: Proporcione actualizaciones regulares sobre el progreso.
-
Análisis posterior: Analice el incidente después de su resolución.
-
Tareas pendientes: Asigne tareas para prevenir su repetición.
Documentación y control de versiones 📝
La documentación garantiza que el conocimiento se conserve y comparta. El control de versiones garantiza que los cambios se rastreen.
1. Documentación de la arquitectura
Mantenga el diagrama de despliegue actualizado.
-
Cambios:Documente cada cambio en la arquitectura.
-
Dependencias: Liste todas las dependencias externas e internas.
-
Procedimientos:Documente los procedimientos operativos estándar.
2. Gestión de cambios
Controle cómo se realizan los cambios en el entorno.
-
Revisión: Exija revisiones para cambios importantes.
-
Aprobación: Obtenga aprobación antes de aplicar cambios.
-
Seguimiento: Siga todos los cambios en un sistema.
Consideraciones finales para la salud del despliegue 🏥
Mantener una arquitectura de despliegue saludable requiere esfuerzo continuo. Son necesarias revisiones y actualizaciones regulares para mantenerse al día con los requisitos cambiantes. Enfóquese en las siguientes áreas para garantizar una estabilidad a largo plazo.
-
Auditorías regulares: Realice auditorías periódicas de la arquitectura.
-
Planificación de capacidad:Planificar el crecimiento futuro.
-
Capacitación:Capacitar al equipo en metodologías de resolución de problemas.
-
Automatización:Automatizar tareas repetitivas para reducir errores humanos.
-
Pruebas:Probar la arquitectura con regularidad en un entorno de preproducción.
Al seguir un enfoque estructurado para la resolución de problemas, los equipos pueden resolver incidencias más rápido y reducir el tiempo de inactividad. El objetivo no es solo solucionar problemas, sino construir un sistema resiliente y fácil de mantener. Los diagramas de despliegue son documentos vivos que deben evolucionar junto con la infraestructura. Cuando lo hacen, la arquitectura permanece alineada con las necesidades del negocio.
Recuerda que cada falla es una oportunidad para aprender. Documentar la causa raíz y la solución ayuda a prevenir problemas similares en el futuro. Esta base de conocimientos se convierte en un activo valioso para toda la organización.

