












En el mundo complejo del Modelo y Notación de Procesos de Negocio (BPMN), el flujo de control está diseñado para ser lineal y predecible. Sin embargo, las operaciones del mundo real rara vez son tan simples. Los sistemas fallan, la validación de datos se interrumpe y las dependencias externas se desconectan. Es aquí dondeeventos de errorse vuelven críticos. Proporcionan un mecanismo estandarizado dentro de la especificación BPMN para gestionar excepciones sin comprometer la integridad del modelo de proceso general.
Un manejo eficaz de excepciones no consiste en predecir cada fallo. Se trata de definir un camino claro cuando las cosas salen mal. Esta guía explora la mecánica, las configuraciones y la aplicación estratégica de los eventos de error para garantizar que sus flujos de trabajo permanezcan resilientes. Examinaremos cómo distinguir entre diferentes tipos de desencadenantes de error, configurar correctamente los códigos de error y mantener un diseño de proceso limpio.
Comprendiendo el concepto fundamental de los eventos de error ⚙️
Un evento de error es un tipo específico de evento que se activa por una condición de fallo dentro del proceso o el entorno. A diferencia de los eventos de mensaje, que dependen de la comunicación externa, o de los eventos de señal, que se transmiten a todo el motor, los eventos de error están estrechamente acoplados con el flujo de ejecución de una tarea o actividad específica.
Cuando una instancia de proceso encuentra un problema, el motor necesita saber hacia dónde desviar la ejecución. Los eventos de error actúan como señales de este desvío. Permiten al modelo separar el camino feliz (ejecución normal) del camino desafortunado (manejo de excepciones).
Las características clave incluyen:
- Especificidad:Normalmente se adjuntan a tareas que se sabe que son propensas a fallar.
- Propagación:Pueden propagarse hacia arriba en la jerarquía si no se capturan localmente.
- Estandarización:Siguen la especificación BPMN 2.0 para garantizar la interoperabilidad.
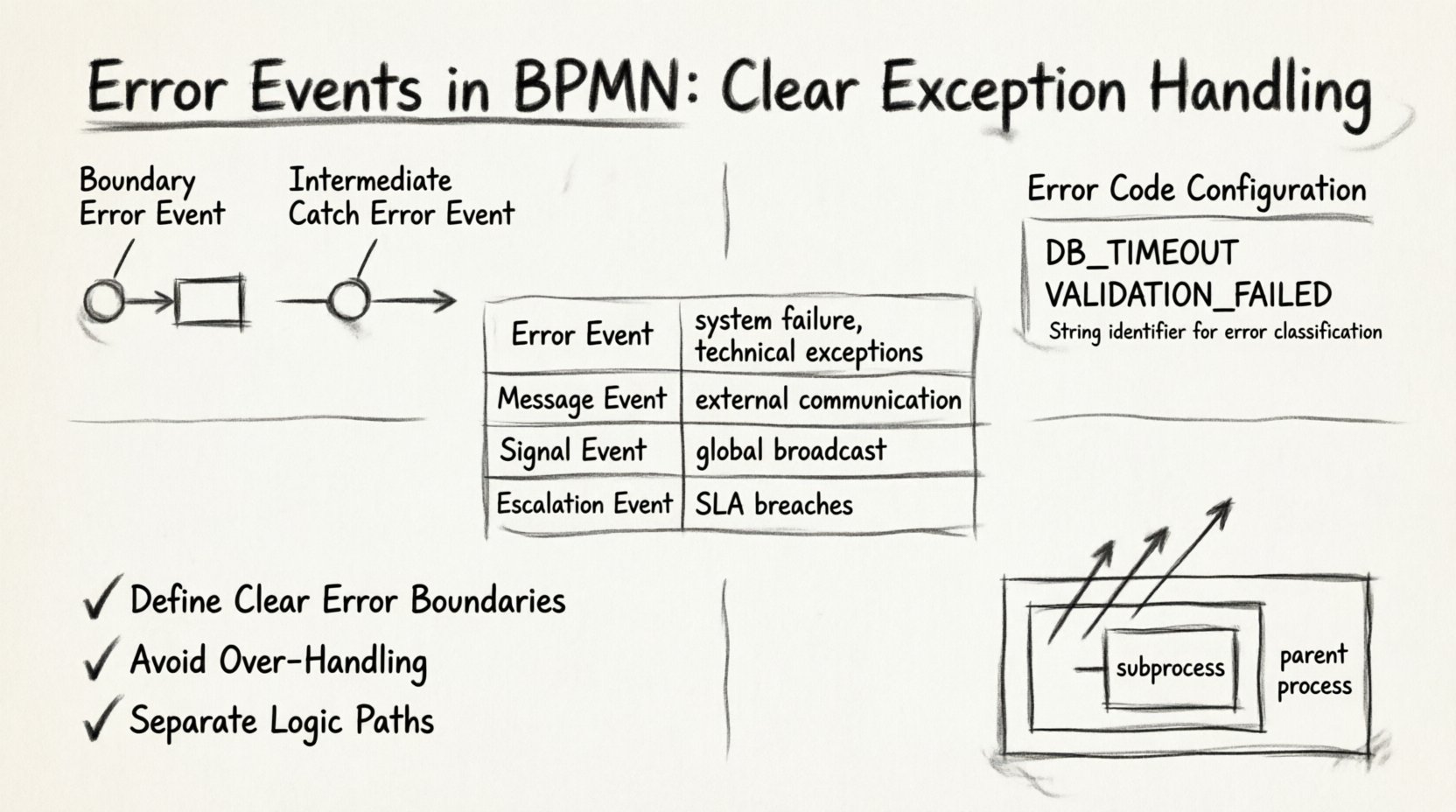
Tipos de eventos de error en BPMN 📋
Existen dos formas principales de implementar el manejo de errores en un diagrama de flujo de trabajo. Elegir la adecuada depende de la granularidad del fallo que desee capturar.
1. Eventos de error de borde 🎯
Un evento de error de borde está directamente adjunto al borde de una tarea, subproceso o actividad de llamada. Representa un manejador de excepciones local. Si la tarea se ejecuta y lanza un error, el flujo se desvía inmediatamente hacia la ruta conectada al evento de borde.
Este es el patrón más común para manejar fallos específicos. Permite aislar el error dentro del ámbito de la actividad. Por ejemplo, si una operación de escritura en base de datos falla, un evento de borde puede capturar ese fallo específico sin detener toda la instancia del proceso.
Ventajas de los eventos de borde:
- Encapsulamiento:La lógica de manejo de excepciones se encuentra visualmente al lado de la tarea que protege.
- No bloqueante:La tarea principal continúa hasta que ocurre el error.
- Claridad:El diagrama muestra claramente qué tareas tienen mecanismos de respaldo.
2. Eventos de error de captura intermedia 🔄
Un evento de error de captura intermedia se sitúa en el flujo de secuencia, en lugar de estar adjunto al borde de una tarea. Este tipo es menos común, pero útil para manejar errores que ocurren entre tareas o dentro de un subproceso que necesita ser capturado en el ámbito del padre.
Este enfoque se utiliza a menudo cuando desea capturar errores que se propagan fuera de un subproceso pero aún no han alcanzado el límite del proceso principal. Permite una gestión centralizada de errores para un bloque específico de lógica.
Configuración y atributos ⚙️
Para que los eventos de error funcionen, requieren una configuración específica dentro de la herramienta de modelado y el motor de ejecución. Estas configuraciones definen qué constituye un error y cómo reacciona el sistema.
Definición del código de error
Cada evento de error debe tener un código únicoCódigo de error. Este es un identificador de cadena que distingue un tipo de error de otro. Sin un código definido, el motor no puede diferenciar entre un tiempo de espera de base de datos y un fallo de validación.
- Identificador de cadena:Utilice una convención de nombres consistente, como
DB_TIMEOUToVALIDATION_FAILED. - Granularidad:Evite códigos genéricos como
ERROR_1. Use identificadores descriptivos que ayuden en la depuración. - Asignación:Asegúrese de que el sistema externo o el script lance exactamente el código definido en el evento.
Asociación de mensaje
Algunas implementaciones permiten asociar un evento de error con una definición de mensaje específica. Esto vincula el error a un mensaje legible por humanos que puede mostrarse en una interfaz de usuario o registrarse.
- Retorno al usuario:Permite al sistema informar al usuario exactamente qué falló.
- Registro:Facilita que los sistemas automatizados de registro categoricen los incidentes por tipo de error.
Comparación de estrategias de manejo de errores 📊
Comprender dónde encajan los eventos de error en el contexto más amplio de BPMN es esencial. A continuación se presenta una comparación de tipos de eventos para aclarar cuándo usar un evento de error frente a otras opciones.
| Tipo de evento | Origen del desencadenamiento | Casos de uso típicos | Alcance |
|---|---|---|---|
| Evento de Error | Fallo del Sistema/Tarea | Excepciones técnicas, fallas de validación | Local o del Proceso |
| Evento de Mensaje | Comunicación Externa | Esperando una respuesta, recibiendo datos | Instancia del Proceso |
| Evento de Señal | Transmisión Global | Cancelando múltiples instancias, alertas a nivel del sistema | Global |
| Evento de Escalada | Reglas del Proceso | Incumplimientos de SLA, requisitos de intervención manual | Jerarquía del Proceso |
Diseñando para la Resiliencia: Mejores Prácticas 🛡️
Construir un modelo de proceso que maneje los errores de forma adecuada requiere un enfoque estratégico. No basta con colocar simplemente un evento en el diagrama; la lógica que lo rodea debe ser sólida.
1. Define límites claros de error
No capture errores que deberían terminar el proceso. Algunos fallos son irreversibles. Si un proceso no puede continuar sin datos específicos, capturar el error y reintentar indefinidamente genera un proceso fantasma. En su lugar, permita que el error suba hasta un nivel superior o finalice la instancia de forma limpia.
- Identifique tareas críticas: Determine cuáles tareas son esenciales para que el proceso funcione.
- Finalice ante errores fatales: Use eventos de error para indicar que el proceso no puede continuar.
- Vuelva a intentar en errores transitorios: Use eventos de borde para tiempos de espera de red o indisponibilidad temporal.
2. Evite el manejo excesivo
No todas las tareas necesitan un manejador de errores. Agregar eventos de borde a cada tarea individualmente ensucia el diagrama y dificulta la lectura del flujo. Solo asocie eventos de error a tareas que se sabe que fallan o tienen consecuencias importantes si lo hacen.
3. Separe las rutas de lógica
Asegúrese de que la ruta tomada después de un error sea distinta de la ruta normal. Si la ruta de error finalmente se vuelve a unir con el flujo principal, use una puerta exclusiva para fusionarlas de forma limpia. No mezcle la lógica de manejo de errores con la lógica de negocio.
Mapeo y propagación de datos 📡
Cuando ocurre un error, los datos a menudo se pierden a menos que se mapeen explícitamente. Una de las partes más pasadas por alto de los eventos de error es el manejo de variables.
Persistencia de datos de error
Cuando se captura una excepción, el sistema normalmente almacena información sobre el fallo. Esto podría incluir el código de error, la marca de tiempo y el estado de las variables en el momento del fallo.
- Captura de variables:Configure el motor para guardar el estado de las variables del proceso al ocurrir un error.
- Preservación del contexto:Asegúrese de que el manejador de errores tenga acceso a los datos que causaron el fallo.
Propagación de errores
Si un subproceso lanza un error y el subproceso no tiene un evento de borde para capturarlo, el error se propaga hacia el proceso principal. Esta es una característica crucial para el diseño jerárquico de procesos.
- Manejo por el padre:El proceso principal puede decidir cómo reaccionar ante un fallo del hijo.
- Recuperación global:Permite una estrategia centralizada de recuperación para un conjunto de tareas relacionadas.
Manejo de errores en tareas humanas 👤
Los modelos de proceso a menudo implican participantes humanos. Cuando una tarea humana falla, el evento de error se comporta ligeramente de forma diferente que una tarea del sistema.
- Abandono de tarea:Si un usuario abandona una tarea, esto puede desencadenar un evento de error.
- Tiempo de espera:Si una tarea no se completa dentro de un tiempo establecido, se puede desencadenar una escalada o un error.
- Reasignación:Los eventos de error pueden redirigir la tarea a un usuario o cola diferente si el asignado original falla.
Al diseñar para tareas humanas, la ruta de error a menudo implica un mecanismo de notificación. Esto podría ser una alerta por correo electrónico o una notificación en el panel de control para un supervisor.
Pruebas y validación 🔍
Una vez que se construye el modelo, debe probarse para asegurarse de que las rutas de error funcionen según lo previsto. El análisis estático no es suficiente.
Escenarios de simulación
Ejecute simulaciones de procesos que desencadenen intencionalmente errores. Verifique que:
- El evento de borde se activa correctamente.
- El proceso sigue la ruta de excepción.
- Los datos se preservan o se registran adecuadamente.
- El proceso no entra en un bucle infinito de reintentos.
Cobertura de código
Asegúrese de que la lógica de manejo de errores cubra el rango esperado de escenarios de fallo. Esto incluye:
- Problemas de conectividad de red.
- Entradas de datos inválidas.
- Inaccesibilidad de la API externa.
Errores comunes que debes evitar ⚠️
Incluso los modeladores experimentados cometen errores al implementar eventos de error. La conciencia de los problemas comunes ayuda a mantener un modelo robusto.
- Códigos de error faltantes:No definir el código de error en la configuración del motor conduce a fallos silenciosos.
- Caminos inalcanzables:Crear rutas de error que nunca puedan alcanzarse debido a restricciones lógicas.
- Ignorar los registros:Capturar un error y no hacer nada con él. El error siempre debe desencadenar una entrada en el registro o una notificación.
- Fusiones complejas:Fusionar demasiadas rutas de error en una única puerta de enlace sin distinguir la causa del error.
Conclusión sobre el diseño de excepciones 🎓
Diseñar eventos de error requiere un equilibrio entre precisión técnica y pragmatismo operativo. Al comprender los tipos específicos de eventos, configurarlos correctamente y seguir las mejores prácticas establecidas, puedes construir procesos resistentes al fallo.
El objetivo no es eliminar los errores, lo cual es imposible, sino gestionarlos de manera eficiente. Un modelo BPMN bien estructurado con un manejo claro de excepciones reduce el tiempo de inactividad, mejora la visibilidad sobre los fallos y garantiza que las operaciones comerciales puedan recuperarse rápidamente. Enfócate en las necesidades específicas de tus tareas, define códigos claros y prueba rigurosamente las rutas de fallo. Este enfoque conduce a flujos de trabajo confiables que resisten la complejidad del mundo real.

