












Современная доставка программного обеспечения часто зависит от сложных систем, предназначенных для перемещения кода из сред разработки в производственные. Когда эти системы выходят из строя, последствия могут быть серьезными. Диаграмма развертывания служит чертежом для этих инфраструктур, отображая узлы, артефакты и их взаимодействие. Однако диаграмма полезна только в той мере, в какой она соответствует фактической рабочей среде. Когда возникают расхождения, систематическое устранение неисправностей становится необходимым. В этом руководстве рассматривается диагностика и устранение проблем в сложных архитектурах развертывания без использования специфических инструментов или продуктов производителей.
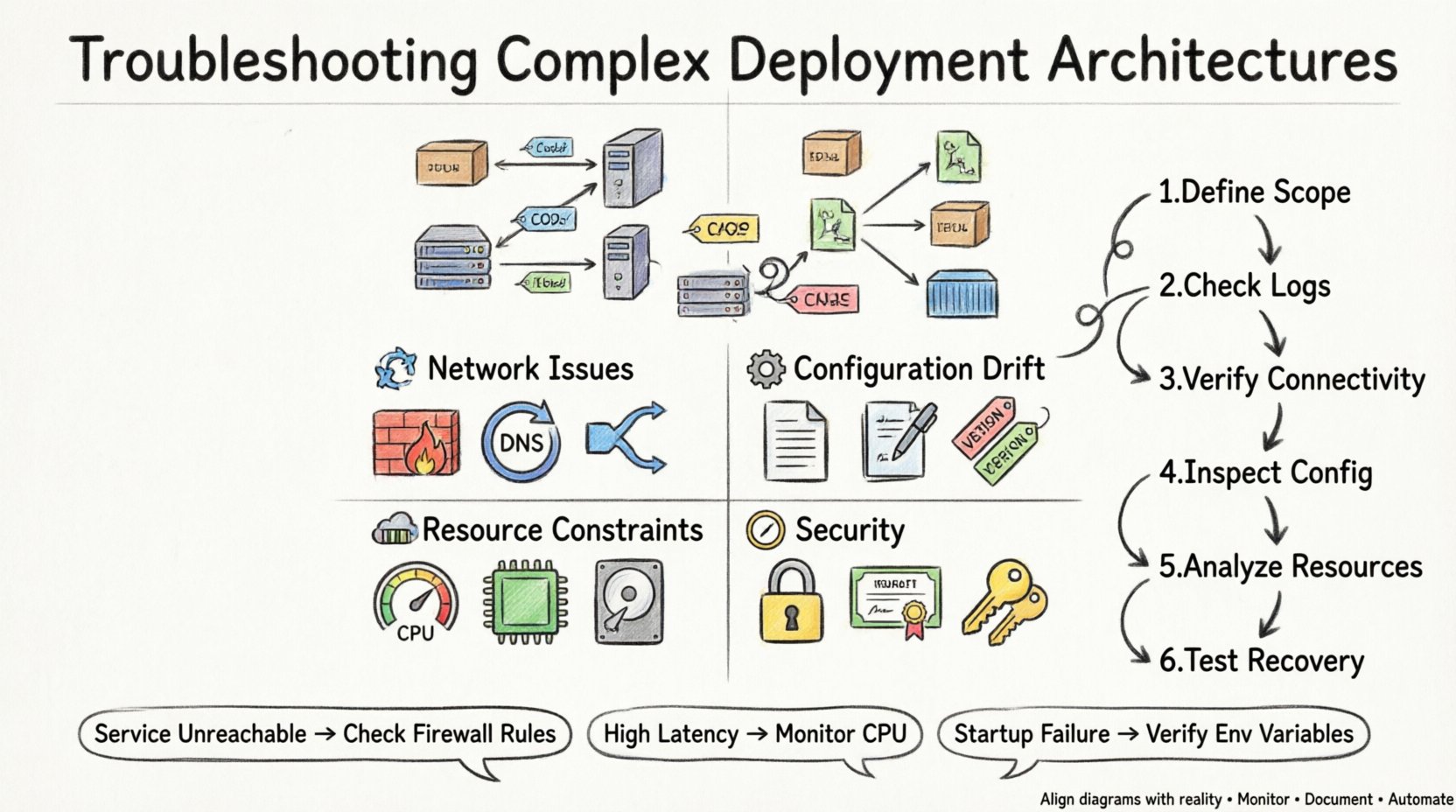
Понимание диаграммы развертывания 📐
Прежде чем пытаться устранить проблему, необходимо понимать, что представляет собой архитектура. Диаграмма развертывания иллюстрирует физическую или логическую структуру системы. Она детально описывает, где расположены программные компоненты, и как они взаимодействуют. В сложных конфигурациях это часто включает несколько уровней абстракции.
-
Узлы: Это представляют вычислительные ресурсы, на которых размещаются артефакты. Это могут быть физические машины, виртуальные экземпляры или контейнеры.
-
Артефакты: Это программные пакеты, устанавливаемые на узлах. К ним относятся исполняемые файлы, конфигурационные файлы и библиотеки.
-
Соединения: Это определяет пути связи между узлами. Они указывают протоколы, порты и типы данных.
-
Зависимости: Это показывает предварительные требования, необходимые для правильной работы узла.
Когда возникает проблема, первый шаг — сравнить диаграмму с текущим состоянием инфраструктуры. Расхождения здесь часто являются причиной сбоев.
Распространённые режимы неисправностей ⚠️
Сложные архитектуры вводят множество точек отказа. Понимание типичных режимов неисправностей помогает быстро сузить круг поиска. Проблемы обычно относятся к категориям, связанным с подключением, конфигурацией, ресурсами или безопасностью.
1. Проблемы с подключением и сетью 🌐
Проблемы с сетью являются одной из наиболее частых причин сбоя развертывания. Даже если диаграмма показывает действительное соединение, сеть может блокировать трафик.
-
Правила брандмауэра: Порты, необходимые для связи, могут быть закрыты промежуточными брандмауэрами или группами безопасности.
-
Разрешение DNS: Сервисы часто полагаются на доменные имена. Если DNS настроен неправильно, узлы не могут находить друг друга.
-
Конфигурация подсети: Узлы в разных сетевых сегментах могут не иметь необходимых таблиц маршрутизации для связи.
-
Балансировщики нагрузки: Логика распределения трафика может быть неправильно настроена, отправляя запросы на неработающие узлы.
2. Отклонение конфигурации ⚙️
Отклонение конфигурации возникает, когда фактическое состояние узла расходится с намеченным состоянием, определённым в плане развертывания. Это часто происходит, когда ручные изменения вносятся непосредственно в производственную среду.
-
Переменные среды: Отсутствующие или неправильные переменные могут вызвать сбой запуска сервисов или их неожиданное поведение.
-
Права доступа к файлам: Неправильные разрешения на конфигурационных файлах могут помешать приложению считывать необходимые данные.
-
Несоответствия версий:Библиотеки или зависимости, установленные на узле, могут не соответствовать версии, указанной в артефакте.
3. Ограничения ресурсов 💾
Даже идеально настроенная архитектура может не справиться, если базовое оборудование не способно выдержать нагрузку. Истощение ресурсов — тихий убийца надежности развертывания.
-
Перегрузка ЦП:Высокая загрузка может привести к задержкам или таймаутам сервиса.
-
Утечки памяти:Приложения, которые неправильно освобождают память, могут привести к тому, что хост исчерпает оперативную память.
-
Пространство на диске:Журналы и временные файлы могут заполнить хранилище, что препятствует записи новых данных.
-
Пропускная способность сети:Недостаточная пропускная способность может привести к сбоям передачи данных между узлами.
4. Безопасность и разрешения 🔒
Протоколы безопасности критически важны для защиты данных, но они также могут блокировать легитимный трафик, если настроены слишком строго.
-
Управление доступом по идентичности:Учетные записи служб могут не иметь разрешений, необходимых для доступа к другим ресурсам.
-
Проверка сертификатов:Сертификаты SSL/TLS, которые истекли или самоподписанные, могут нарушить зашифрованные соединения.
-
Токены аутентификации:Истекшие или недействительные токены могут помешать службам аутентифицироваться друг с другом.
Методология диагностики 🔍
При устранении неполадок структурированный подход предотвращает потерю времени. Следуйте этим шагам, чтобы эффективно локализовать проблему.
-
Определите масштаб:Определите точно, какая часть архитектуры выходит из строя. Целая система, конкретный узел или конкретное соединение?
-
Проверьте журналы:Просмотрите журналы приложения и системы на наличие сообщений об ошибках. Обратите внимание на временные метки, совпадающие с событием сбоя.
-
Проверьте доступность:Используйте сетевые инструменты для проверки доступности между узлами. Убедитесь, что порты открыты и отвечают.
-
Проверьте конфигурацию: Сравните текущую конфигурацию с базовой, определенной на диаграмме развертывания.
-
Проанализируйте использование ресурсов:Мониторьте использование ЦП, памяти и диска в период сбоя.
-
Проверьте восстановление:Попробуйте перезапустить службы или откатить изменения, чтобы увидеть, устранится ли проблема.
Таблица: Распространенные симптомы и соответствующие диагностические действия 📋
В этой таблице кратко описаны частые симптомы и соответствующие действия, необходимые для их диагностики.
|
Симптом |
Возможная причина |
Диагностические действия |
|---|---|---|
|
Служба недоступна |
Сетевой фаервол |
Проверьте группы безопасности и правила фаервола |
|
Высокая задержка |
Перегрузка ЦП |
Мониторьте метрики использования ЦП |
|
Сбой при запуске |
Отсутствует конфигурация |
Проверьте переменные среды и файлы |
|
Сброс соединения |
Истощение ресурсов |
Проверьте использование памяти и дискового пространства |
|
Ошибка аутентификации |
Срок действия сертификата истек |
Проверьте действительность сертификата SSL/TLS |
|
Пайплайн застрял |
Тайм-аут зависимости |
Проверьте сетевую доступность внешних репозиториев |
Глубокий анализ: диагностика сети 🌐
Проблемы с сетью особенно сложны, потому что часто проявляются непостоянно. Когда диаграмма развертывания показывает соединение между узлом A и узлом B, но трафик не проходит, необходимо исследовать путь.
1. Отслеживание маршрута
Используйте инструменты трассировки сети, чтобы определить, где происходят потери пакетов. Это помогает установить, находится ли проблема в локальной сети, в интернете или на узле назначения.
-
Перехват пакетов:Проанализируйте трафик на источнике и назначении, чтобы убедиться, что пакеты отправляются и получены.
-
Таблицы маршрутизации:Убедитесь, что узлы знают, как маршрутизировать трафик друг к другу.
-
Настройки MTU:Несоответствия в настройках максимального размера передачи могут привести к фрагментации и потере пакетов.
2. DNS и обнаружение сервисов
Многие современные архитектуры полагаются на механизмы обнаружения сервисов, а не на жестко закодированные IP-адреса. Если служба обнаружения недоступна, узлы не могут находить друг друга.
-
Проверка записей:Убедитесь, что записи DNS указывают на правильные IP-адреса.
-
Проблемы с кэшем:Кэширование DNS может привести к устаревшим данным. Очистите кэш DNS при необходимости.
-
Внутренние и внешние:Различайте внутренние имена сервисов и внешние доменные имена.
Глубокое погружение: управление конфигурацией ⚙️
Управление конфигурацией гарантирует, что все узлы в архитектуре находятся в известном состоянии. Когда этот процесс сбивается, развертывание становится нестабильным.
1. Инфраструктура как код
Определение инфраструктуры с помощью кода позволяет контролировать версии и обеспечивать воспроизводимость. Однако синтаксические ошибки или логические недостатки в коде могут привести к сбоям развертывания.
-
Проверка: Выполняйте проверку синтаксиса перед применением изменений.
-
Файлы состояния: Убедитесь, что файл состояния точно отражает текущую инфраструктуру.
-
Обнаружение отклонений: Реализуйте инструменты для обнаружения ручных изменений.
2. Управление секретами
Чувствительные данные, такие как пароли и ключи API, должны храниться безопасно. Неправильное обращение с ними может привести к нарушениям безопасности или сбоям развертывания.
-
Шифрование: Убедитесь, что секреты зашифрованы как в состоянии покоя, так и при передаче.
-
Смена: Регулярно меняйте учетные данные, чтобы минимизировать риск.
-
Контроль доступа: Ограничьте доступ к секретам только необходимыми службами.
Глубокое погружение: управление ресурсами 💾
Ограничения ресурсов часто проявляются в периоды пиковой нагрузки. Планирование емкости является обязательным для предотвращения простоев.
1. Стратегии масштабирования
Архитектуры должны проектироваться с возможностью горизонтального или вертикального масштабирования в зависимости от спроса. Если масштабирование не удастся, система может стать неработоспособной.
-
Горизонтальное масштабирование: Добавьте больше экземпляров для обработки увеличенной нагрузки.
-
Вертикальное масштабирование: Увеличьте ресурсы существующих экземпляров.
-
Автомасштабирование: Настройте правила для автоматической корректировки ресурсов на основе метрик.
2. Мониторинг и оповещение
Прогнозирующий мониторинг помогает выявить проблемы с ресурсами до того, как они приведут к сбоям.
-
Пороги: Установите оповещения по использованию ЦП, памяти и диска.
-
Журналы: Собирайте журналы со всех узлов для централизованного анализа.
-
Трассировка: Используйте распределенную трассировку для отслеживания запросов между службами.
Глубокое погружение: безопасность и разрешения 🔒
Безопасность — это не после мысли; она должна быть интегрирована в процесс развертывания.
1. Наименьшие привилегии
Службы должны иметь только те разрешения, которые необходимы для работы. Избыточные разрешения увеличивают поверхность атаки.
-
Роли: Определите конкретные роли для различных служб.
-
Политики: Применяйте политики, ограничивающие доступ к конкретным ресурсам.
-
Аудит: Регулярно проводите аудит разрешений для обеспечения соответствия.
2. Безопасность сети
Сегментация сети ограничивает масштаб потенциального нарушения.
-
VLAN: Разделяйте трафик по функции или среде.
-
Брандмауэры: Блокируйте неразрешенный трафик на границе сети.
-
Шифрование: Шифруйте все данные, передаваемые между узлами.
Целостность конвейера и автоматизации 🔄
Конвейер, перемещающий код из разработки в производство, является критически важным компонентом архитектуры развертывания. Если конвейер выходит из строя, код не достигает среды.
1. Этапы конвейера
Разбейте конвейер на отдельные этапы для изоляции сбоев.
-
Сборка: Компилируйте код и создавайте артефакты.
-
Тестирование: Запускайте автоматизированные тесты для проверки функциональности.
-
Развертывание: Передавайте артефакты в целевую среду.
-
Проверка: Выполняйте проверки после развертывания.
2. Процедуры отката
Когда развертывание неудачно, быстрый откат минимизирует простои.
-
Версионирование: Храните доступными предыдущие версии артефактов.
-
Автоматизация: Автоматизируйте процесс отката, чтобы снизить количество ошибок, вызванных человеком.
-
Тестирование: Регулярно тестируйте процедуры отката, чтобы убедиться, что они работают.
Наблюдаемость и журналы 🔍
Наблюдаемость предоставляет информацию о внутреннем состоянии системы. Без нее устранение неполадок — это угадывание.
1. Централизованный журнал
Собирайте журналы со всех узлов в централизованном месте для более простого анализа.
-
Агрегация: Используйте агрегатор журналов для сбора данных.
-
Индексация: Индексируйте журналы для быстрого поиска.
-
Хранение: Определите политики хранения для управления хранилищем.
2. Метрики и панели мониторинга
Визуализируйте ключевые показатели эффективности для быстрого выявления аномалий.
-
Ключевые метрики: Отслеживайте скорости запросов, скорости ошибок и задержки.
-
Оповещения: Настройте оповещения для пороговых значений метрик.
-
Визуализация: Используйте панели мониторинга для отображения данных во времени.
Реагирование на инциденты и восстановление 🚨
Даже при самом лучшем планировании инциденты будут происходить. Наличие плана реагирования обеспечивает быстрое восстановление.
1. Классификация инцидентов
Классифицируйте инциденты по степени серьезности и влиянию.
-
Критический: Система недоступна или данные скомпрометированы.
-
Высокий: Значительное ухудшение работы сервиса.
-
Средний: Незначительные проблемы, влияющие на часть пользователей.
-
Низкий: Эстетические или несрочные проблемы.
2. Связь
Держите заинтересованные стороны в курсе на протяжении всего инцидента.
-
Обновления статуса:Предоставляйте регулярные обновления о ходе работы.
-
Пост-мортем:Проанализируйте инцидент после его устранения.
-
Действия:Назначьте задачи для предотвращения повторения.
Документация и контроль версий 📝
Документация обеспечивает сохранение и обмен знаниями. Контроль версий обеспечивает отслеживание изменений.
1. Документация архитектуры
Поддерживайте диаграмму развертывания в актуальном состоянии.
-
Изменения:Документируйте каждое изменение в архитектуре.
-
Зависимости:Перечислите все внешние и внутренние зависимости.
-
Процедуры:Документируйте стандартные операционные процедуры.
2. Управление изменениями
Контролируйте, как вносятся изменения в среду.
-
Обзор:Требуйте обзор для значительных изменений.
-
Утверждение:Получите утверждение перед применением изменений.
-
Отслеживание:Отслеживайте все изменения в системе.
Окончательные соображения по здоровью развертывания 🏥
Поддержание здоровой архитектуры развертывания требует постоянных усилий. Регулярные обзоры и обновления необходимы для соответствия меняющимся требованиям. Сосредоточьтесь на следующих областях, чтобы обеспечить долгосрочную стабильность.
-
Регулярные аудиты:Проводите периодические аудиты архитектуры.
-
Планирование мощности: Планируйте будущий рост.
-
Обучение: Обучите команду методологиям устранения неполадок.
-
Автоматизация: Автоматизируйте повторяющиеся задачи, чтобы снизить количество человеческих ошибок.
-
Тестирование: Регулярно тестируйте архитектуру в среде разработки.
Следуя структурированному подходу к устранению неполадок, команды могут быстрее решать проблемы и сокращать простои. Цель заключается не только в устранении проблем, но и в создании системы, устойчивой к сбоям и простой в обслуживании. Диаграммы развертывания — это живые документы, которые должны развиваться вместе с инфраструктурой. Когда это происходит, архитектура остается согласованной с потребностями бизнеса.
Помните, что каждый сбой — это возможность для обучения. Документирование корневой причины и решения помогает предотвратить подобные проблемы в будущем. Эта база знаний становится ценным активом для всей организации.

