












📋 Введение в визуализацию инфраструктуры
Проектирование диаграммы развертывания — это критически важная задача для любой инженерной команды, стремящейся создать надежные, высокопроизводительные системы. Эти диаграммы служат чертежом того, как программные компоненты взаимодействуют с физической или виртуальной инфраструктурой. В отличие от кода, который постоянно эволюционирует, архитектурное представление часто остается статичным, если только оно не обновляется намеренно. Это создает уникальную проблему: как представить систему, предназначенную для роста, изменений и адаптации, не создавая документ, который становится устаревшим в момент публикации? 🤔
Масштабируемая диаграмма развертывания делает больше, чем просто показывает, где работает программное обеспечение. Она передает стратегию обработки увеличивающейся нагрузки, управления сбоями и обеспечения безопасности на всей сети. Когда архитекторы сосредоточены исключительно на текущем состоянии, они рискуют создать карту, которая не сможет направлять будущее расширение. В этом руководстве рассматриваются методологии создания диаграмм, отражающих настоящую масштабируемость, обеспечивая соответствие визуального представления операционной реальности вашей инфраструктуры. Мы рассмотрим всё — от абстракции узлов до визуализации потоков данных, избегая распространённых ловушек, ведущих к вводящей в заблуждение документации. 📉➡️📈
🧱 Основные компоненты диаграммы развертывания
Прежде чем решать вопрос масштабируемости, необходимо понять основные строительные блоки. Диаграмма развертывания отображает программные артефакты на аппаратных узлах. Эти артефакты — это скомпилированные или упакованные единицы приложения, а узлы представляют вычислительные ресурсы, на которых эти единицы выполняются. Чтобы сохранить ясность, особенно в сложных средах, необходимо различать логическое и физическое представление.
- Узлы: Они представляют физические или виртуальные машины, серверы или контейнеры. Их можно классифицировать по роли, например, вычислительные узлы, узлы баз данных или шлюзы сети. В масштабируемом контексте узлы должны быть помечены с указанием уровня производительности, а не конкретных характеристик оборудования, которые часто меняются.
- Артефакты: Это развертываемые единицы. Будь то исполняемый файл, библиотека или образ контейнера, артефакт должен отличаться от узла, на котором он находится. Такое разделение позволяет показать несколько артефактов, работающих на одном узле, или один и тот же артефакт, распределённый по многим узлам.
- Каналы связи: Эти соединения определяют поток данных. Они должны указывать используемый протокол (например, HTTP, gRPC, TCP) и направление данных. Для масштабируемости крайне важно явно показывать балансировщики нагрузки и границы сети.
При документировании этих компонентов избегайте загромождения диаграммы каждым отдельным сервером. Вместо этого используйте контейнеры группировки для представления кластеров. Такая абстракция крайне важна для масштабируемости, поскольку позволяет диаграмме оставаться актуальной даже при удвоении или утроении количества отдельных узлов. 🖥️
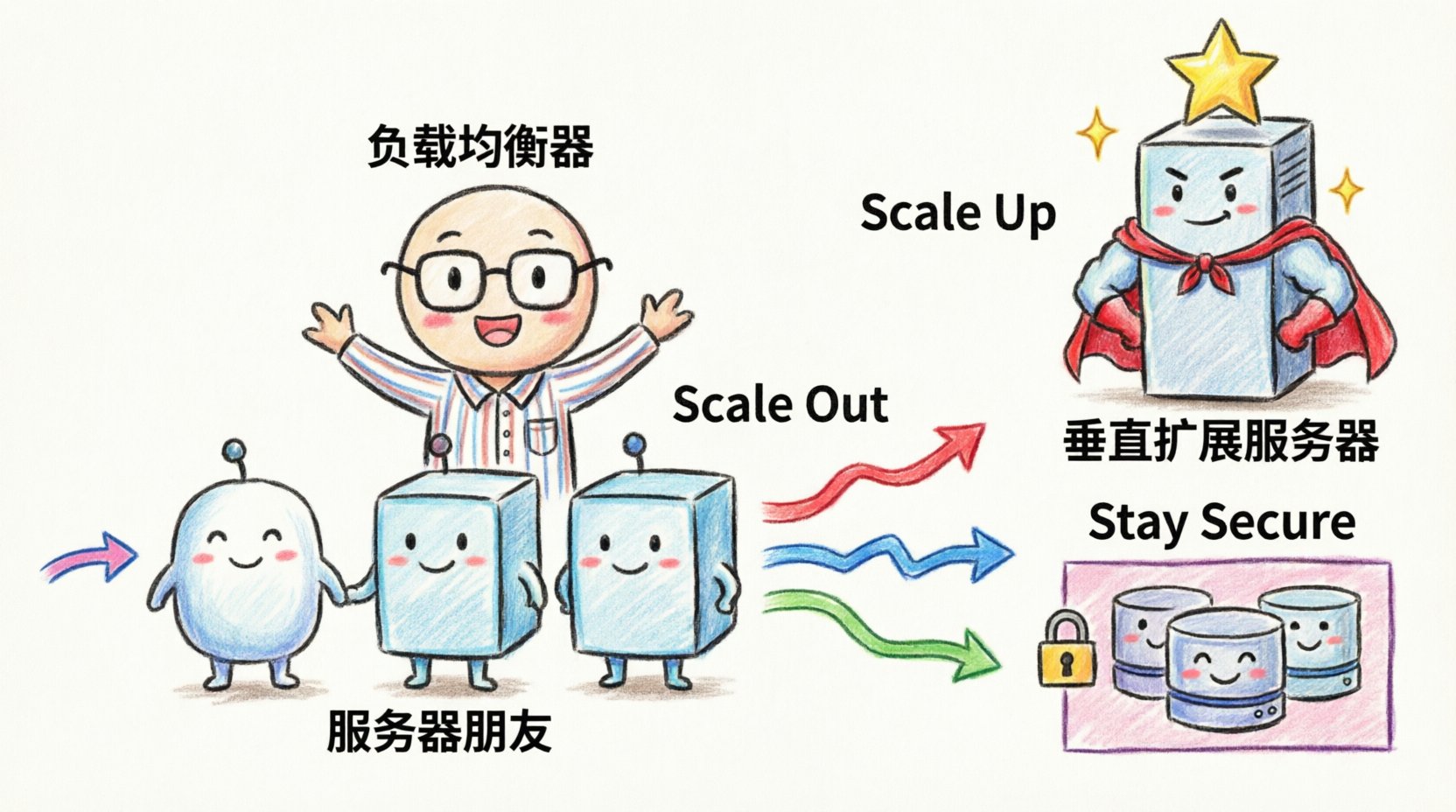
📈 Стратегии представления масштабируемости
Масштабируемость — это способность системы справляться с ростом нагрузки. Диаграмма развертывания должна визуализировать, как система достигает этого. Существует два основных метода: горизонтальное масштабирование (добавление дополнительных узлов) и вертикальное масштабирование (увеличение мощности узла). Диаграмма должна отражать, какая стратегия используется, и как система управляет распределением работы.
Паттерны горизонтального масштабирования
Горизонтальное масштабирование подразумевает добавление дополнительных экземпляров сервиса. На диаграмме это часто отображается как кластер идентичных узлов за балансировщиком нагрузки. Чтобы сделать это понятным:
- Используйте пунктирные линии: Укажите, что узлы в кластере являются взаимозаменяемыми экземплярами. Это сигнализирует читателю, что добавление или удаление одного экземпляра не нарушает архитектуру.
- Маркируйте кластер: Вместо того чтобы называть каждый узел, обозначьте группу функцией, например, «Кластер приложений» или «Пул рабочих».
- Покажите балансировщик: Точка входа для трафика должна быть отдельным компонентом, распределяющим запросы. Это подчеркивает механизм, обеспечивающий горизонтальное масштабирование.
Вопросы вертикального масштабирования
Вертикальное масштабирование означает повышение ресурсов существующего узла. Хотя в современных архитектурах микросервисов это встречается реже, оно по-прежнему актуально для слоев баз данных или монолитных компонентов. На диаграмме это следует отображать, указывая ограничения ресурсов или уровни производительности, например, «Высокопроизводительные вычисления» против «Стандартные вычисления».
Сравнение паттернов масштабирования
Понимание компромиссов между стратегиями масштабирования помогает точно спроектировать диаграмму. В следующей таблице перечислены характеристики различных подходов.
| Стратегия | Визуальное представление на диаграмме | Наилучший случай использования |
|---|---|---|
| Горизонтальное масштабирование | Несколько идентичных узлов за балансировщиком нагрузки | Веб-сервисы, безсостоятельные API, микросервисы |
| Вертикальное масштабирование | Одиночный узел с обновлёнными метками ресурсов | Базы данных, устаревшие монолиты, приложения с состоянием |
| Группы автоматического масштабирования | Динамическая группа узлов с триггерами масштабирования | Облачные среды, ориентированные на облачные технологии, с переменной нагрузкой |
| Активно-резервный | Основной узел с резервным подключением | Требования высокой доступности для критически важных систем |
Используя эти визуальные обозначения, заинтересованные стороны могут сразу понять потенциал роста системы, не читая код. Эта ясность необходима для планирования мощностей и прогнозирования бюджета. 💰
🔒 Безопасность и сетевая топология
Безопасность не должна быть после мысли при проектировании развертывания. Масштабируемая система должна оставаться защищённой при расширении. Диаграмма развертывания должна явно показывать границы сети, брандмауэры и зоны безопасности. Это помогает выявить потенциальные векторы атаки и обеспечивает соблюдение требований соответствия на этапе проектирования.
- Зоны безопасности:Разделите диаграмму на зоны, такие как «Публичная интернет-сеть», «DMZ (зона демилитаризации)» и «Внутренняя сеть». Такое визуальное разделение уточняет, какие компоненты подвержены воздействию извне, а какие защищены.
- Брандмауэры и шлюзы:Представьте устройства сетевой безопасности как отдельные узлы или границы. Покажите, какие порты и протоколы разрешены для прохождения через эти барьеры.
- Шифрование:Укажите, где данные шифруются при передаче. Использование значка замка или специальной метки на линиях соединения может указывать на использование SSL/TLS. Это критически важно для диаграмм, включающих передачу конфиденциальных данных.
Когда система масштабируется, политики безопасности должны масштабироваться вместе с ней. Например, если вы добавляете больше веб-серверов, они все должны соответствовать одной и той же политике безопасности. Диаграмма должна отражать эту единообразность. Если разные уровни имеют разные требования к безопасности, используйте цветовую кодировку или различные формы для их различения. Это предотвращает ошибочное предположение, что все узлы обрабатываются одинаково, хотя это не так. 🛡️
💾 Сохранение данных и управление состоянием
Одной из самых сложных для визуализации сторон масштабируемости является работа с данными. По мере увеличения количества узлов приложения состояние данных должно управляться тщательно. Диаграмма развертывания должна показывать, где хранится состояние, и как к нему осуществляется доступ.
Безсостоятельные vs. Состоятельные
Узлы приложения должны быть по возможности безсостоятельными. Это означает, что они не хранят данные сессий пользователей локально, а полагаются на внешние службы. Диаграмма должна чётко показывать разделение между вычислительным слоем и слоем хранения. Если приложение состоятельное, диаграмма должна явно связывать узлы с бэкендом хранения.
- Внешнее хранилище:Представьте базы данных и кэши как отдельные узлы. Подключите их к кластеру приложения по выделенному сетевому пути.
- Общее хранилище:Если несколько узлов обращаются к одной и той же файловой системе, укажите это с помощью узла общего хранилища. Обратите внимание, что общее хранилище может стать узким местом.
- Распределенные данные: Для высокой масштабируемости покажите шардирование или репликацию данных. Используйте стрелки для обозначения потока данных между узлами базы данных, чтобы показать задержку репликации или синхронизацию.
Стратегии кэширования
Производительность часто зависит от кэширования. Диаграмма должна включать уровни кэша, обычно размещаемые между приложением и базой данных. Покажите иерархию кэшей (например, локальный кэш, распределенный кэш). Это помогает понять, где существует избыточность данных и как она влияет на согласованность. Например, распределенный кэш позволяет любому узлу кластера получать доступ к данным сессии, эффективно поддерживая горизонтальное масштабирование. 🚀
🔄 Автоматизация и динамическое масштабирование
Современная инфраструктура редко бывает статичной. Она управляется с помощью инструментов автоматизации и инфраструктуры как кода. Хотя диаграмма развертывания отражает логическое состояние, она должна учитывать механизмы, вызывающие изменения. К ним относятся пайплайны CI/CD и системы оркестрации.
- Оркестрация: Если система оркестрации управляет узлами, изобразите её как плоскость управления. Покажите, как она взаимодействует с вычислительными узлами. Это уточняет, как создаются новые экземпляры и удаляются старые.
- Интеграция CI/CD: Хотя сам пайплайн — это процесс, его влияние на развертывание можно отразить. Укажите, откуда исходит триггер развертывания и куда отправляются артефакты.
- Мониторинг: Включите узлы или агенты мониторинга. Масштабируемость требует прозрачности. Покажите, где собираются метрики и куда они отправляются. Это гарантирует, что диаграмма отражает не только структуру, но и наблюдаемость системы.
Включив эти элементы, диаграмма превращается в живой документ, соответствующий практикам DevOps. Она устраняет разрыв между статической архитектурой и динамическими операциями. Такая согласованность необходима для команд, полагающихся на политики автоматического масштабирования. ⚙️
🛠️ Обслуживание и контроль версий
Диаграмма развертывания — это часть документации, требующая обслуживания. В отличие от кода, она не компилируется и не проходит тестирование. Её необходимо вручную обновлять, чтобы сохранить актуальность. Для этого следует внедрить специфические практики управления самой диаграммой.
- Версионирование: Храните диаграммы в том же репозитории, что и код. Используйте систему контроля версий для отслеживания изменений во времени. Это позволяет командам видеть, как архитектура развивалась во время конкретных релизов.
- Уровни абстракции: Поддерживайте несколько версий диаграммы. Высокий уровень для руководства и низкий — для инженеров. Это предотвращает перегрузку информацией и обеспечивает, чтобы нужная аудитория получала нужные детали.
- Инструменты: Используйте инструменты, поддерживающие диаграммы как код или форматы, совместимые с контролем версий. Это снижает сложность обновления документации. Избегайте проприетарных бинарных форматов, которые трудно сравнивать или объединять.
Когда система изменяется, диаграмма должна быть первым артефактом, который нужно обновить. Это гарантирует, что будущие диагностика и онбординг будут основаны на точной информации. Относитесь к диаграмме с той же дисциплиной, что и к исходному коду. 📝
🚫 Распространённые архитектурные ошибки
Даже опытные архитекторы попадают в ловушки при проектировании этих диаграмм. Своевременное распознавание этих ошибок может сэкономить значительное время при реализации. Вот наиболее распространённые ошибки, которые следует избегать.
- Чрезмерная сложность:Включение каждого отдельного сервера и соединения кабелем. Это затрудняет понимание основной архитектуры. Сосредоточьтесь на логическом потоке и ключевых компонентах инфраструктуры.
- Статическое представление:Показывает фиксированное количество узлов, не указывая, что они являются частью более крупного пула. Это вводит заинтересованные стороны в заблуждение, заставляя думать, что ёмкость ограничена нарисованными узлами.
- Отсутствие точек отказа:Показывает только путь «счастливого» сценария. Масштабируемая система должна учитывать отказы. Покажите резервные пути и резервные узлы, чтобы продемонстрировать устойчивость.
- Игнорирование задержек: Не отображение физического расстояния между узлами. В распределенных системах сетевая задержка является критическим фактором. Используйте аннотации для указания географических регионов или местоположений центров обработки данных.
- Устаревшие метки: Использование спецификаций оборудования, которые часто меняются. Используйте общие термины, такие как «вычислительный экземпляр», вместо «сервер Intel Xeon».
📊 Визуальная иерархия и компоновка
Расположение диаграммы имеет такое же значение, как и её содержание. Хорошо организованная диаграмма естественным образом направляет взгляд по потоку данных. Используйте вертикальный или слева направо поток для обработки запросов. Группируйте связанные компоненты вместе, чтобы снизить когнитивную нагрузку.
- Согласованная иконография: Используйте стандартный набор форм для узлов, артефактов и соединений. Согласованность помогает читателям быстро распознавать паттерны.
- Интервалы: Оставляйте достаточно места между компонентами, чтобы можно было добавить новые элементы в будущем. Переполненные диаграммы трудно читать и ещё труднее изменять.
- Аннотации: Используйте текстовые поля для объяснения сложных взаимодействий. Если соединение представляет конкретный протокол или требование безопасности, пометьте его непосредственно.
🌐 Облачные и гибридные аспекты
Многие системы охватывают несколько сред, например, локальные центры обработки данных и публичные облачные платформы. Диаграмма развертывания должна четко различать эти среды. Используйте различные фоновые изображения или рамки, чтобы отделить облачные регионы от локальной инфраструктуры.
- Границы облачной среды: Четко обозначьте границу облачного провайдера. Покажите, где данные покидают внутреннюю сеть.
- Гибридное подключение: Покажите связь между локальной и облачной средой. Укажите пропускную способность или тип соединения (например, VPN, выделенная линия).
- Сознание регионов: Если система охватывает несколько географических регионов, покажите пути репликации данных. Это критически важно для планирования восстановления после аварий.
Визуализация гибридных сред помогает командам понять сложность суверенитета данных и задержек. Это гарантирует, что архитектура учитывает ограничения физических местоположений. 🌍
🔍 Проверка и валидация
Перед окончательным завершением диаграммы она должна пройти процесс проверки. Это включает проверку диаграммы по отношению к реально работающей системе. Расхождения между картой и реальностью являются распространёнными и должны быть устранены.
- Обход: Пройдитесь по диаграмме вместе с командой эксплуатации. Попросите их смоделировать развертывание или сценарий сбоя.
- Согласие заинтересованных сторон: Убедитесь, что архитекторы, разработчики и команды безопасности согласны с представлением. Расхождения во взглядах на архитектуру часто приводят к ошибкам при реализации.
- Проверки автоматизации: Если возможно, автоматизируйте проверку диаграммы по отношению к инфраструктуре. Инструменты могут сравнивать заданное состояние с фактическим, чтобы выявить отклонения.
Валидация гарантирует, что диаграмма — не просто теоретическая модель, а отражение реальности. Эта точность формирует доверие к документации и способствует принятию более обоснованных решений. ✅
📝 Краткое изложение основных выводов
Создание масштабируемой диаграммы развертывания требует баланса между детализацией и абстракцией. Недостаточно показать, что существует сегодня; диаграмма должна иллюстрировать, как система будет расти. Сосредоточившись на основных компонентах, стратегиях масштабирования, зонах безопасности и управлении данными, вы создаете ценную ценность для всей инженерной организации.
Помните, что нужно избегать перегруженности, поддерживать контроль версий и регулярно проверять диаграмму по отношению к рабочей среде. Эти практики обеспечивают, что архитектура остается понятной, точной и выполнимой по мере развития системы. При хорошо спроектированной диаграмме команды могут уверенно справляться со сложностью и создавать системы, способные выдержать испытание ростом. 🏆

