












现代软件交付通常依赖于复杂的系统,这些系统旨在将代码从开发环境移至生产环境。当这些系统出现故障时,影响可能非常严重。部署图作为这些基础设施的蓝图,描绘了节点、构件及其交互关系。然而,一张图的实用性取决于它与实际运行环境的一致性。当出现差异时,系统性排查变得至关重要。本指南探讨了如何在不依赖特定供应商工具或产品的情况下,诊断并解决复杂部署架构中的问题。
理解部署图 📐
在尝试修复问题之前,必须先理解架构所代表的含义。部署图展示了系统的物理或逻辑结构,详细说明了软件组件的存放位置以及它们之间的通信方式。在复杂的部署中,这通常涉及多层抽象。
-
节点: 这些代表了构件被部署的计算资源。它们可以是物理机器、虚拟实例或容器。
-
构件: 这些是安装在节点上的软件包,包括二进制文件、配置文件和库。
-
连接: 这些定义了节点之间的通信路径,指定协议、端口和数据类型。
-
依赖关系: 这些显示了节点正常运行所需的先决条件。
当出现问题时,第一步是将图表与基础设施的当前状态进行对比。这里的不一致往往是故障的根本原因。
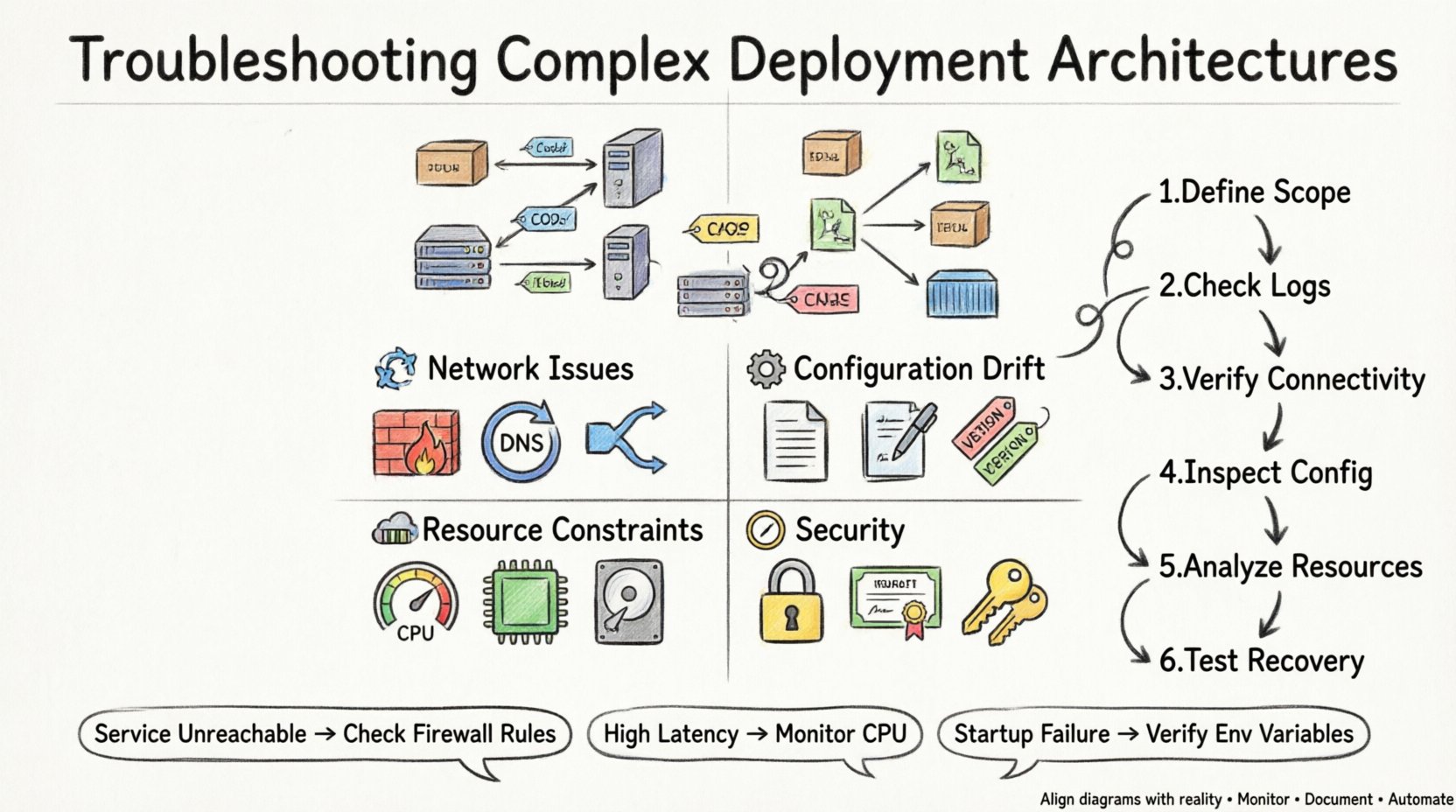
常见故障模式 ⚠️
复杂的架构引入了多个故障点。了解典型的故障模式有助于快速缩小排查范围。问题通常归类于连接性、配置、资源或安全方面。
1. 连接性和网络问题 🌐
网络问题是导致部署失败的最常见原因之一。即使图表显示连接有效,网络仍可能阻断流量。
-
防火墙规则: 通信所需的端口可能被中间防火墙或安全组关闭。
-
DNS 解析: 服务通常依赖域名。如果 DNS 配置不正确,节点将无法相互定位。
-
子网配置: 位于不同网络段的节点可能缺少必要的路由表以进行通信。
-
负载均衡器: 流量分发逻辑可能配置错误,导致请求被发送到不健康的节点。
2. 配置漂移 ⚙️
当节点的实际状态与部署计划中定义的预期状态出现偏差时,就会发生配置漂移。这通常发生在直接对生产环境进行手动更改时。
-
环境变量: 缺失或错误的变量可能导致服务无法启动或行为异常。
-
文件权限: 配置文件权限不正确可能会阻止应用程序读取必要数据。
-
版本不匹配: 节点上安装的库或依赖项版本可能与构件中指定的版本不匹配。
3. 资源限制 💾
即使架构配置得再完美,如果底层硬件无法承受负载,也会失败。资源耗尽是部署可靠性无声的杀手。
-
CPU饱和: 高利用率可能导致延迟或服务超时。
-
内存泄漏: 未能正确释放内存的应用程序可能导致主机内存耗尽。
-
磁盘空间: 日志和临时文件可能填满存储空间,阻止新数据写入。
-
网络带宽: 吞吐量不足可能导致节点间数据传输失败。
4. 安全与权限 🔒
安全协议对于保护数据至关重要,但如果配置过于严格,也可能阻断合法流量。
-
身份访问管理: 服务账户可能缺少访问其他资源所需的权限。
-
证书验证: 过期或自签名的SSL/TLS证书可能导致加密连接中断。
-
认证令牌: 过期或无效的令牌可能导致服务之间无法相互认证。
诊断方法论 🔍
排查问题时,采用结构化方法可避免浪费时间。遵循以下步骤可高效定位问题。
-
定义范围: 确定架构中具体是哪一部分出现故障。是整个系统、某个特定节点,还是某个特定连接?
-
检查日志: 查看应用程序和系统日志中的错误信息。查找与故障事件时间相匹配的时间戳。
-
验证连接性: 使用网络工具测试节点间的可达性。检查端口是否开放并能响应。
-
检查配置: 将当前配置与部署图中定义的基线进行对比。
-
分析资源使用情况: 在故障时间段内监控 CPU、内存和磁盘使用情况。
-
测试恢复: 尝试重启服务或回滚更改,以查看问题是否解决。
表格:常见症状与诊断操作 📋
该表格总结了常见症状及诊断它们所需的相应操作。
|
症状 |
潜在原因 |
诊断操作 |
|---|---|---|
|
服务不可达 |
网络防火墙 |
检查安全组和防火墙规则 |
|
高延迟 |
CPU饱和 |
监控 CPU 使用率指标 |
|
启动失败 |
配置缺失 |
验证环境变量和文件 |
|
连接重置 |
资源耗尽 |
检查内存和磁盘空间使用情况 |
|
认证错误 |
证书过期 |
检查 SSL/TLS 证书的有效性 |
|
流水线卡住 |
依赖超时 |
检查与外部仓库的网络连接 |
深入分析:网络诊断 🌐
网络问题尤其棘手,因为它们通常表现为间歇性。当部署图显示节点 A 和节点 B 之间存在连接,但流量并未流动时,你必须调查整个路径。
1. 跟踪路由
使用网络追踪工具来确定数据包在何处丢失。这有助于判断问题是否存在于本地网络、互联网之间,或目标节点上。
-
数据包捕获:分析源端和目标端的流量,查看数据包是否被发送和接收。
-
路由表:确认节点之间知道如何相互路由流量。
-
MTU 设置:最大传输单元不匹配可能导致数据包分片和丢失。
2. DNS 和服务发现
许多现代架构依赖于服务发现机制,而不是硬编码的IP地址。如果发现服务宕机,节点将无法相互找到。
-
记录验证:确保DNS记录指向正确的IP地址。
-
缓存问题:DNS缓存可能导致过期数据。如有必要,请清除DNS缓存。
-
内部与外部:区分内部服务名称和外部域名。
深入探究:配置管理 ⚙️
配置管理确保架构中的所有节点都处于已知状态。当此过程失败时,部署将变得不稳定。
1. 基础设施即代码
使用代码定义基础设施,可以实现版本控制和可重现性。然而,代码中的语法错误或逻辑缺陷可能导致部署失败。
-
验证:在应用更改前运行语法检查。
-
状态文件:确保状态文件准确反映当前基础设施。
-
漂移检测:实施工具以检测手动更改的发生。
2. 密钥管理
密码和API密钥等敏感数据必须安全存储。处理不当可能导致安全漏洞或部署失败。
-
加密:确保密钥在静态存储和传输过程中均被加密。
-
轮换:定期轮换凭据以降低风险。
-
访问控制:仅限必要的服务访问密钥。
深入探讨:资源管理 💾
资源限制通常在使用高峰期显现。规划容量对于防止中断至关重要。
1. 扩展策略
架构应根据需求设计为横向或纵向扩展。如果扩展失败,系统可能变得无响应。
-
横向扩展:增加更多实例以应对增加的负载。
-
纵向扩展:增加现有实例的资源。
-
自动扩展:配置规则,根据指标自动调整资源。
2. 监控与告警
主动监控有助于在资源问题导致故障前发现它们。
-
阈值:为CPU、内存和磁盘使用率设置告警。
-
日志:聚合所有节点的日志以进行集中分析。
-
追踪:使用分布式追踪来跨服务跟踪请求。
深入探讨:安全与权限 🔒
安全不应是事后考虑;必须融入部署流程。
1. 最小权限
服务应仅拥有运行所必需的权限。权限过度的服务会增加攻击面。
-
角色:为不同服务定义特定角色。
-
策略:应用限制访问特定资源的策略。
-
审计:定期审计权限以确保合规性。
2. 网络安全
网络分段可以限制潜在泄露的影响范围。
-
VLAN:按功能或环境分离流量。
-
防火墙:在网络边缘阻止未经授权的流量。
-
加密:对节点之间传输的所有数据进行加密。
流水线与自动化完整性 🔄
从开发到生产移动代码的流水线是部署架构中的关键组件。如果流水线失败,代码将无法到达环境。
1. 流水线阶段
将流水线分解为不同的阶段,以隔离故障。
-
构建:编译代码并创建构件。
-
测试:运行自动化测试以验证功能。
-
部署:将构件推送到目标环境。
-
验证:执行部署后的检查。
2. 回滚流程
当部署失败时,快速回滚可最大限度减少停机时间。
-
版本控制:保留构件的先前版本以备使用。
-
自动化:自动化回滚流程以减少人为错误。
-
测试:定期测试回滚流程以确保其正常运行。
可观测性与日志 🔍
可观测性提供了对系统内部状态的洞察。没有它,故障排查只能靠猜测。
1. 集中化日志
将所有节点的日志集中收集到一个位置,以便于分析。
-
聚合: 使用日志聚合工具来收集数据。
-
索引: 对日志进行索引,以便快速搜索。
-
保留: 定义保留策略以管理存储空间。
2. 指标与仪表板
可视化关键性能指标,以便快速发现异常。
-
关键指标: 跟踪请求速率、错误率和延迟。
-
告警: 为指标阈值设置告警。
-
可视化: 使用仪表板展示随时间变化的数据。
事件响应与恢复 🚨
即使规划得再好,事件仍会发生。拥有响应计划可以确保快速恢复。
1. 事件分类
根据严重程度和影响对事件进行分类。
-
严重: 系统已宕机或数据已受损。
-
高: 服务出现显著降级。
-
中: 影响部分用户的轻微问题。
-
低: 外观性或非紧急问题。
2. 沟通
在事件发生期间持续向利益相关者通报情况。
-
状态更新:提供进度的定期更新。
-
事后分析:在事件解决后进行分析。
-
行动事项:分配任务以防止问题再次发生。
文档与版本控制 📝
文档确保知识得以保留和共享。版本控制确保变更被追踪。
1. 架构文档
保持部署图的最新状态。
-
变更:记录架构的每一次变更。
-
依赖关系:列出所有外部和内部依赖关系。
-
流程:记录标准操作流程。
2. 变更管理
控制环境变更的方式。
-
审查:对重大变更要求进行审查。
-
批准:在应用变更前获得批准。
-
追踪:在系统中追踪所有变更。
部署健康性的最终考量 🏥
保持健康的部署架构需要持续努力。定期审查和更新是跟上不断变化需求的必要条件。关注以下领域以确保长期稳定。
-
定期审计:定期对架构进行审计。
-
容量规划: 为未来增长做好规划。
-
培训: 对团队进行故障排除方法的培训。
-
自动化: 自动化重复性任务,以减少人为错误。
-
测试: 定期在预发布环境中测试架构。
通过遵循结构化的故障排除方法,团队可以更快地解决问题并减少停机时间。目标不仅仅是修复问题,更是构建一个具有韧性且易于维护的系统。部署图是动态文档,应随着基础设施的发展而不断更新。当它们更新时,架构就能持续与业务需求保持一致。
请记住,每一次失败都是一次学习的机会。记录根本原因和解决方案有助于防止未来出现类似问题。这个知识库将成为整个组织的宝贵资产。

