












Comprendre l’architecture physique d’un système logiciel est essentiel pour une livraison et une maintenance réussies. Un diagramme de déploiement fournit une vue d’ensemble de l’infrastructure matérielle et logicielle, illustrant comment les composants sont mappés sur des nœuds physiques. Ces visualisations ne sont pas simplement des dessins ; elles sont des plans directeurs pour la stabilité, la scalabilité et la sécurité du système.
Ce guide explore les modèles les plus fréquemment rencontrés dans les diagrammes de déploiement. En reconnaissant ces structures, les architectes et les développeurs peuvent communiquer les exigences du système de manière plus efficace et anticiper les défis liés à l’infrastructure avant qu’ils ne surviennent. Nous examinerons les éléments, les modèles et les considérations pratiques pour chacun.
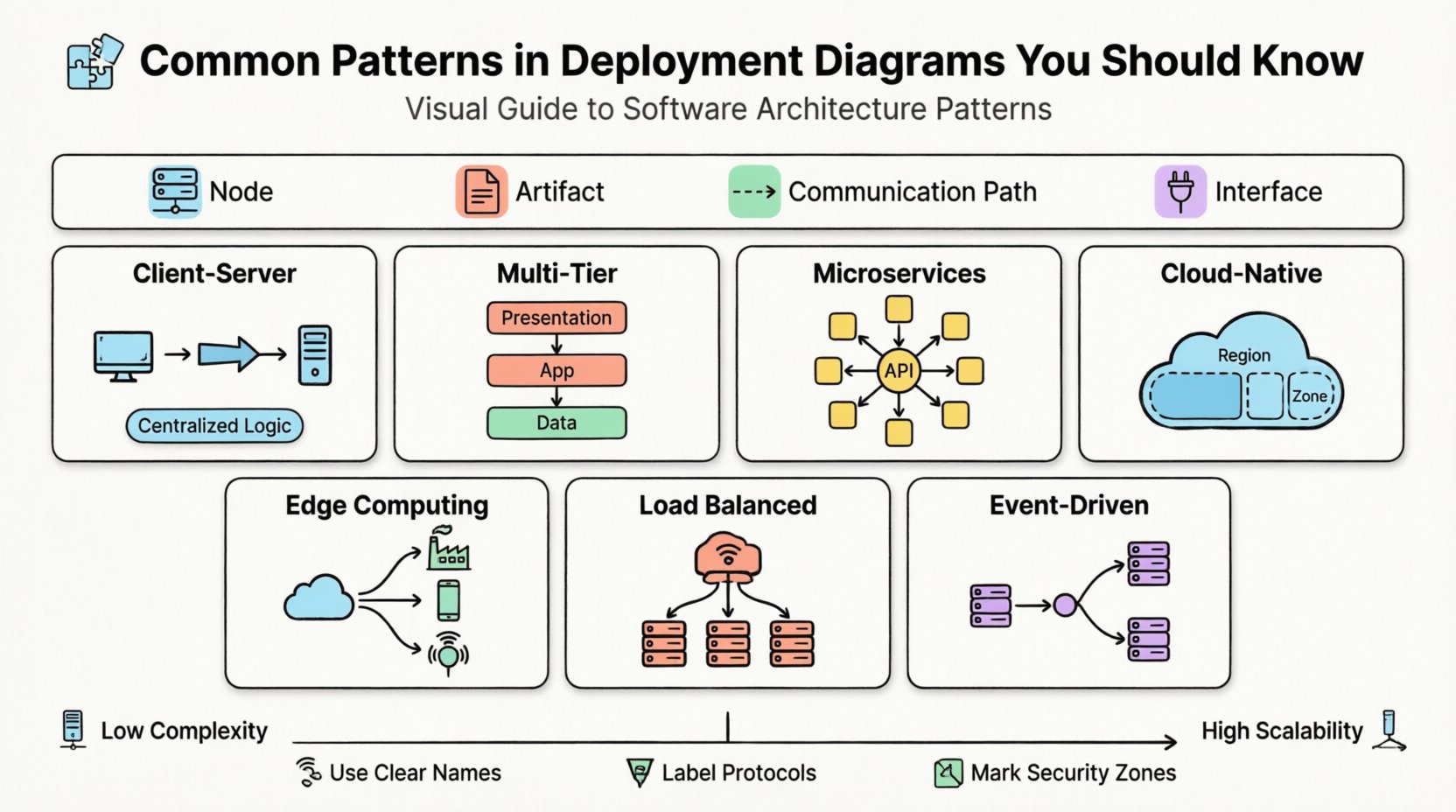
Les composants fondamentaux d’un diagramme de déploiement 🧩
Avant de plonger dans des modèles spécifiques, il est nécessaire de comprendre les éléments de base utilisés pour construire ces diagrammes. Une vue de déploiement standard repose sur quelques concepts clés :
- Nœud : Un appareil informatique physique ou virtuel. Cela peut être un serveur, un appareil mobile, un capteur IoT ou une instance de conteneur. Les nœuds représentent l’environnement d’exécution.
- Artéfact : Un élément physique d’information ou de code déployé sur un nœud. Les exemples incluent les fichiers exécutables, les schémas de base de données, les fichiers de configuration et les bibliothèques.
- Chemin de communication : La connexion entre les nœuds. Cela définit la manière dont les données circulent, souvent en représentant des réseaux tels que LAN, WAN ou Internet.
- Interface : Un point d’interaction où un nœud expose une fonctionnalité à d’autres nœuds ou à des artéfacts.
Lors de la création d’un diagramme, l’objectif est de montrer où se trouvent les artéfacts et comment ils interagissent. Le niveau de détail dépend du public cible. Une vue d’ensemble peut montrer uniquement le cloud et la base de données, tandis qu’une vue détaillée peut montrer des serveurs d’applications individuels et des équilibreurs de charge.
1. Le modèle client-serveur 🖥️
Le modèle client-serveur est la base de la plupart des systèmes informatiques traditionnels. Il sépare l’interface utilisateur et la logique des requêtes (client) de la logique de traitement et de stockage des données (serveur).
Structure du diagramme
- Nœud client : Représente l’appareil de l’utilisateur. Cela peut être un ordinateur de bureau, une tablette ou un téléphone portable. Il héberge l’artéfact de l’interface utilisateur.
- Nœud serveur : Une machine dédiée ou un cluster qui traite les requêtes. Il héberge la logique de l’application et se connecte au stockage.
- Connexion : Généralement un lien réseau étiqueté « HTTP » ou « TCP/IP ».
Caractéristiques clés
- Logique centralisée : Les règles métier résident sur le serveur.
- Clients sans état : Le client ne stocke généralement pas de données importantes de manière permanente.
- Évolutivité : L’évolutivité consiste souvent à ajouter davantage de nœuds serveurs derrière un équilibreur de charge plutôt qu’à mettre à niveau le client.
Ce modèle est facile à visualiser. Il montre clairement la frontière entre l’environnement utilisateur et l’infrastructure backend. Toutefois, dans les contextes modernes, ce modèle évolue souvent vers des structures plus complexes au fur et à mesure que les exigences augmentent.
2. Le modèle Multi-niveaux (N-niveaux) 🏢
À mesure que les applications ont augmenté en complexité, le modèle client-serveur simple à deux niveaux est devenu un goulot d’étranglement. Le modèle multi-niveaux introduit des couches intermédiaires pour séparer les préoccupations, en divisant généralement le système en couches Présentation, Application et Données.
Structure du diagramme
| Couche | Nœud de déploiement | Artéfact principal |
|---|---|---|
| 1. Présentation | Serveur web / Appareil client | HTML, CSS, JavaScript |
| 2. Application | Serveur d’application | Code compilé, logique métier |
| 3. Données | Serveur de base de données | Instance de base de données, Schéma |
Caractéristiques clés
- Séparation des préoccupations : Chaque couche peut être développée, testée et mise à l’échelle indépendamment.
- Sécurité : La couche base de données est souvent isolée de l’internet public, accessible uniquement via la couche application.
- Maintenabilité : Les modifications de l’interface utilisateur n’affectent pas nécessairement la couche données.
Lors de la réalisation de ce diagramme, il est important de montrer le flux de communication. Le client communique avec le serveur web, le serveur web communique avec le serveur d’application, et le serveur d’application communique avec la base de données. Utiliser des nœuds distincts pour chaque couche rend cette séparation visuellement claire.
3. Le modèle Microservices 🧱
L’architecture microservices divise une grande application en services petits et indépendants. Chaque service s’exécute dans son propre processus et communique via des mécanismes légers. Dans un diagramme de déploiement, cela se distingue fortement du modèle monolithique multi-niveaux.
Structure du diagramme
- Nœuds de service : Plusieurs nœuds, chacun hébergeant un microservice spécifique. Ce sont souvent des conteneurs fonctionnant sur une plateforme d’orchestration partagée.
- Passerelle API : Un nœud de point d’entrée unique qui achemine les requêtes vers le service approprié.
- Mesh de services : Nœuds d’infrastructure facultatifs qui gèrent la communication entre services, la sécurité et l’observabilité.
Caractéristiques principales
- Déploiement indépendant : Un service peut être mis à jour sans déployer l’ensemble du système.
- Diversité technologique : Des services différents peuvent utiliser des environnements d’exécution ou des bases de données différents.
- Résilience : Une panne dans un service n’entraîne pas nécessairement la chute de l’ensemble du système.
Visualiser les microservices nécessite une gestion soigneuse des lignes. Trop de connexions créent un « diagramme spaghetti ». Regrouper les services par domaine (par exemple, « Service de commande », « Service utilisateur ») aide à clarifier l’architecture. Il est également courant de montrer une couche d’infrastructure partagée, telle qu’une file d’attente de messages ou un service de journalisation centralisé, qui soutient tous les nœuds.
4. Modèles natifs du cloud et distribués ☁️
Les systèmes modernes reposent souvent sur une infrastructure de cloud public. Ces diagrammes diffèrent des diagrammes locaux car le matériel physique est abstrait. L’accent se déplace vers des régions logiques, des zones de disponibilité et des services gérés.
Structure du diagramme
- Nœuds de région : Grandes zones géographiques où l’infrastructure est déployée.
- Zone de disponibilité : Centres de données distincts au sein d’une région, souvent représentés comme des sous-nœuds.
- Services gérés : Artifacts représentant des services tels que des conteneurs de stockage, des brokers de files d’attente ou des fonctions sans serveur.
Caractéristiques principales
- Élasticité : Les nœuds peuvent s’ajuster automatiquement en fonction de la demande, en montant ou en descendant.
- Redondance : Les composants critiques sont répliqués à travers les zones de disponibilité pour garantir la disponibilité.
- Gestion des coûts : Le diagramme reflète la structure des coûts des ressources cloud (par exemple, paiement à l’utilisation contre instances réservées).
Lors de la réalisation de ces diagrammes, il est utile de regrouper les nœuds par région. Par exemple, afficher une région principale et une région de récupération après sinistre côte à côte. Cela met en évidence la stratégie de basculement. Il est également important de préciser quelles connexions traversent Internet public et lesquelles restent dans le réseau cloud privé.
5. Modèles de calcul en périphérie 🌍
Le calcul en périphérie déplace le traitement plus près de la source des données. Cela est courant dans l’IoT, les jeux vidéo et l’analyse en temps réel. Le diagramme de déploiement de ce modèle s’étend au-delà du centre de données central pour inclure les périphériques périphériques.
Structure du diagramme
- Nœuds périphériques : Des serveurs locaux ou des dispositifs puissants situés près de la source de données (par exemple, une passerelle d’usine, une station de base).
- Cloud central : Le backend principal pour le traitement intensif et le stockage à long terme.
- Connexion de synchronisation : Un lien entre le périphérique et le cloud, souvent asynchrone.
Caractéristiques clés
- Faible latence : Le traitement a lieu localement pour réduire le temps de réponse.
- Efficacité du débit : Seules les données essentielles sont envoyées vers le cloud central.
- Autonomie : Les nœuds périphériques peuvent souvent fonctionner de manière indépendante si la connexion réseau est perdue.
La représentation du calcul périphérique nécessite de montrer la hiérarchie. Le cloud central est la racine, avec des branches menant aux nœuds périphériques régionaux. Cela aide les parties prenantes à comprendre où les données sont traitées et où elles sont stockées. Les considérations de sécurité sont également essentielles ici, car les nœuds périphériques peuvent se trouver dans des emplacements physiques moins sécurisés.
6. Modèles de clusters équilibrés en charge 🔄
La haute disponibilité est une exigence courante pour les systèmes d’entreprise. Ce modèle utilise plusieurs nœuds identiques pour partager la charge de travail et garantir que, si l’un d’entre eux échoue, les autres le remplacent.
Structure du diagramme
- Nœud équilibreur de charge : Un nœud dédié qui répartit le trafic entrant.
- Cluster de serveurs : Un groupe de serveurs d’applications identiques.
- Vérifications d’état : Un lien logique montrant que l’équilibreur de charge surveille l’état des nœuds serveurs.
Caractéristiques clés
- Haute disponibilité : Le système reste opérationnel pendant la maintenance ou en cas de panne matérielle.
- Performance : Le trafic est réparti pour éviter qu’un nœud unique ne devienne un goulot d’étranglement.
- Gestion d’état : Exige une attention particulière quant à la gestion des données de session (par exemple, des sessions persistantes ou un état partagé).
Lors de la représentation de cela, il est courant de dessiner une boîte autour des nœuds du cluster pour indiquer qu’ils fonctionnent comme une unité logique unique. Le chargeur répartiteur se situe à l’extérieur de cette boîte, agissant comme point d’entrée. Cela communique clairement la stratégie de redondance à l’équipe opérationnelle.
7. Modèles d’architecture orientée événements ⚡
Dans les systèmes orientés événements, les composants réagissent aux événements plutôt que d’attendre des requêtes directes. Cela déconnecte le producteur de données du consommateur. Le diagramme de déploiement reflète cette communication asynchrone.
Structure du diagramme
- Nœuds producteurs : Services qui génèrent des événements.
- Nœuds consommateurs : Services qui écoutent et traitent les événements.
- Broker de messages : Un nœud central chargé de router les messages entre les producteurs et les consommateurs.
Caractéristiques principales
- Déconnexion : Les producteurs n’ont pas besoin de savoir quels consommateurs existent.
- Évolutivité : Les consommateurs peuvent être mis à l’échelle indépendamment en fonction de la profondeur de la file d’attente des messages.
- Fiabilité : Les messages sont souvent persistés dans le broker pour éviter la perte de données.
Visualiser ce modèle consiste à représenter le broker de messages comme un centre. Des lignes partent des producteurs vers le broker, puis du broker vers les consommateurs. Marquer ces chemins avec des protocoles spécifiques (comme « MQTT » ou « AMQP ») ajoute de la clarté. Il est également utile de préciser quels consommateurs sont actifs et quels autres sont inactifs.
Comparaison des modèles de déploiement 📊
Pour résumer les différences, le tableau suivant décrit les compromis associés à chaque modèle.
| Modèle | Complexité | Évolutivité | Meilleur cas d’utilisation |
|---|---|---|---|
| Client-Serveur | Faible | Modérée | Outils internes simples |
| Multi-niveaux | Modéré | Élevé | Applications web d’entreprise |
| Microservices | Élevé | Très élevé | Grandes plates-formes en évolution |
| Natif cloud | Modéré | Élastique | SaaS à destination du public |
| Calcul edge | Élevé | Variable | IoT et traitement en temps réel |
| Équilibrage de charge | Modéré | Élevé | Services à disponibilité critique |
| Déclenché par événement | Élevé | Élevé | Flux de travail asynchrones |
Meilleures pratiques pour la création de diagrammes 📝
Créer un diagramme de déploiement est autant une question d’art qu’une tâche technique. Suivre des lignes directrices établies garantit que le diagramme reste utile au fil du temps.
1. Maintenir les niveaux d’abstraction
Un seul diagramme capte rarement tous les détails. Utilisez des vues différentes selon les publics ciblés. La vue exécutive peut montrer les régions et les services majeurs. La vue ingénierie doit afficher des nœuds spécifiques, des ports et des protocoles. N’associez pas ces niveaux dans une seule image.
2. Utiliser des conventions de nommage claires
Les nœuds doivent avoir des noms significatifs. Évitez les étiquettes génériques comme « Nœud 1 » ou « Serveur A ». Utilisez plutôt « Cluster de serveurs web » ou « Base de données de production ». Les artefacts doivent également être nommés pour refléter leur fonction, par exemple « Module de traitement des paiements » plutôt que « App.jar ».
3. Définir les protocoles de communication
Libellez vos connexions. Le fait de savoir qu’un lien est « HTTPS » fournit plus d’informations qu’une ligne générique. Cela aide les équipes de sécurité à identifier les vulnérabilités potentielles et les ingénieurs réseaux à planifier les besoins en bande passante.
4. Indiquez les limites de sécurité
Utilisez des lignes pointillées ou des zones ombrées pour indiquer les zones de sécurité. Marquez clairement les parties du système exposées à Internet public et celles qui sont uniquement internes. Cela est essentiel pour la conformité et l’évaluation des risques.
5. Tenez-le à jour
Un diagramme de déploiement qui ne correspond pas à la réalité est pire qu’aucun diagramme. Intégrez les mises à jour du diagramme dans le pipeline de déploiement. Chaque fois que l’infrastructure change, le diagramme doit être revu et mis à jour.
Erreurs courantes à éviter ⚠️
Même les architectes expérimentés peuvent commettre des erreurs lors de la visualisation de l’infrastructure. Être conscient de ces pièges aide à maintenir la qualité du diagramme.
- Surconception :Inclure chaque serveur physique dans un cluster rend le diagramme illisible. Regroupez-les de manière logique.
- Ignorer la latence :Montrer une connexion entre deux nœuds situés sur des continents différents sans mentionner les implications de latence peut entraîner des problèmes de performance.
- Dépendances manquantes :Ne pas indiquer qu’un service dépend d’une base de données spécifique ou d’un fichier de configuration peut entraîner des échecs de déploiement.
- Représentation statique :Les systèmes cloud sont dynamiques. Évitez de montrer un instantané statique qui suggère une allocation fixe des ressources.
- Confondre le logique et le physique :Assurez-vous que le diagramme représente le déploiement physique, et non seulement les composants logiques. Un composant logique peut exister sur plusieurs nœuds physiques.
Mapper les diagrammes à la réalité de l’infrastructure 🌐
Un diagramme de déploiement est un modèle. Il doit finalement se traduire en infrastructure réelle. Ce processus de traduction implique plusieurs étapes :
- Dimensionnement des ressources :Sur la base des nœuds du diagramme, déterminez les besoins en CPU, mémoire et stockage.
- Configuration du réseau :Les chemins de communication déterminent les règles du pare-feu, les sous-réseaux et les tables de routage.
- Automatisation :L’infrastructure moderne utilise du code pour définir le diagramme. Les outils permettent de définir les nœuds et les connexions dans des fichiers texte, qui provoquent ensuite le provisionnement de l’environnement réel.
- Surveillance :Les nœuds du diagramme doivent correspondre aux entités surveillées. Si un nœud n’est pas surveillé, il n’est pas visible pour l’équipe opérationnelle.
Cette alignement garantit que l’intention du design est préservée pendant l’implémentation. Si le diagramme montre un équilibreur de charge, le script de provisionnement doit en créer un. Si le diagramme montre une réplica de base de données, l’infrastructure doit la supporter.
Conclusion 🏁
Les diagrammes de déploiement sont des outils essentiels pour communiquer la structure physique des systèmes logiciels. En comprenant les modèles courants — des modèles client-serveur simples aux architectures complexes de microservices et de calculs aux bords — les équipes peuvent concevoir des architectures plus robustes et maintenables.
La clé du succès réside dans la clarté. Un bon schéma répond aux questions avant même qu’elles ne soient posées. Il montre où les données sont stockées, comment elles se déplacent et ce qui se produit lorsque les choses tournent mal. En suivant les meilleures pratiques et en évitant les pièges courants, les architectes peuvent créer des schémas qui servent de guides fiables tout au long du cycle de vie d’un système.
Que vous planifiiez une nouvelle infrastructure ou que vous documentiez une existante, l’application de ces modèles garantit que la représentation visuelle correspond à la réalité technique. Cette alignement est la fondation d’une livraison logicielle fiable.

