












Dans le paysage de l’architecture logicielle, peu d’artefacts sont aussi mal compris que le diagramme de déploiement. Souvent relégués à la poubelle de la documentation obsolète ou rejetés comme de simples cartes de topologie réseau, ces diagrammes détiennent un pouvoir considérable lorsqu’ils sont correctement compris. Ils servent de pont entre le code abstrait et l’infrastructure physique. Ce guide vise à clarifier les idées fausses qui entourent ces diagrammes, en offrant une voie claire pour une modélisation précise du système.
🧐 Comprendre le but fondamental
Un diagramme de déploiement représente le matériel physique ou virtuel sur lequel un système logiciel s’exécute. Il visualise l’architecture en temps réel. De nombreux professionnels le confondent avec une architecture logique ou un diagramme réseau. Il est essentiel de distinguer la vue de déploiement des autres perspectives de modélisation.
- Vue logique : Se concentre sur les composants et leurs relations.
- Vue de déploiement : Se concentre sur les nœuds, les artefacts et les chemins de communication.
- Vue réseau : Se concentre sur les adresses IP, les sous-réseaux et les pare-feu.
Bien que ces vues se chevauchent, le diagramme de déploiement traite spécifiquement de l’environnement d’exécution. Il répond à la question : « Où ce code est-il hébergé, et comment communique-t-il avec les autres services ? »
🚫 Les mythes courants
Plusieurs croyances persistantes concernant les diagrammes de déploiement entravent la conception efficace des architectures. Examinons les plus répandues et comparons-les à la réalité technique.
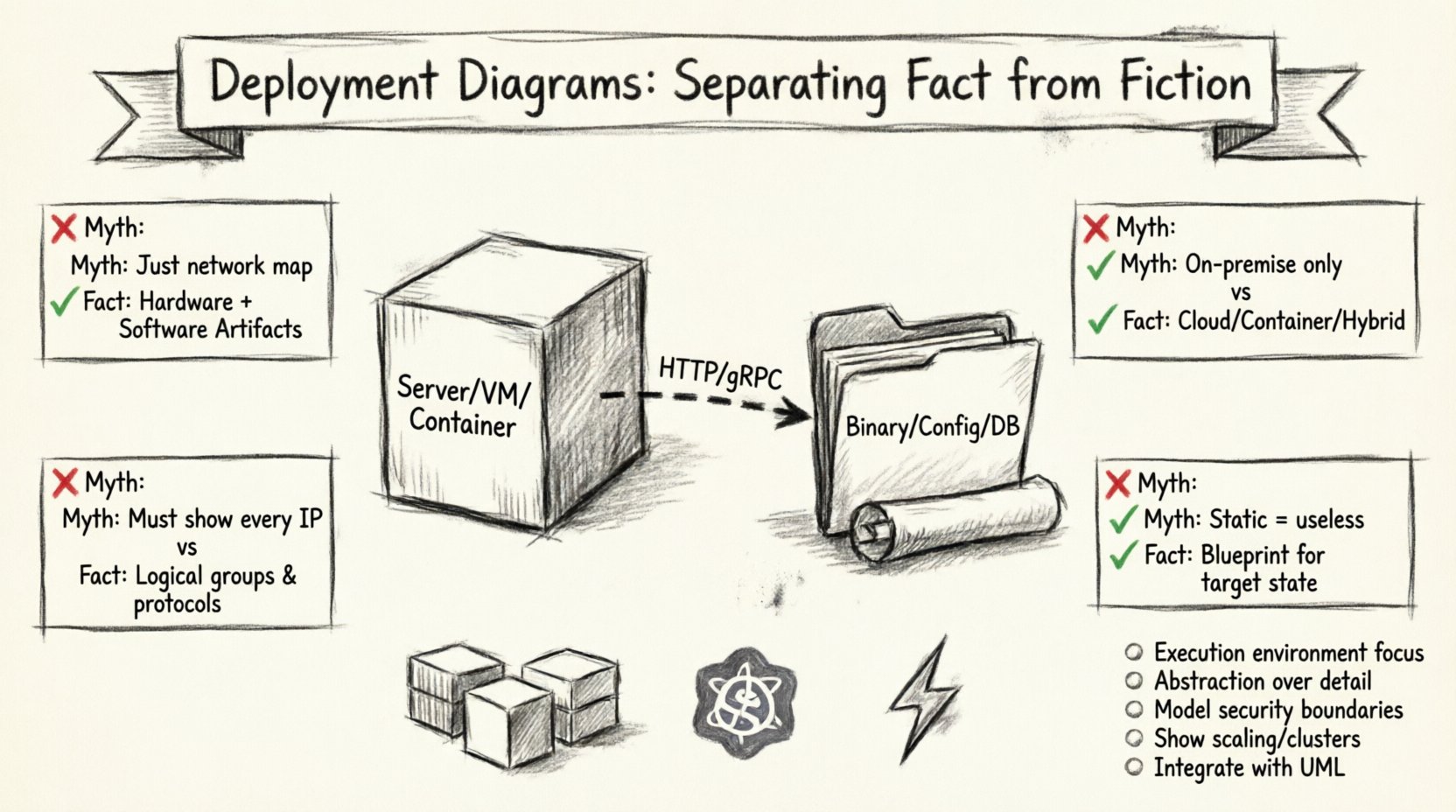
Mythe 1 : C’est simplement une carte de topologie réseau 🌐
Le mythe : Beaucoup pensent que ce diagramme est simplement une carte des serveurs, des routeurs et des câbles.
Le fait : Bien qu’il inclue des nœuds matériels, l’accent principal est mis sur les artefacts logiciels déployés sur ces nœuds. Un nœud sans artefact est une coquille. Le diagramme doit montrer quel logiciel fonctionne sur l’infrastructure.
- Nœud : Représente une ressource de calcul (par exemple, un serveur, un conteneur ou un périphérique).
- Artéfact : Représente l’implémentation physique d’un composant logiciel (par exemple, un fichier binaire, un script ou une bibliothèque).
- Association : Montre comment les artefacts sont déployés sur les nœuds.
Mythe 2 : Seulement pertinent pour les systèmes locaux 🖥️
Le mythe :Le cloud computing a rendu les diagrammes statiques obsolètes car l’infrastructure est éphémère.
Le fait : Les environnements cloud sont encore des environnements. Que ce soit physiques ou virtualisés, chaque déploiement nécessite une définition de l’emplacement où les processus s’exécutent. Les architectures cloud modernes reposent souvent sur une orchestration complexe, ce qui rend la vue du déploiement encore plus critique pour comprendre les politiques d’évolutivité et les chaînes de dépendances.
Mythe 3 : Ils doivent être parfaitement détaillés ⚙️
La fiction :Un bon diagramme doit montrer chaque adresse IP et chaque configuration de port.
Le fait :Les diagrammes sont des abstractions. Trop de détails entraîne des cauchemars de maintenance. L’objectif est la communication, pas la spécification de chaque paramètre de configuration. Les diagrammes de déploiement de haut niveau se concentrent sur des nœuds logiques (par exemple, « Cluster de serveurs web ») plutôt que sur des spécifications matérielles précises.
Mythe 4 : Les diagrammes statiques ne peuvent pas représenter des systèmes dynamiques 🔄
La fiction :Parce que les systèmes évoluent et se déplacent, un dessin statique est inutile.
Le fait :Les diagrammes de déploiement représentent l’état cible ou la configuration de base.état cible ou la configuration de base. Ils décrivent l’architecture souhaitée. Les changements dynamiques sont gérés grâce aux procédures opérationnelles, mais le plan architectural reste valable.
📊 Fait vs. Fiction : Une comparaison détaillée
| Aspect | Mythe courant (Fiction) | Réalité technique (Fait) |
|---|---|---|
| Portée | Topologie réseau uniquement | Matériel + Artifacts logiciels |
| Environnement | Serveurs physiques uniquement | Virtual, Conteneur, Cloud ou Hybride |
| Niveau de détail | Toute adresse IP et port | Groupes logiques et protocoles |
| Utilité | Documentation statique | Plan directeur pour le déploiement et l’évolutivité |
| Outils | Dessin manuel uniquement | Outils intégrés pilotés par modèle |
🏗️ Anatomie d’un diagramme de déploiement
Pour construire un diagramme significatif, il faut comprendre les éléments standards utilisés pour représenter le système. Ces éléments respectent des normes établies de modélisation.
1. Nœuds 📦
Un nœud est une ressource informatique physique ou virtuelle. Dans un contexte moderne, cela pourrait être :
- Un serveur physique dans un centre de données.
- Une instance de machine virtuelle.
- Un environnement d’exécution de conteneurs.
- Un appareil mobile ou un capteur IoT.
Les nœuds sont souvent regroupés pour représenter des clusters ou des régions. Par exemple, un groupe de nœuds « Web Tier » pourrait contenir plusieurs instances identiques pour gérer l’équilibrage de charge.
2. Artifacts 📄
Un artifact est une pièce physique d’information utilisée ou produite par un processus de développement logiciel. Dans le contexte du déploiement, il s’agit du produit livrable qui s’exécute sur un nœud.
- Exécutables :Binaires compilés ou scripts.
- Bibliothèques :Dépendances de code partagées.
- Fichiers de configuration :Paramètres qui définissent le comportement.
- Bases de données :Schémas de données stockés.
Les artifacts sont déployés sur les nœuds à l’aide de relations de déploiement. Cela précise quel logiciel s’exécute sur quel matériel.
3. Chemins de communication 📡
Les nœuds n’existent pas en isolation. Ils communiquent via des protocoles. Le diagramme doit montrer comment les données circulent entre les composants.
- Protocoles réseau :HTTP, TCP/IP, gRPC.
- Middleware :Files d’attente de messages ou passerelles API.
- Couches de sécurité : Pare-feu ou points de terminaison de chiffrement.
Il est essentiel d’étiqueter ces chemins avec le protocole utilisé pour comprendre les contraintes de latence et de sécurité.
☁️ Déploiement à l’ère du cloud
Le passage vers des architectures nativement cloud a introduit de nouvelles complexités. Le modèle traditionnel de « un serveur, une application » s’est transformé en microservices, conteneurs et fonctions sans serveur.
Implications de la conteneurisation
Lorsque l’on utilise des runtimes de conteneurs, le diagramme de déploiement change légèrement. L’artefact n’est plus seulement un binaire ; il s’agit d’une image conteneur. Le nœud pourrait être une machine hôte exécutant un gestionnaire de cluster.
- Pod/Conteneur : La plus petite unité déployable.
- Orchestrateur : Gère le cycle de vie des conteneurs.
- Service Mesh : Gère la communication entre services.
Il est essentiel de représenter correctement la couche d’abstraction. Afficher une image conteneur déployée sur un nœud est plus précis que de montrer un serveur générique exécutant un script.
Architectures sans serveur
Dans les modèles sans serveur, le concept de nœud est abstrait par la plateforme. Le diagramme se concentre sur les fonctions et les déclencheurs qui les activent.
- Fonction : L’unité de code.
- Déclencheur : La source d’événement (par exemple, requête HTTP, modification de base de données).
- Stockage : Où les données persistent.
Même en l’absence de nœuds visibles, le diagramme de déploiement reste valide en se concentrant sur les points d’exécution logiques.
🛠️ Meilleures pratiques pour la construction
Créer des diagrammes efficaces exige de la discipline. Suivre des directives établies garantit que l’artefact reste utile dans le temps.
1. Définir le public 👥
Qui va lire ce diagramme ? Un ingénieur DevOps a besoin de détails différents d’un chef de projet.
- Pour les développeurs : Se concentrer sur les dépendances entre composants et les chemins de déploiement.
- Pour les opérations : Concentrez-vous sur les nœuds, les équilibreurs de charge et les points de surveillance.
- Pour les parties prenantes : Concentrez-vous sur les niveaux élevés et les centres de coûts.
2. Maintenez les niveaux d’abstraction 📏
N’associez pas les détails de haut niveau et de bas niveau dans la même vue. Si vous montrez des nœuds logiques, n’encombrez pas la vue avec des adresses IP spécifiques. Utilisez des diagrammes distincts pour différents niveaux de granularité.
3. Contrôlez les versions de vos modèles 📂
Tout comme le code, les diagrammes d’architecture évoluent. Traitez-les comme des artefacts versionnés. Suivez les modifications apportées aux nœuds et aux relations au fil du temps pour auditer l’évolution du système.
4. Intégrez avec d’autres diagrammes 🔗
Un diagramme de déploiement ne doit pas exister en isolation. Il se connecte à :
- Diagrammes de composants : Montre ce qui se trouve à l’intérieur des nœuds.
- Diagrammes de séquence : Montre le flux d’interaction en temps réel.
- Diagrammes de classes : Montre la structure interne des artefacts.
🚨 Pièges courants à éviter
Même les architectes expérimentés commettent des erreurs lors de la modélisation du déploiement. Reconnaître ces erreurs tôt permet d’éviter la dette technique.
Piège 1 : Ignorer les frontières de sécurité 🔒
Beaucoup de diagrammes montrent des connexions sans indiquer les zones de sécurité. Il est essentiel de distinguer les nœuds exposés au public des nœuds internes.
- DMZ : Services accessibles publiquement.
- Réseau interne : Infrastructure fiable.
- Réseau privé : Stockage de données et traitement sensible.
Piège 2 : Ignorer la latence et la bande passante ⏱️
Si deux nœuds se trouvent dans des régions différentes, le chemin de communication n’est pas équivalent à un lien local. Les annotations concernant l’emplacement et les contraintes réseau aident les développeurs à comprendre les implications sur les performances.
Piège 3 : Oublier de montrer l’évolutivité 📈
Un dessin d’un seul nœud implique un point de défaillance unique. Dans les systèmes de production, les nœuds critiques doivent être représentés sous forme de clusters ou de groupes pour indiquer la redondance et les capacités d’évolutivité horizontale.
Piège 4 : Négliger les exigences non fonctionnelles 📉
Les diagrammes de déploiement doivent tenir compte des besoins non fonctionnels tels que la disponibilité, la fiabilité et la maintenabilité. Ceux-ci sont souvent représentés à l’aide de types de nœuds spécifiques ou de protocoles de connexion.
🔍 Approfondissement : Relations de déploiement des artefacts
La relation entre un artefact et un nœud est au cœur du diagramme. Comprendre la cardinalité de cette relation est essentiel.
- 1 vers 1 : Une instance d’artefact par nœud (par exemple, un service autonome).
- 1 vers plusieurs : Un type d’artefact déployé sur de nombreux nœuds (par exemple, une application web sur un cluster).
- Plusieurs vers 1 : Plusieurs artefacts sur un seul nœud (par exemple, une base de données et un serveur d’applications sur une seule machine).
Une clarté ici évite toute confusion au déploiement. Si une équipe sait exactement quel artefact va sur quel nœud, les scripts de déploiement automatisés deviennent plus fiables.
📝 Maintenance et cycle de vie
Les diagrammes s’usent. S’ils ne sont pas mis à jour, ils deviennent trompeurs. Une stratégie de maintenance est essentielle.
- Déclencher les mises à jour : Mettre à jour le diagramme lorsque l’architecture change de manière significative.
- Cycles de revue : Intégrer la revue du diagramme au processus d’enregistrement des décisions architecturales.
- Outils : Utiliser des outils qui permettent la génération de diagrammes à partir de code, lorsque cela est possible, afin de les maintenir synchronisés avec l’infrastructure.
🌟 La valeur d’une modélisation précise
Lorsqu’elles sont correctement réalisées, les diagrammes de déploiement sont des outils puissants. Ils facilitent la communication entre les équipes. Ils mettent en évidence les goulets d’étranglement avant qu’ils ne surviennent. Ils servent de plan directeur pour la planification de la récupération après sinistre.
En séparant le fait de la fiction, les équipes peuvent tirer parti de ces diagrammes pour construire des systèmes plus résilients. L’effort investi dans une modélisation précise rapporte des bénéfices lors des incidents et des événements d’évolutivité.
📌 Points clés
- Les diagrammes de déploiement représentent l’environnement d’exécution, et non seulement le réseau.
- Ils restent pertinents dans les environnements cloud et conteneurisés.
- L’abstraction est essentielle ; évitez les détails inutiles.
- Les frontières de sécurité et le dimensionnement doivent être explicitement modélisés.
- L’intégration avec d’autres diagrammes UML crée une image complète.
Adopter une compréhension claire de ces principes améliore la qualité de la conception du système. Cela déplace la conversation du hasard vers une précision ingénieuse.

