












Dans le paysage de la modélisation des processus métiers, la clarté n’est pas simplement un choix esthétique ; c’est une nécessité fonctionnelle. Lorsque les parties prenantes tentent de visualiser le déplacement du travail à travers une organisation, l’ambiguïté peut entraîner des goulets d’étranglement, des efforts redondants et des ruptures de communication. La norme Business Process Model and Notation (BPMN) offre un cadre solide pour représenter ces flux de travail. Parmi ses éléments structurels les plus critiques figurent les pools et les lignes. Ces composants constituent le socle de la définition de qui fait quoi, en garantissant que chaque étape du processus soit attribuée au bon acteur.
Ce guide explore les mécanismes, les sémantiques et les meilleures pratiques entourant les pools et les lignes. En comprenant comment structurer efficacement ces éléments, les modélisateurs peuvent créer des diagrammes qui sont non seulement visuellement compréhensibles, mais aussi opérationnellement précis. Nous examinerons les fondements théoriques, les applications pratiques et les pièges courants à éviter lors de l’organisation des responsabilités.
🏊 Définition du pool
Un pool représente un participant dans un processus métier. Dans le contexte d’un diagramme BPMN, un pool est le conteneur qui contient le flux privé des activités appartenant à une entité spécifique. Il définit les limites de l’implication de cette entité dans l’interaction.
Qu’est-ce qu’un participant ?
Le concept de participant est souple. Il peut représenter divers niveaux d’une organisation ou d’un système, selon le périmètre du modèle :
- Unités organisationnelles : Un département spécifique, tel que « Finance » ou « Ressources humaines ».
- Entités externes : Un client, un fournisseur ou un organisme régulateur.
- Systèmes : Une application automatisée, une base de données ou un mainframe hérité.
- Individus : Dans certains contextes, un rôle ou une personne spécifique, bien que cela soit souvent mieux géré au sein des lignes.
Visuellement, un pool est représenté par un grand rectangle. Lorsqu’il existe plusieurs pools sur un même diagramme, ils représentent une collaboration. L’interaction entre ces pools est le point central du modèle.
Types de pools
Il existe deux façons distinctes d’utiliser les pools dans la modélisation des processus :
- Pools de collaboration : Ils sont utilisés lorsqu’on modélise les interactions entre plusieurs participants. Par exemple, un processus montrant l’échange d’informations entre un pool « Client » et un pool « Banque ».
- Pools de processus privés : Ils contiennent la logique interne d’un seul participant. Les activités internes sont masquées au monde extérieur, se concentrant uniquement sur le flux interne de cette entité spécifique.
Comprendre la distinction est essentiel. Un pool privé se concentre sur l’efficacité interne, tandis qu’un pool de collaboration se concentre sur les interfaces et les transferts.
🚣 Définition de la ligne
Si un pool représente l’organisation, les lignes qu’il contient représentent les sous-groupes ou les rôles chargés d’exécuter des tâches spécifiques. Les lignes sont des subdivisions horizontales ou verticales à l’intérieur d’un pool. Elles permettent une décomposition fine des responsabilités.
Rôles vs. Départements
Les lignes fournissent un mécanisme pour séparer les activités en fonction de qui les exécute. Cette séparation est cruciale pour identifier les transferts. Un transfert a lieu lorsqu’une tâche passe d’une ligne à une autre, souvent en indiquant un changement de propriété ou un délai potentiel.
Les utilisations courantes des lignes incluent :
- Rôles fonctionnels : « Responsable », « Analyste », « Agent service client ».
- Unités départementales : « Ventes », « Logistique », « Assurance qualité ».
- Composants du système : « Frontend », « Backend », « Base de données ».
Rangs imbriqués
BPMN permet des rangs à l’intérieur de rangs. Cela est utile pour les hiérarchies organisationnelles profondes. Par exemple, un pool principal pourrait représenter « Département informatique », avec un rang pour « Développement », et un sous-rang à l’intérieur de celui-ci pour « Équipe Backend ». Bien que puissant, un imbriquage excessif peut rendre les diagrammes difficiles à lire. Il est souvent préférable de diviser le pool principal en plusieurs pools si la hiérarchie devient trop profonde.
🔄 Mécaniques d’interaction
La relation entre les pools et les rangs détermine la manière dont les flux sont dessinés. Le type de flux utilisé dépend de si l’activité reste au sein du même participant ou traverse des frontières.
Flux de séquence
Les flux de séquence représentent l’ordre des activités. Ce sont des lignes pleines avec des flèches. De façon cruciale, les flux de séquence sont généralement contenus dans un seul pool. Si un flux de séquence traverse une frontière de pool, cela implique une synchronisation qui n’est pas techniquement standard sans un événement à la frontière ou un flux de message.
- Dans un rang : Indique un transfert direct entre des tâches effectuées par le même rôle.
- Entre des rangs (même pool) : Indique un transfert de tâche entre des rôles différents au sein de la même organisation. C’est une source courante de délai et doit être minimisée lorsque cela est possible.
Flux de message
Les flux de message sont des lignes pointillées avec des flèches ouvertes. Ils représentent l’échange d’information entre les participants. Ces flux relient des pools, et non des rangs.
- Traverser les frontières des pools : Un flux de message doit toujours relier un pool à un autre pool. Il ne peut pas relier directement un rang à un rang dans un autre pool, bien qu’il relie effectivement les participants auxquels appartiennent ces rangs.
- Artéfacts de communication : Ces flux représentent souvent des courriels, des appels d’API ou des documents physiques qui se déplacent entre des entités.
📋 Meilleures pratiques pour la structure
Pour garantir qu’un modèle reste maintenable et compréhensible, respectez les directives suivantes concernant les pools et les rangs.
1. Limiter le nombre de pools
Bien que les diagrammes de collaboration puissent impliquer de nombreux participants, un seul diagramme avec trop de pools devient visuellement encombré. Si un processus implique plus de cinq participants distincts, envisagez de diviser le modèle en plusieurs diagrammes ou de vous concentrer sur des interactions spécifiques.
2. Conventions de nommage cohérentes
Les noms des rangs doivent être cohérents dans l’ensemble du modèle. Si vous utilisez « Équipe Ventes » dans un diagramme, ne pas utiliser « Service Ventes » dans un autre. La cohérence facilite la navigation et réduit la charge cognitive pour le lecteur.
3. Équilibrer la largeur des rangs
Visuellement, les rangs doivent être relativement équilibrés. Si un rang contient une quantité importante d’activité tandis qu’un autre est vide, cela suggère un déséquilibre de responsabilité ou une étape de processus manquante. Ajustez le processus ou la structure des rangs pour refléter la réalité.
4. Éviter les croisements de flux de séquence
Les flux de séquence ne doivent pas croiser les frontières des rangs. Si une tâche dans le rang A doit transmettre le contrôle au rang B, le flux doit aller de la tâche dans le rang A vers un événement intermédiaire ou une passerelle, puis reprendre dans le rang B. Ce repère visuel met clairement en évidence le point de transfert.
5. Définir des points d’entrée et de sortie clairs
Chaque filet devrait avoir un point de départ clair où le travail y entre et un point d’arrivée où le travail en sort. Si un filet n’a pas d’événement de départ, cela signifie que le travail commence de l’extérieur. Si un filet n’a pas d’événement de fin, le processus pourrait être incomplet.
🛑 Erreurs courantes de modélisation
Même les modélisateurs expérimentés peuvent tomber dans des pièges lors de l’organisation des responsabilités. Le tableau ci-dessous décrit les erreurs fréquentes et leurs conséquences.
| Erreur | Conséquence | Correction |
|---|---|---|
| Ignorer les événements limites | Absence de gestion des erreurs ou de délais d’attente. | Utilisez les événements limites pour indiquer les exceptions au sein d’un filet spécifique. |
| Flux de séquence entre pools | Implique un transfert direct de contrôle entre des organisations. | Remplacez-les par des flux de messages pour représenter la communication. |
| Trop de filets | Le diagramme devient illisible et complexe. | Regroupez les rôles liés ou divisez le diagramme en sous-processus. |
| Absence d’événements de départ | Le point de départ du processus n’est pas clair. | Assurez-vous qu’il existe un événement de départ défini pour chaque pool. |
| Filets non étiquetés | Ambiguïté quant à qui exécute les tâches. | Attribuez toujours un nom descriptif à chaque filet. |
🧩 Gestion de la complexité dans les grands modèles
À mesure que les processus grandissent, le nombre de pools et de filets peut augmenter rapidement. Cette complexité peut masquer le véritable déroulement du travail. Voici des stratégies pour gérer les diagrammes à grande échelle.
Sous-processus
Lorsqu’un filet contient une séquence complexe de tâches, encapsulez cette logique dans un sous-processus réduit. Cela maintient le diagramme principal propre. Les détails internes peuvent être consultés sur une page ou un onglet distinct, tout en conservant la vue d’ensemble des responsabilités.
Gestion des filets
Dans les grands diagrammes à filets, il est courant que les filets s’étendent sur plusieurs pages. Assurez-vous que les en-têtes de filets sont répétés ou clairement marqués afin de maintenir le contexte pendant que le lecteur fait défiler ou navigue entre les pages. Un filet représentant « Finance » à la page un ne doit pas être confondu avec un autre filet « Finance » à la page deux.
Concentrez-vous sur les transferts
Dans les modèles complexes, les points les plus critiques sont les transferts entre les filets. Mettez ces zones en évidence. Ce sont là que les retards surviennent généralement et où la responsabilité peut devenir floue. Assurez-vous que chaque transition entre les filets est explicitement définie par un flux ou un événement.
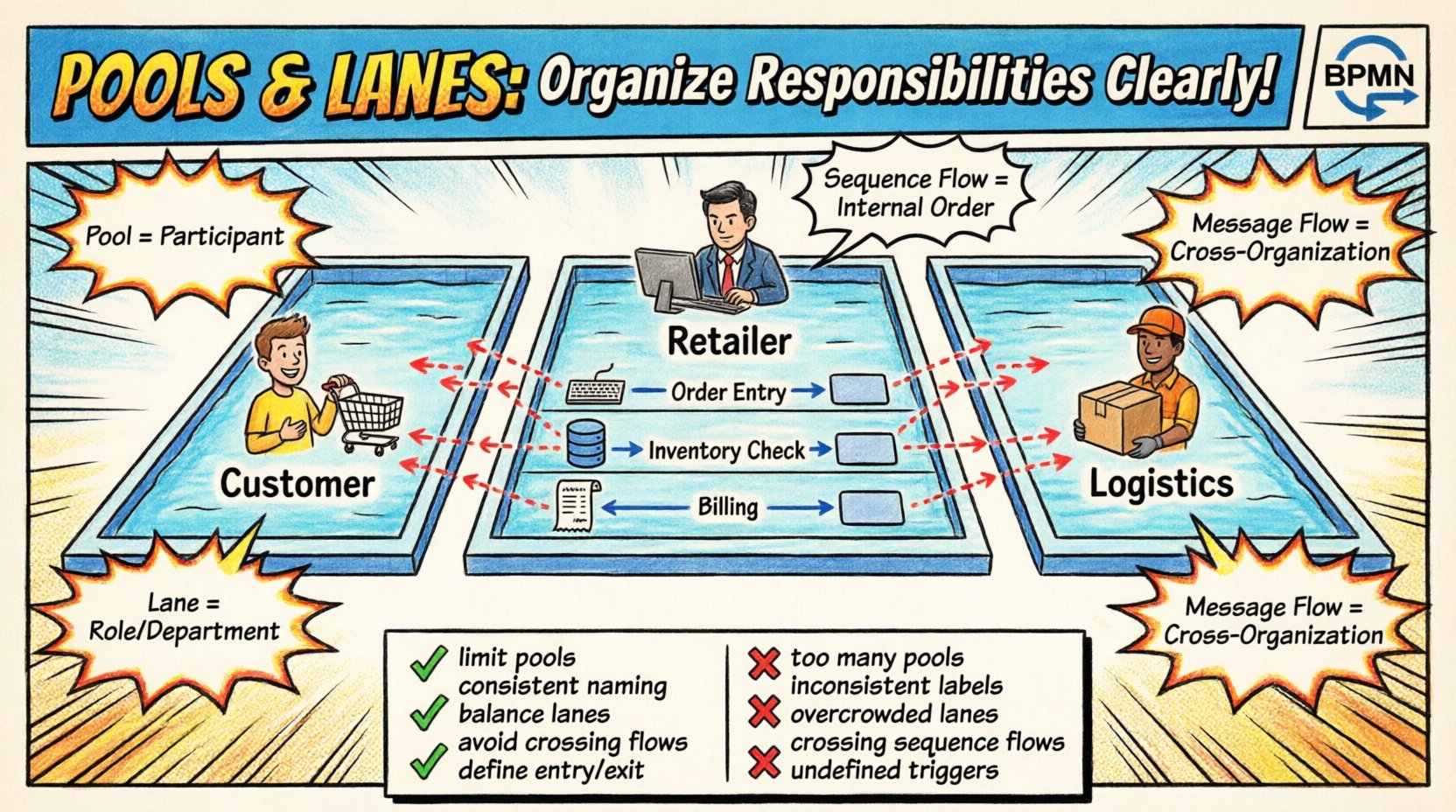
📦 Étude de cas : Flux de traitement des commandes
Pour illustrer ces concepts, envisagez un scénario « commande à paiement » impliquant plusieurs participants.
- Pool 1 : Client
- Ligne : Acheteur
- Pool 2 : Revendeur
- Ligne : Saisie de commande
- Ligne : Vérification des stocks
- Ligne : Facturation
- Pool 3 : Logistique
- Ligne : Entrepôt
Dans ce modèle :
- La Acheteur soumet une commande (flux de message vers le revendeur).
- La Saisie de commande ligne la reçoit et valide les données (flux de séquence).
- Le contrôle passe à la Vérification des stocks ligne (flux de séquence entre les lignes).
- Si les stocks sont disponibles, Facturation est déclenchée.
- Une confirmation est envoyée au Entrepôt dans le pool Logistique (flux de message).
- Le entrepôt expédie les marchandises (flux de séquence).
- Une notification d’expédition est envoyée en retour au Acheteur (flux de message).
Cette structure met clairement en évidence que le détaillant gère la logique interne, tandis que le client et la logistique interagissent de l’extérieur. Chaque voie au sein du pool du détaillant détient une phase spécifique de la transaction.
🔍 Précision sémantique dans BPMN
Le pouvoir du BPMN réside dans sa précision sémantique. Les pools et les voies ne sont pas seulement des outils visuels ; ils portent un sens spécifique concernant l’état et le contrôle.
Contrôle vs. Information
Différenciez le flux de contrôle du flux d’information. Les flux de séquence au sein des voies représentent souvent le contrôle (qui effectue l’étape suivante). Les flux de message entre les pools représentent l’information (ce qui est partagé). Confondre ces deux éléments conduit à une logique de processus incorrecte.
Gestion d’état
Une voie peut conserver un état. Par exemple, une voie « Approbation » peut conserver une tâche jusqu’à ce qu’une décision soit prise. Le pool conserve l’état global du processus. Comprendre où réside l’état aide au débogage des instances de processus. Si un processus est bloqué, vérifiez la voie où la tâche est actuellement en attente.
📈 Conclusion
Une modélisation de processus efficace repose fortement sur une utilisation correcte des pools et des voies. Ces structures fournissent le cadre nécessaire pour attribuer la propriété, définir les limites et illustrer les interactions. En suivant les bonnes pratiques et en évitant les pièges courants, les modélisateurs peuvent créer des diagrammes qui servent de plans fiables pour les opérations commerciales.
Souvenez-vous que l’objectif est la clarté. Si un intervenant regarde le diagramme et ne peut pas identifier qui est responsable d’une tâche, le modèle a échoué. Des revues régulières de la structure, en s’assurant que les voies sont équilibrées et que les pools sont nécessaires, permettront de maintenir l’intégrité du modèle de processus au fil du temps.

