












Dans le monde complexe du modèle et de la notation des processus métiers (BPMN), le flux de contrôle est conçu pour être linéaire et prévisible. Toutefois, les opérations du monde réel sont rarement aussi simples. Les systèmes tombent en panne, la validation des données échoue, et les dépendances externes deviennent hors ligne. C’est là queles événements d’erreurdeviennent critiques. Ils fournissent un mécanisme normalisé au sein de la spécification BPMN pour gérer les exceptions sans compromettre l’intégrité de l’ensemble du modèle de processus.
Une gestion efficace des exceptions ne consiste pas à prédire chaque échec. Elle consiste à définir un chemin clair lorsque les choses tournent mal. Ce guide explore les mécanismes, les configurations et l’application stratégique des événements d’erreur afin de garantir que vos flux de travail restent résilients. Nous examinerons comment distinguer les différents types de déclencheurs d’erreurs, configurer correctement les codes d’erreur, et maintenir une conception de processus propre.
Comprendre le concept fondamental des événements d’erreur ⚙️
Un événement d’erreur est un type spécifique d’événement déclenché par une condition d’échec au sein du processus ou de l’environnement. Contrairement aux événements de message qui reposent sur une communication externe, ou aux événements de signal qui sont diffusés à l’ensemble du moteur, les événements d’erreur sont étroitement liés au flux d’exécution d’une tâche ou d’une activité spécifique.
Lorsqu’une instance de processus rencontre un problème, le moteur doit savoir où rediriger l’exécution. Les événements d’erreur agissent comme des panneaux indicateurs pour cette redirection. Ils permettent au modèle de séparer le chemin normal (exécution normale) du chemin d’exception (gestion des erreurs).
Les caractéristiques clés incluent :
- Spécificité : Ils sont généralement attachés à des tâches connues pour être sujettes aux pannes.
- Propagation : Ils peuvent remonter la hiérarchie si ils ne sont pas capturés localement.
- Normalisation : Ils suivent la spécification BPMN 2.0 pour assurer l’interopérabilité.
Types d’événements d’erreur dans BPMN 📋
Il existe deux façons principales de mettre en œuvre la gestion des erreurs dans un diagramme de flux de travail. Le choix du bon modèle dépend du niveau de granularité de l’échec que vous souhaitez capturer.
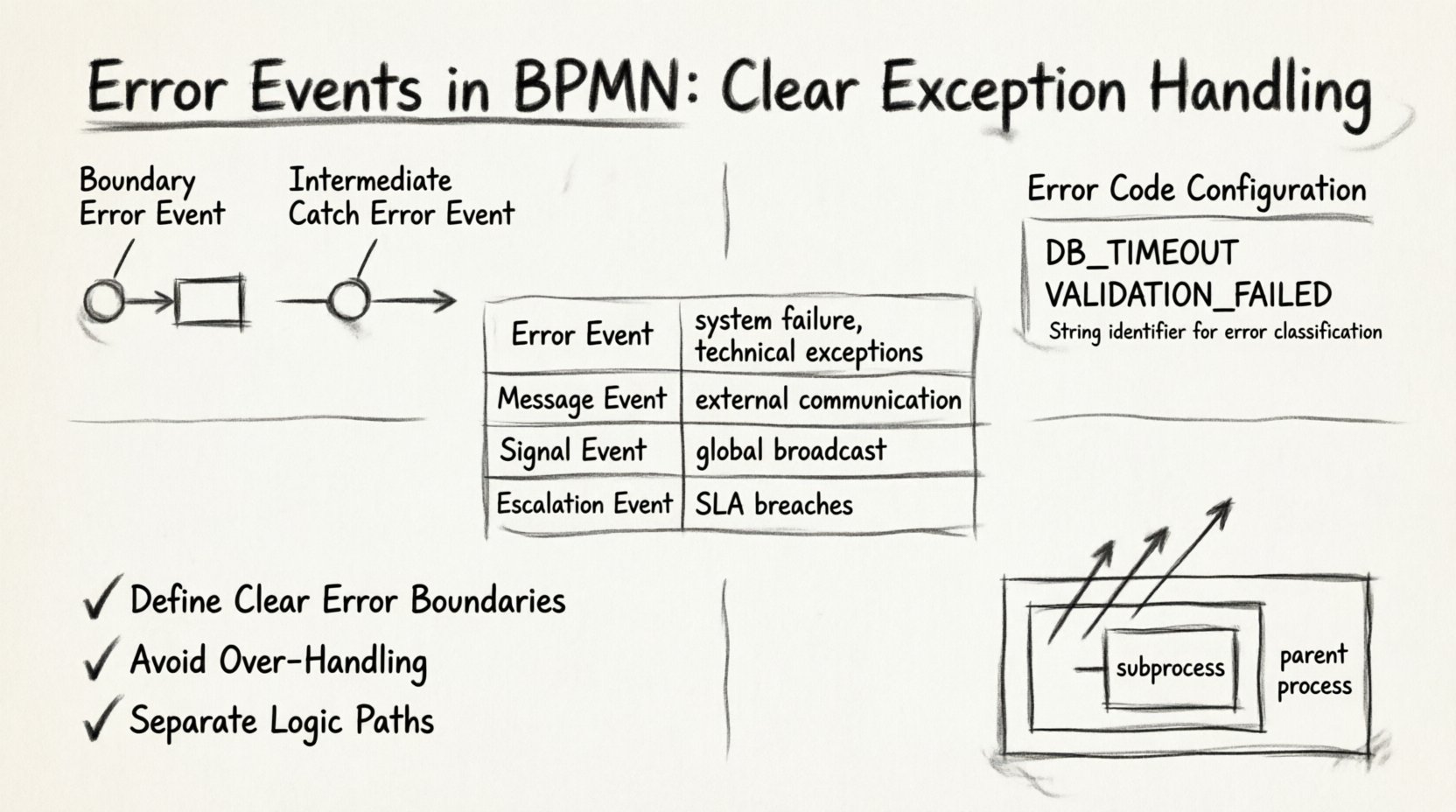
1. Événements d’erreur aux limites 🎯
Un événement d’erreur aux limites est directement attaché à la limite d’une tâche, d’un sous-processus ou d’une activité d’appel. Il représente un gestionnaire d’exceptions local. Si la tâche s’exécute et lance une erreur, le flux est immédiatement redirigé vers le chemin connecté à l’événement aux limites.
C’est le modèle le plus courant pour gérer des échecs spécifiques. Il vous permet d’isoler l’erreur dans le cadre de l’activité. Par exemple, si une opération d’écriture dans la base de données échoue, un événement aux limites peut capturer cet échec spécifique sans interrompre toute l’instance de processus.
Avantages des événements aux limites :
- Encapsulation : La logique de gestion des exceptions est visuellement située à côté de la tâche qu’elle protège.
- Non-bloquant : La tâche principale continue jusqu’à ce que l’erreur survienne.
- Clarté : Le diagramme montre clairement quelles tâches disposent de mécanismes de secours.
2. Événements d’erreur intermédiaires de capture 🔄
Un événement d’erreur intermédiaire de capture est situé sur le flux de séquence, plutôt que fixé à la limite d’une tâche. Ce type est moins courant, mais utile pour gérer les erreurs qui surviennent entre les tâches ou au sein d’un sous-processus qui doit être capturé dans la portée parente.
Cette approche est souvent utilisée lorsque vous souhaitez capturer des erreurs qui remontent depuis un sous-processus mais n’ont pas encore atteint la limite du processus principal. Elle permet une gestion centralisée des erreurs pour un bloc spécifique de logique.
Configuration et attributs ⚙️
Pour rendre les événements d’erreur fonctionnels, ils nécessitent une configuration spécifique dans l’outil de modélisation et dans le moteur d’exécution. Ces configurations définissent ce qui constitue une erreur et la manière dont le système réagit.
Définition du code d’erreur
Chaque événement d’erreur doit avoir un code unique Code d’erreur. Il s’agit d’un identifiant de chaîne de caractères qui distingue un type d’erreur d’un autre. Sans un code défini, le moteur ne peut pas distinguer un délai d’attente de base de données d’une erreur de validation.
- Identifiant de chaîne : Utilisez une convention de nommage cohérente, telle que
DB_TIMEOUTouVALIDATION_FAILED. - Granularité : Évitez les codes génériques tels que
ERROR_1. Utilisez des identifiants descriptifs qui facilitent le débogage. - Mappage : Assurez-vous que le système externe ou le script lance exactement le code défini dans l’événement.
Association de message
Certaines implémentations permettent d’associer un événement d’erreur à une définition de message spécifique. Cela lie l’erreur à un message lisible par l’humain pouvant être affiché dans une interface utilisateur ou enregistré.
- Retour utilisateur : Permet au système d’indiquer précisément à l’utilisateur ce qui s’est mal passé.
- Journalisation : Facilite les systèmes de journalisation automatisés pour catégoriser les incidents par type d’erreur.
Comparaison des stratégies de gestion des erreurs 📊
Comprendre où s’inscrivent les événements d’erreur dans le contexte plus large du BPMN est essentiel. Ci-dessous se trouve une comparaison des types d’événements pour clarifier quand utiliser un événement d’erreur plutôt que d’autres options.
| Type d’événement | Source de déclenchement | Cas d’utilisation typique | Portée |
|---|---|---|---|
| Événement d’erreur | Échec du système/tâche | Exceptions techniques, échecs de validation | Local ou processus |
| Événement de message | Communication externe | En attente d’une réponse, réception de données | Instance de processus |
| Événement de signal | Diffusion globale | Annulation de plusieurs instances, alertes à l’échelle du système | Global |
| Événement d’escalade | Règles de processus | Non-respect des SLA, exigences d’intervention manuelle | Hiérarchie des processus |
Conception pour la résilience : meilleures pratiques 🛡️
Construire un modèle de processus capable de gérer les erreurs de manière élégante exige une approche stratégique. Il ne suffit pas de placer simplement un événement sur le diagramme ; la logique qui l’entoure doit être solide.
1. Définir des limites claires d’erreur
Ne pas capturer les erreurs qui doivent terminer le processus. Certaines erreurs sont irréversibles. Si un processus ne peut pas continuer sans données spécifiques, capturer l’erreur et tenter de la répéter indéfiniment entraîne un processus zombie. À la place, permettez à l’erreur remonter vers un niveau supérieur ou terminez proprement l’instance.
- Identifier les tâches critiques : Déterminez quelles tâches sont essentielles au bon fonctionnement du processus.
- Terminer en cas d’erreurs fatales : Utilisez les événements d’erreur pour signaler que le processus ne peut pas continuer.
- Réessayer en cas d’erreurs temporaires : Utilisez les événements limites pour les délais d’attente réseau ou les indisponibilités temporaires.
2. Éviter le surtraitement
Toute tâche n’a pas besoin d’un gestionnaire d’erreurs. Ajouter des événements limites à chaque tâche rend le diagramme confus et rend le flux difficile à lire. Attachez uniquement des événements d’erreur aux tâches connues pour échouer ou ayant des conséquences importantes en cas d’échec.
3. Séparer les chemins logiques
Assurez-vous que le chemin pris après une erreur est distinct du chemin normal. Si le chemin d’erreur rejoint finalement le flux principal, utilisez une passerelle exclusive pour les fusionner proprement. Ne mélangez pas la logique de gestion des erreurs avec la logique métier.
Mappage des données et propagation 📡
Lorsqu’une erreur se produit, les données sont souvent perdues sauf si elles sont explicitement mappées. L’un des aspects les plus négligés des événements d’erreur est la gestion des variables.
Persistance des données d’erreur
Lorsqu’une exception est capturée, le système stocke généralement des informations sur l’échec. Cela peut inclure le code d’erreur, l’horodatage et l’état des variables au moment de l’échec.
- Capture des variables :Configurez le moteur pour enregistrer l’état des variables de processus en cas d’erreur.
- Préservation du contexte :Assurez-vous que le gestionnaire d’erreurs ait accès aux données qui ont causé l’échec.
Remontée des erreurs
Si un sous-processus lance une erreur et que ce sous-processus ne dispose pas d’un événement de bord pour la capturer, l’erreur remonte vers le processus parent. C’est une fonctionnalité cruciale pour la conception de processus hiérarchiques.
- Gestion par le parent :Le processus parent peut décider de la manière de réagir à un échec de l’enfant.
- Rétablissement global :Permet une stratégie de récupération centralisée pour une série de tâches liées.
Gestion des erreurs des tâches humaines 👤
Les modèles de processus impliquent souvent des participants humains. Lorsqu’une tâche humaine échoue, l’événement d’erreur se comporte légèrement différemment d’une tâche système.
- Abandon de tâche :Si un utilisateur abandonne une tâche, cela peut déclencher un événement d’erreur.
- Délais d’attente :Si une tâche n’est pas terminée dans un délai défini, une escalade ou une erreur peut être déclenchée.
- Réaffectation :Les événements d’erreur peuvent rediriger la tâche vers un autre utilisateur ou une autre file d’attente si l’assignataire initial échoue.
Lors de la conception pour les tâches humaines, le chemin d’erreur implique souvent un mécanisme de notification. Cela pourrait être une alerte par courriel ou une notification sur tableau de bord destinée à un superviseur.
Tests et validation 🔍
Une fois le modèle construit, il doit être testé pour s’assurer que les chemins d’erreur fonctionnent comme prévu. L’analyse statique ne suffit pas.
Scénarios de simulation
Exécutez des simulations de processus qui déclenchent intentionnellement des erreurs. Vérifiez que :
- L’événement de bord se déclenche correctement.
- Le processus suit le flux d’exception.
- Les données sont conservées ou enregistrées de manière appropriée.
- Le processus n’entre pas dans une boucle infinie de tentatives.
Couverture du code
Assurez-vous que la logique de gestion des erreurs couvre la gamme prévue de scénarios d’échec. Cela inclut :
- Problèmes de connectivité réseau.
- Entrées de données non valides.
- Indisponibilité de l’API externe.
Péchés courants à éviter ⚠️
Même les modélisateurs expérimentés commettent des erreurs lors de la mise en œuvre des événements d’erreur. Être conscient des problèmes courants aide à maintenir un modèle robuste.
- Codes d’erreur manquants :L’omission de définir le code d’erreur dans la configuration du moteur entraîne des échecs silencieux.
- Chemins inaccessibles :Créer des chemins d’erreur qui ne peuvent jamais être atteints en raison de contraintes logiques.
- Ignorer les journaux :Attraper une erreur et ne rien faire avec. L’erreur doit toujours déclencher une entrée dans le journal ou une notification.
- Fusions complexes :Fusionner trop de chemins d’erreur dans une seule passerelle sans distinguer la cause de l’erreur.
Conclusion sur la conception des exceptions 🎓
La conception des événements d’erreur exige un équilibre entre précision technique et pragmatisme opérationnel. En comprenant les types spécifiques d’événements, en les configurant correctement et en suivant les bonnes pratiques établies, vous pouvez construire des processus résilients face aux échecs.
L’objectif n’est pas d’éliminer les erreurs, ce qui est impossible, mais de les gérer efficacement. Un modèle BPMN bien structuré avec une gestion claire des exceptions réduit les temps d’arrêt, améliore la visibilité sur les échecs et garantit que les opérations commerciales peuvent se rétablir rapidement. Concentrez-vous sur les besoins spécifiques de vos tâches, définissez des codes clairs et testez rigoureusement les chemins d’échec. Cette approche conduit à des flux de travail fiables capables de résister à la complexité du monde réel.

