












En gestion des processus métiers, l’efficacité repose souvent sur la capacité à exécuter plusieurs activités simultanément. Lorsqu’un flux de travail nécessite que des tâches distinctes se produisent en même temps, s’appuyer sur une logique séquentielle crée des goulets d’étranglement. C’est là que le passerelle AND devient essentiel dans la spécification BPMN 2.0. Comprendre comment implémenter correctement les chemins parallèles garantit que votre modèle de processus reflète la réalité, évite les blocages et optimise l’utilisation des ressources.
Ce guide explore les mécanismes des passerelles parallèles, la logique du flux de jetons et les règles structurelles nécessaires pour modéliser des flux de travail complexes sans ambiguïté. Nous examinerons les comportements de séparation et de réunion, comparerons les types de passerelles et aborderons les défis courants de synchronisation.
Comprendre la structure de la passerelle AND 🔍
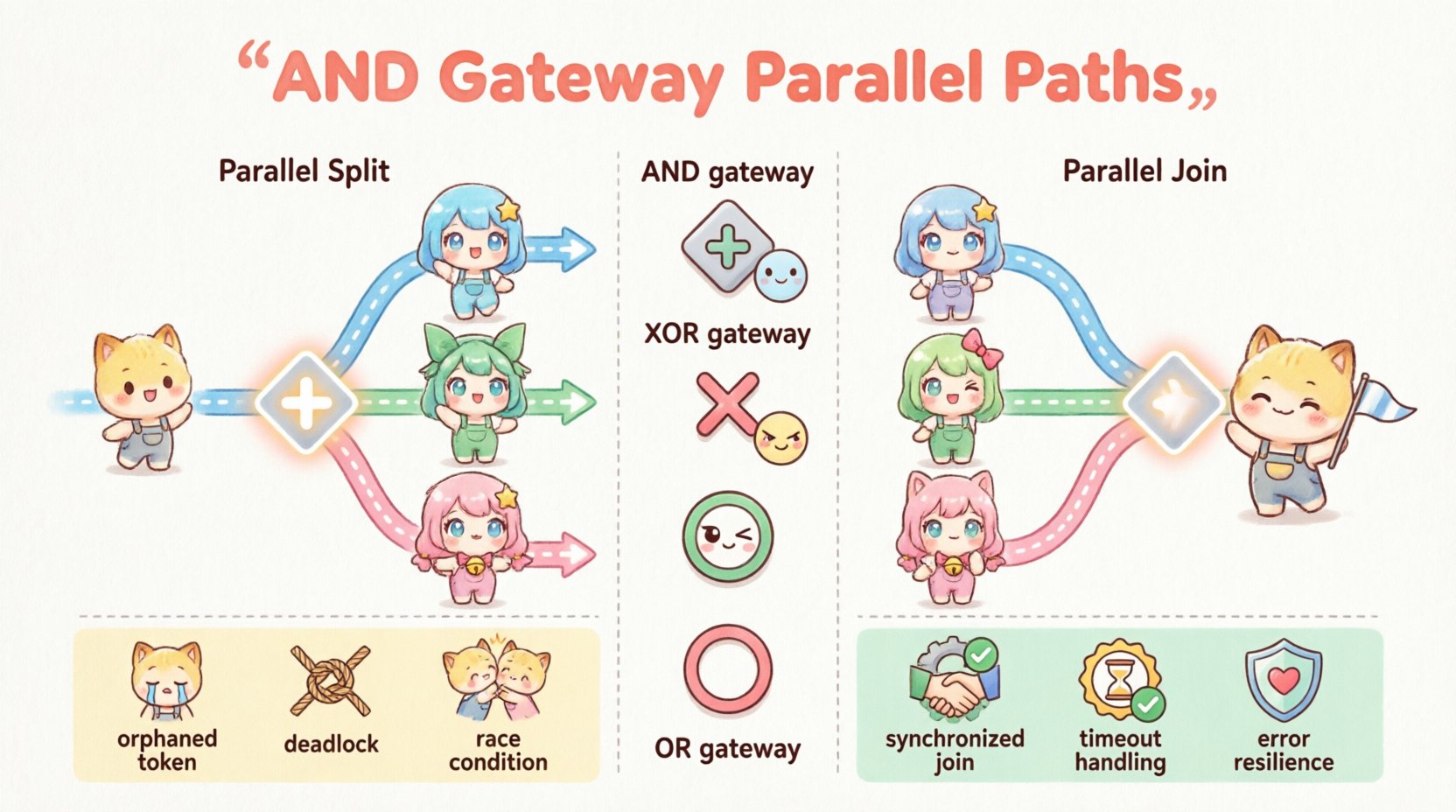
La passerelle AND est un point de décision dans un diagramme de processus qui contrôle le flux des jetons. Contrairement à une passerelle exclusive (XOR), qui choisit un seul chemin, la passerelle AND dirige le flux vers plusieurs chemins simultanément. Elle est visuellement représentée par une forme en losange avec un signe plus (+) à l’intérieur.
Il existe deux comportements principaux associés à cette passerelle :
- Séparation parallèle (Fork) :Le flux entrant déclenche tous les flux sortants simultanément.
- Réunion parallèle (Merge) :Les flux entrants doivent tous arriver avant de poursuivre.
Lors de la modélisation, il est essentiel de distinguer la passerelle utilisée pour séparer le flux de celle utilisée pour le réunir à nouveau. Bien qu’elles partagent le même symbole visuel, leurs rôles fonctionnels diffèrent selon le sens du flux de séquence.
Logique du flux de jetons : le moteur du modèle ⚙️
Pour modéliser efficacement, il faut comprendre comment le moteur de processus gère les jetons. Un jeton représente l’avancement d’une instance de processus unique à travers le diagramme. Le comportement de la passerelle AND détermine comment ces jetons se multiplient et se synchronisent.
1. Comportement de séparation parallèle
Lorsqu’un jeton arrive à une passerelle AND configurée en séparation :
- Le jeton entrant unique est consommé.
- Plusieurs jetons sont créés, un pour chaque flux de séquence sortant.
- Toutes les branches sortantes deviennent actives simultanément.
Cela crée des threads d’exécution parallèles. Si la branche A prend 5 minutes et la branche B 2 minutes, le moteur traite les deux indépendamment. Le jeton n’attend pas que la branche A soit terminée avant de commencer la branche B.
2. Comportement de réunion parallèle
Lorsque les jetons arrivent à une passerelle AND configurée en réunion :
- La passerelle attend qu’un jeton soit présent sur tousles flux de séquence entrants.
- Dès l’arrivée du dernier jeton, tous les jetons entrants sont consommés.
- Un seul jeton est produit sur le flux de séquence sortant.
Cette synchronisation garantit que les activités ultérieures ne commencent qu’une fois que toutes les tâches parallèles sont terminées. Cela est essentiel pour les processus où une approbation finale dépend des données recueillies à partir de plusieurs sources indépendantes.
Passerelle AND vs. autres passerelles 🔄
Le choix du type de passerelle approprié est fondamental pour la précision du processus. Ci-dessous se trouve une comparaison du comportement des passerelles afin de clarifier quand utiliser une passerelle AND plutôt qu’une passerelle XOR ou OR.
| Type de passerelle | Symbole | Logique de séparation | Logique de regroupement | Cas d’utilisation |
|---|---|---|---|---|
| Passerelle AND | Plus (+) | Toutes les voies sont actives | Toutes les voies sont requises | Tâches parallèles, synchronisation |
| Passerelle XOR | Croix (X) | Une seule voie active | Une seule voie arrive | Acheminement conditionnel, choix |
| Passerelle OR | Cercle (O) | Une ou plusieurs voies | Une ou plusieurs voies | Tâches parallèles facultatives |
Guide de modélisation étape par étape 🛠️
Suivez ces étapes pour implémenter des chemins parallèles dans votre diagramme de processus à l’aide d’outils de modélisation standards.
Étape 1 : Définir l’événement de déclenchement
Commencez par un événement de départ. Cela déclenche le processus et génère le jeton initial. Assurez-vous que la logique précédente (le cas échéant) conduit clairement vers la passerelle sans ambiguïté.
Étape 2 : Insérer la passerelle de séparation parallèle
Faites glisser une passerelle AND sur la toile immédiatement après l’événement de départ ou l’activité précédente. Connectez le flux entrant à la passerelle.
Étape 3 : Créer les flux de séquence sortants
Tracez plusieurs flèches sortantes à partir de la passerelle. Chaque flèche représente un chemin parallèle distinct. Étiquetez clairement ces flux pour indiquer la tâche ou le sous-processus spécifique qu’ils initient.
Étape 4 : Modéliser les activités indépendantes
Sur chaque branche, placez les tâches nécessaires. Ce peuvent être des tâches utilisateur, des tâches de service ou des sous-processus. Étant donné qu’elles sont parallèles, l’ordre d’exécution entre les branches est indéfini. Le moteur peut les traiter dans n’importe quel ordre.
Étape 5 : Insérer la passerelle de jointure parallèle
Localisez le point où toutes les branches convergent. Insérez une autre passerelle AND. Assurez-vous que chaque branche parallèle dispose d’un flux de séquence qui conduit vers cette passerelle de jointure. N’oubliez pas de laisser aucun flux entrant déconnecté.
Étape 6 : Continuer le processus
Connectez un seul flux de séquence sortant depuis la passerelle de jointure vers la phase suivante du processus. Ce flux ne s’activera qu’une fois que tous les tokens provenant des branches parallèles seront arrivés.
Gestion de l’exécution asynchrone ⏳
Dans de nombreux scénarios du monde réel, les tâches parallèles ne sont pas véritablement synchrones. Une branche peut impliquer une mise à jour de base de données, tandis qu’une autre attend une réponse externe par courriel. Cela introduit une latence.
Gestion des délais
La logique de jointure de la passerelle AND gère naturellement les délais en attendant. Toutefois, cela peut entraîner des problèmes de performance si un chemin est nettement plus lent que les autres.
- Chemin rapide : Se termine rapidement et attend à la jointure.
- Chemin lent : Prend plus de temps. La passerelle de jointure retient le token jusqu’à ce que ce chemin soit terminé.
Pour atténuer ce problème, envisagez le contexte métier. Est-il acceptable que le processus attende ? Si le chemin lent est non critique, vous pourriez utiliser une passerelle OR à la place afin de permettre au processus de continuer sans attendre la tâche retardée.
Stratégies de temporisation
Certains environnements de modélisation permettent des événements temporisés attachés aux flux de séquence. Si une branche parallèle dépasse une durée spécifique, un événement temporisé peut déclencher un chemin alternatif. Cela empêche la passerelle AND d’attendre indéfiniment.
Péchés courants et gestion des erreurs ⚠️
La modélisation de chemins parallèles introduit de la complexité. Plusieurs erreurs courantes surviennent fréquemment lorsque les concepteurs négligent des exigences spécifiques.
1. Le jeton orphelin
Cela se produit lorsque une séparation parallèle crée un jeton, mais que la passerelle de jointure ne le reçoit jamais. Cela se produit généralement si :
- Une branche est accidentellement omise dans la jointure.
- Une branche conduit à un événement de fin sans revenir au flux principal.
- Un flux conditionnel contourne entièrement la passerelle de jointure.
Résultat : L’instance de processus se bloque ou génère une erreur car le moteur attend un jeton qui n’arrivera jamais.
2. Le blocage
Un blocage se produit lorsque les jetons s’attendent mutuellement dans une dépendance circulaire. Bien que moins fréquent avec des passerelles AND simples, cela peut survenir dans des boucles complexes.
- La branche A attend la branche B.
- La branche B attend la branche A.
Résultat : Le processus s’arrête complètement. Revoyez soigneusement les structures de boucle pour vous assurer que les conditions de sortie sont remplies.
3. Conditions de course
Si deux branches parallèles écrivent sur la même ressource partagée (par exemple, un enregistrement de base de données) sans synchronisation, l’intégrité des données peut être compromise. La passerelle AND synchronise le flux, mais pas nécessairement l’accès à la ressource.
- Utilisez des événements intermédiaires ou des limites de transaction pour gérer les données partagées.
- Assurez-vous que les tâches de service sont idempotentes si des réessais ont lieu.
Meilleures pratiques pour une modélisation robuste ✅
Pour maintenir la clarté et la fiabilité de vos diagrammes de processus, suivez ces directives.
- Correspondance entre le split et le join : Chaque split doit avoir un join correspondant. Si vous divisez, vous devez fusionner.
- Utilisez des étiquettes claires : Étiquetez les flux de séquence pour indiquer pourquoi ils sont parallèles (par exemple, « Envoyer un e-mail », « Mettre à jour le CRM »).
- Vérifiez l’équilibre des jetons : Assurez-vous que le nombre de flux entrants au join correspond au nombre de flux sortants au split pour les flux simples.
- Évitez les passerelles imbriquées : Gardez la logique des passerelles simple. Un imbriquage profond rend le débogage difficile.
- Validez la logique : Exécutez une simulation si votre outil le permet. Vérifiez que tous les chemins atteignent l’événement de fin.
Modèles avancés : Passerelles AND imbriquées 🔗
Les processus complexes nécessitent souvent plusieurs niveaux de parallélisme. Vous pouvez imbriquer des passerelles AND dans des sous-processus ou des flux principaux.
Scénario : Approbation multi-niveaux
Considérez un scénario où un document nécessite une approbation de deux départements simultanément, et chaque département dispose de deux gestionnaires.
- Niveau 1 : Split Divisez en « Département A » et « Département B ».
- Niveau 2 : Split (à l’intérieur du Département A) : Divisé en « Gérant 1 » et « Gérant 2 ».
- Fusion de niveau 2 (à l’intérieur du Département A) : Attendre que les deux gérants soient prêts.
- Fusion de niveau 1 : Attendre que les deux départements aient terminé.
Cette structure garantit que le processus ne progresse que lorsque toutes les approbations spécifiques ont été collectées. Elle maintient la logique de la passerelle ET à chaque niveau de la hiérarchie.
Gestion des exceptions dans les chemins parallèles ❌
Que se passe-t-il si une branche échoue ? Le comportement dépend de la manière dont le moteur de processus gère les exceptions.
- Comportement standard : Si une branche échoue, le jeton de cette branche est consommé. La passerelle de fusion attend l’autre branche. L’instance de processus peut se terminer dans un état d’erreur ou continuer, selon la configuration.
- Sous-processus d’erreur : Utilisez des événements de limite d’erreur sur les tâches au sein des branches parallèles. Cela permet à la branche de gérer l’erreur localement sans interrompre l’ensemble du flux parallèle.
- Compensation : Si une tâche parallèle est terminée mais que les données sont invalides, une logique de compensation peut être nécessaire pour annuler le travail effectué par l’autre branche parallèle.
Les concepteurs doivent décider si l’échec d’une tâche parallèle doit interrompre l’ensemble du processus ou permettre à l’autre branche de se terminer. Cette décision détermine souvent l’emplacement des gestionnaires d’erreurs.
Implications sur les performances 🚀
Bien que les chemins parallèles améliorent le débit, ils augmentent la consommation de ressources. Le moteur de processus doit gérer plusieurs threads ou états pour une seule instance.
- Verrouillage de la base de données : Un plus grand nombre de jetons concurrents peut augmenter la contention sur la base de données.
- Utilisation de la mémoire : Chaque jeton actif nécessite de la mémoire pour suivre son état.
- Évolutivité : Les processus à fort volume avec de nombreuses séparations parallèles nécessitent une infrastructure solide.
Lors de la modélisation, prenez en compte le volume des instances. Un processus qui s’exécute 10 fois par jour avec des chemins parallèles est différent d’un processus qui s’exécute 10 000 fois par jour. Pour un volume élevé, assurez-vous que les tâches parallèles sont légères.
Résumé des considérations relatives à l’implémentation 📝
Modéliser des chemins parallèles à l’aide de passerelles ET est une compétence fondamentale pour une représentation précise des processus métiers. Cela permet aux organisations de réduire les délais de cycle en exécutant des tâches en parallèle tout en maintenant la cohérence des données grâce à la synchronisation.
Les points clés pour une mise en œuvre efficace incluent :
- Utilisez la passerelle ET pour une exécution parallèle obligatoire.
- Assurez la synchronisation au point de fusion pour éviter les jetons orphelins.
- Prenez en compte les différences de latence entre les branches parallèles.
- Mettez en œuvre des stratégies de gestion des erreurs spécifiques à la logique parallèle.
- Validez le modèle pour vous assurer que toutes les voies convergent correctement.
En suivant ces directives structurelles, vous créez un modèle de processus robuste qui correspond aux réalités opérationnelles. La passerelle AND reste l’un des outils les plus puissants pour optimiser l’efficacité du flux de travail au sein de la norme BPMN.