












La livraison moderne de logiciels repose souvent sur des systèmes complexes conçus pour déplacer le code des environnements de développement vers la production. Lorsque ces systèmes échouent, l’impact peut être important. Un diagramme de déploiement sert de plan directeur pour ces infrastructures, en cartographiant les nœuds, les artefacts et leurs interactions. Toutefois, un diagramme n’est utile que dans la mesure où il correspond à l’environnement réel en cours d’exécution. Lorsque des écarts apparaissent, un dépannage systématique devient essentiel. Ce guide explore comment diagnostiquer et résoudre les problèmes au sein d’architectures de déploiement complexes sans dépendre d’outils ou de produits spécifiques aux fournisseurs.
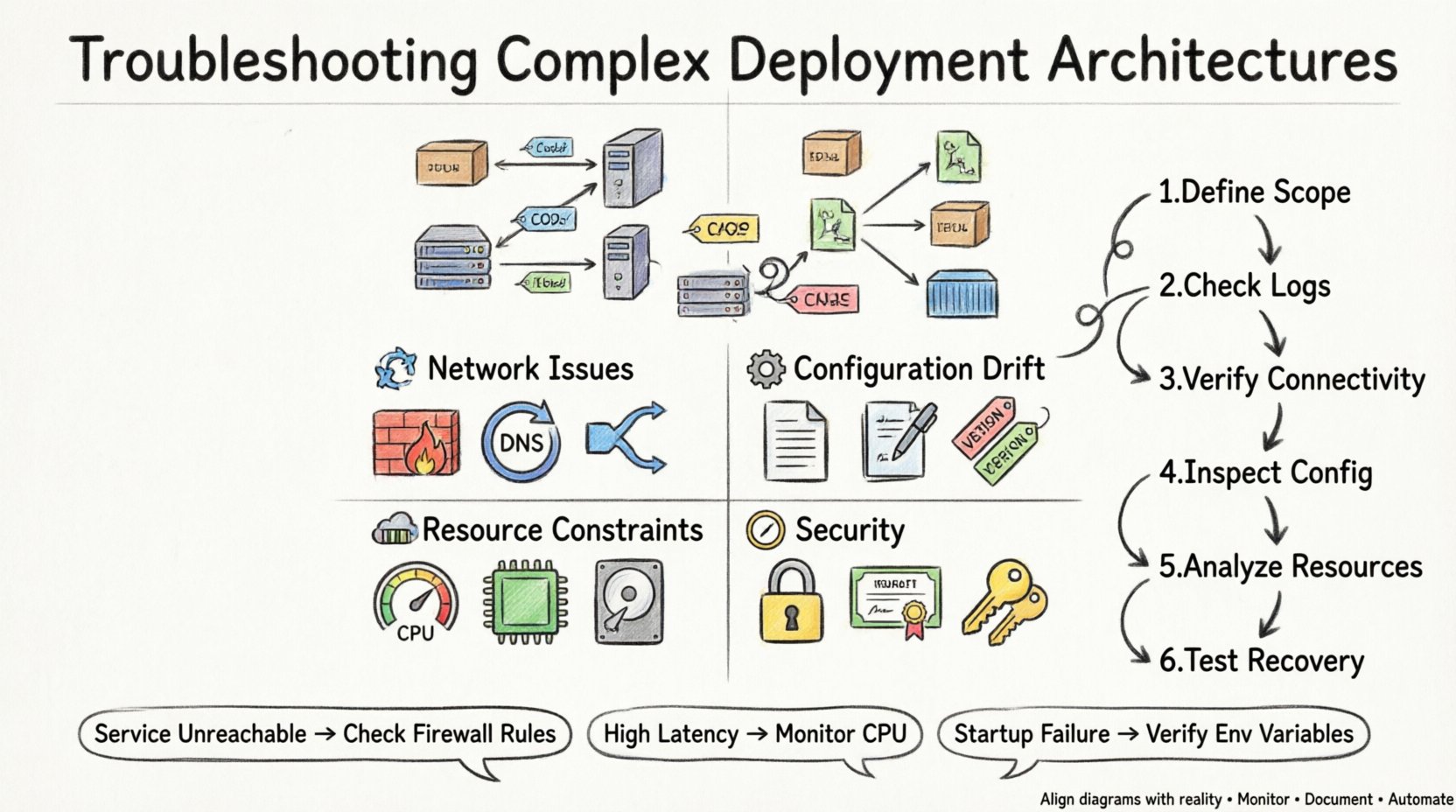
Comprendre le diagramme de déploiement 📐
Avant d’essayer de résoudre un problème, il faut comprendre ce que représente l’architecture. Un diagramme de déploiement illustre la structure physique ou logique du système. Il précise où se trouvent les composants logiciels et comment ils communiquent. Dans les configurations complexes, cela implique souvent plusieurs niveaux d’abstraction.
-
Nœuds : Ils représentent les ressources informatiques où les artefacts sont déployés. Ils peuvent être des machines physiques, des instances virtuelles ou des conteneurs.
-
Artefacts : Ce sont les paquets logiciels installés sur les nœuds. Ils comprennent les fichiers binaires, les fichiers de configuration et les bibliothèques.
-
Connexions : Elles définissent les chemins de communication entre les nœuds. Elles précisent les protocoles, les ports et les types de données.
-
Dépendances : Elles montrent les prérequis nécessaires pour qu’un nœud fonctionne correctement.
Lorsqu’un problème survient, la première étape consiste à comparer le diagramme avec l’état actuel de l’infrastructure. Les écarts ici sont souvent la cause fondamentale des échecs.
Modes de défaillance courants ⚠️
Les architectures complexes introduisent plusieurs points de défaillance. Comprendre les modes de défaillance courants permet de réduire rapidement l’investigation. Les problèmes relèvent généralement de catégories liées à la connectivité, à la configuration, aux ressources ou à la sécurité.
1. Problèmes de connectivité et de réseau 🌐
Les problèmes réseau sont parmi les causes les plus fréquentes d’échec de déploiement. Même si le diagramme indique une connexion valide, le réseau pourrait bloquer le trafic.
-
Règles de pare-feu : Les ports nécessaires à la communication pourraient être fermés par des pare-feu intermédiaires ou des groupes de sécurité.
-
Résolution DNS : Les services dépendent souvent des noms de domaine. Si le DNS n’est pas correctement configuré, les nœuds ne peuvent pas se localiser mutuellement.
-
Configuration des sous-réseaux : Les nœuds situés dans des segments réseau différents pourraient ne pas disposer des tables de routage nécessaires pour communiquer.
-
Équilibreurs de charge : La logique de distribution du trafic pourrait être mal configurée, envoyant des requêtes vers des nœuds défaillants.
2. Décalage de configuration ⚙️
Le décalage de configuration survient lorsque l’état réel d’un nœud s’écarte de l’état prévu défini dans le plan de déploiement. Cela se produit souvent lorsque des modifications manuelles sont apportées directement à un environnement de production.
-
Variables d’environnement :Les variables manquantes ou incorrectes peuvent empêcher les services de démarrer ou provoquer un comportement inattendu.
-
Permissions des fichiers :Des permissions incorrectes sur les fichiers de configuration peuvent empêcher l’application de lire les données nécessaires.
-
Incompatibilités de version :Les bibliothèques ou dépendances installées sur le nœud peuvent ne pas correspondre à la version spécifiée dans l’artefact.
3. Contraintes de ressources 💾
Même une architecture parfaitement configurée échouera si le matériel sous-jacent ne peut pas supporter la charge. L’épuisement des ressources est un tueur silencieux de la fiabilité du déploiement.
-
Saturation du CPU :Une utilisation élevée peut entraîner une latence ou des délais d’expiration des services.
-
Fuites de mémoire :Les applications qui ne libèrent pas correctement la mémoire peuvent faire épuiser la RAM de l’hôte.
-
Espace disque :Les journaux et les fichiers temporaires peuvent remplir le stockage, empêchant l’écriture de nouvelles données.
-
Bandwidth réseau :Un débit insuffisant peut entraîner des échecs de transfert de données entre les nœuds.
4. Sécurité et autorisations 🔒
Les protocoles de sécurité sont essentiels pour protéger les données, mais ils peuvent également bloquer le trafic légitime s’ils sont configurés de manière trop restrictive.
-
Gestion des identités et des accès :Les comptes de service pourraient manquer des autorisations nécessaires pour accéder à d’autres ressources.
-
Validation des certificats :Les certificats SSL/TLS expirés ou auto-signés peuvent interrompre les connexions chiffrées.
-
Jetons d’authentification :Les jetons expirés ou non valides peuvent empêcher les services de s’authentifier mutuellement.
Méthodologie de diagnostic 🔍
Lors du dépannage, une approche structurée évite le gaspillage de temps. Suivez ces étapes pour isoler le problème de manière efficace.
-
Définir le périmètre :Déterminez exactement quelle partie de l’architecture est en panne. S’agit-il de l’ensemble du système, d’un nœud spécifique ou d’une connexion spécifique ?
-
Vérifiez les journaux :Examinez les journaux des applications et du système à la recherche de messages d’erreur. Recherchez les horodatages correspondant à l’événement de panne.
-
Vérifiez la connectivité :Utilisez des outils réseau pour tester la connectivité entre les nœuds. Vérifiez si les ports sont ouverts et répondent.
-
Examinez la configuration :Comparez la configuration actuelle avec la configuration de base définie dans le diagramme de déploiement.
-
Analysez l’utilisation des ressources :Surveillez l’utilisation du CPU, de la mémoire et du disque pendant la fenêtre d’erreur.
-
Testez la récupération :Tentez de redémarrer les services ou d’annuler les modifications pour voir si le problème est résolu.
Tableau : Symptômes courants vs. Actions de diagnostic 📋
Ce tableau résume les symptômes fréquents et les actions correspondantes nécessaires pour les diagnostiquer.
|
Symptôme |
Cause potentielle |
Action de diagnostic |
|---|---|---|
|
Service injoignable |
Pare-feu réseau |
Vérifiez les groupes de sécurité et les règles du pare-feu |
|
Latence élevée |
Saturation du CPU |
Surveillez les métriques d’utilisation du CPU |
|
Échec du démarrage |
Configuration manquante |
Vérifiez les variables d’environnement et les fichiers |
|
Réinitialisation de la connexion |
Épuisement des ressources |
Vérifiez l’utilisation de la mémoire et de l’espace disque |
|
Erreur d’authentification |
Expiration du certificat |
Vérifiez la validité du certificat SSL/TLS |
|
Pipeline bloqué |
Délai d’attente de dépendance |
Revoyez la connectivité réseau vers les dépôts externes |
Approfondissement : Diagnostic réseau 🌐
Les problèmes réseau sont particulièrement délicats car ils apparaissent souvent de manière intermittente. Lorsqu’un diagramme de déploiement montre une connexion entre le nœud A et le nœud B, mais que le trafic ne circule pas, vous devez enquêter sur le chemin.
1. Suivi du parcours
Utilisez des outils de traçage réseau pour identifier où les paquets sont perdus. Cela permet de déterminer si le problème provient du réseau local, sur Internet ou au niveau du nœud de destination.
-
Capture de paquets :Analysez le trafic à la source et à la destination pour vérifier si les paquets sont envoyés et reçus.
-
Tables de routage :Vérifiez que les nœuds savent comment acheminer le trafic entre eux.
-
Paramètres MTU :Les incompatibilités de la taille maximale de transmission (MTU) peuvent entraîner une fragmentation et une perte de paquets.
2. DNS et découverte de services
De nombreuses architectures modernes reposent sur des mécanismes de découverte de services plutôt que sur des adresses IP codées en dur. Si le service de découverte est hors ligne, les nœuds ne peuvent pas se trouver mutuellement.
-
Validation des enregistrements :Assurez-vous que les enregistrements DNS pointent vers les bonnes adresses IP.
-
Problèmes de cache :Le cache DNS peut entraîner des données obsolètes. Videz les caches DNS si nécessaire.
-
Interne vs externe :Différenciez les noms de service internes des noms de domaine externes.
Approfondissement : Gestion de la configuration ⚙️
La gestion de la configuration assure que tous les nœuds de l’architecture sont dans un état connu. Lorsque ce processus échoue, le déploiement devient instable.
1. Infrastructure comme code
Définir l’infrastructure à l’aide de code permet un contrôle de version et une reproductibilité. Toutefois, des erreurs de syntaxe ou des défauts logiques dans le code peuvent entraîner des échecs de déploiement.
-
Validation :Exécutez des vérifications de syntaxe avant d’appliquer les modifications.
-
Fichiers d’état :Assurez-vous que le fichier d’état reflète fidèlement l’infrastructure actuelle.
-
Détection des écarts :Mettez en œuvre des outils pour détecter les modifications manuelles.
2. Gestion des secrets
Les données sensibles telles que les mots de passe et les clés API doivent être stockées de manière sécurisée. Une gestion incorrecte peut entraîner des violations de sécurité ou des échecs de déploiement.
-
Chiffrement :Assurez-vous que les secrets sont chiffrés au repos et en transit.
-
Rotation : Rotationnez régulièrement les identifiants pour minimiser les risques.
-
Contrôle d’accès : Limitez l’accès aux secrets aux seuls services nécessaires.
Approfondissement : Gestion des ressources 💾
Les contraintes de ressources se manifestent souvent pendant les périodes de forte utilisation. Prévoir la capacité est essentiel pour éviter les pannes.
1. Stratégies d’extension
Les architectures doivent être conçues pour s’adapter horizontalement ou verticalement selon la demande. Si l’extension échoue, le système peut devenir inactif.
-
Extension horizontale : Ajoutez plus d’instances pour gérer une charge accrue.
-
Extension verticale : Augmentez les ressources des instances existantes.
-
Auto-échelonnement : Configurez des règles pour ajuster automatiquement les ressources en fonction des métriques.
2. Surveillance et alertes
La surveillance proactive aide à identifier les problèmes de ressources avant qu’ils ne provoquent des défaillances.
-
Seuils : Définissez des alertes pour l’utilisation du CPU, de la mémoire et du disque.
-
Journaux : Agrégez les journaux de tous les nœuds pour une analyse centralisée.
-
Traçage : Utilisez le traçage distribué pour suivre les requêtes à travers les services.
Approfondissement : Sécurité et autorisations 🔒
La sécurité n’est pas une étape ultérieure ; elle doit être intégrée au processus de déploiement.
1. Principe du moindre privilège
Les services ne doivent avoir que les autorisations nécessaires à leur fonctionnement. Les services sur-autorisés augmentent la surface d’attaque.
-
Rôles : Définissez des rôles spécifiques pour différents services.
-
Politiques : Appliquez des politiques qui limitent l’accès à des ressources spécifiques.
-
Audit : Auditez régulièrement les autorisations pour assurer la conformité.
2. Sécurité du réseau
La segmentation du réseau limite le rayon d’action d’une éventuelle violation.
-
VLAN : Séparez le trafic par fonction ou environnement.
-
Pare-feu : Bloquez le trafic non autorisé aux frontières du réseau.
-
Chiffrement : Chiffrez toutes les données en transit entre les nœuds.
Intégrité du pipeline et de l’automatisation 🔄
Le pipeline qui transporte le code du développement à la production est un composant essentiel de l’architecture de déploiement. Si le pipeline échoue, aucun code n’atteint l’environnement.
1. Étapes du pipeline
Divisez le pipeline en étapes distinctes pour isoler les défaillances.
-
Construction : Compilez le code et créez les artefacts.
-
Test : Exécutez des tests automatisés pour vérifier la fonctionnalité.
-
Déploiement : Envoyez les artefacts vers l’environnement cible.
-
Vérification : Effectuez des vérifications post-déploiement.
2. Procédures de retour arrière
Lorsqu’un déploiement échoue, un retour arrière rapide minimise l’indisponibilité.
-
Gestion des versions : Gardez les versions précédentes des artefacts disponibles.
-
Automatisation : Automatisez le processus de retour arrière pour réduire les erreurs humaines.
-
Tests : Testez régulièrement les procédures de retour arrière pour vous assurer qu’elles fonctionnent.
Observabilité et journaux 🔍
L’observabilité fournit une vision de l’état interne du système. Sans elle, le dépannage est une simple supposition.
1. Journalisation centralisée
Collectez les journaux de tous les nœuds dans un emplacement central pour une analyse plus facile.
-
Agrégation :Utilisez un agrégateur de journaux pour collecter les données.
-
Indexation :Indexez les journaux pour une recherche rapide.
-
Conservation :Définissez des politiques de conservation pour gérer le stockage.
2. Métriques et tableaux de bord
Visualisez les indicateurs clés de performance pour détecter rapidement les anomalies.
-
Métriques clés :Suivez les taux de requêtes, les taux d’erreurs et la latence.
-
Alertes :Configurez des alertes pour les seuils de métriques.
-
Visualisation :Utilisez des tableaux de bord pour afficher les données au fil du temps.
Réponse aux incidents et récupération 🚨
Même avec une planification optimale, des incidents se produiront. Disposer d’un plan de réponse garantit une récupération rapide.
1. Classification des incidents
Catégorisez les incidents en fonction de leur gravité et de leur impact.
-
Critique :Le système est hors ligne ou les données sont compromises.
-
Élevé :Dégradation importante du service.
-
Moyen :Problèmes mineurs affectant un sous-ensemble d’utilisateurs.
-
Faible :Problèmes esthétiques ou non urgents.
2. Communication
Tenir les parties prenantes informées tout au long de l’incident.
-
Mises à jour de statut :Fournir des mises à jour régulières sur les progrès.
-
Analyse post-mortem :Analyser l’incident après sa résolution.
-
Points d’action :Attribuer des tâches pour éviter la récurrence.
Documentation et contrôle de version 📝
La documentation garantit que les connaissances sont conservées et partagées. Le contrôle de version garantit que les modifications sont suivies.
1. Documentation de l’architecture
Tenir le diagramme de déploiement à jour.
-
Modifications :Documenter chaque modification apportée à l’architecture.
-
Dépendances :Lister toutes les dépendances externes et internes.
-
Procédures :Documenter les procédures opérationnelles standard.
2. Gestion des changements
Contrôler la manière dont les modifications sont apportées à l’environnement.
-
Revue :Exiger des revues pour les modifications importantes.
-
Approbation :Obtenir l’approbation avant d’appliquer les modifications.
-
Suivi :Suivre toutes les modifications dans un système.
Considérations finales pour la santé du déploiement 🏥
Maintenir une architecture de déploiement saine exige un effort continu. Des revues et des mises à jour régulières sont nécessaires pour suivre les exigences en évolution. Concentrez-vous sur les domaines suivants pour assurer une stabilité à long terme.
-
Audits réguliers :Effectuer des audits périodiques de l’architecture.
-
Planification de la capacité : Prévoir la croissance future.
-
Formation : Former l’équipe aux méthodologies de dépannage.
-
Automatisation : Automatiser les tâches répétitives afin de réduire les erreurs humaines.
-
Tests : Tester l’architecture régulièrement dans un environnement de préproduction.
En suivant une approche structurée du dépannage, les équipes peuvent résoudre les problèmes plus rapidement et réduire les temps d’indisponibilité. L’objectif n’est pas seulement de corriger les problèmes, mais de construire un système résilient et facile à maintenir. Les diagrammes de déploiement sont des documents vivants qui doivent évoluer avec l’infrastructure. Lorsqu’ils évoluent, l’architecture reste alignée sur les besoins métiers.
Souvenez-vous qu’une défaillance est toujours une opportunité d’apprendre. Documenter la cause racine et la solution aide à éviter des problèmes similaires à l’avenir. Cette base de connaissances devient un atout précieux pour l’ensemble de l’organisation.

