












Pengiriman perangkat lunak modern sering mengandalkan sistem rumit yang dirancang untuk memindahkan kode dari lingkungan pengembangan ke produksi. Ketika sistem-sistem ini gagal, dampaknya bisa sangat besar. Diagram deploiemen berfungsi sebagai gambaran rancangan untuk infrastruktur ini, memetakan node, artefak, dan interaksi di antaranya. Namun, sebuah diagram hanya seberguna sejauh kesesuaiannya dengan lingkungan yang sedang berjalan. Ketika terjadi ketidaksesuaian, pendekatan penyelesaian masalah yang sistematis menjadi sangat penting. Panduan ini mengeksplorasi cara mendiagnosis dan menyelesaikan masalah dalam arsitektur deploiemen yang kompleks tanpa bergantung pada alat atau produk vendor tertentu.
Memahami Diagram Deploiemen 📐
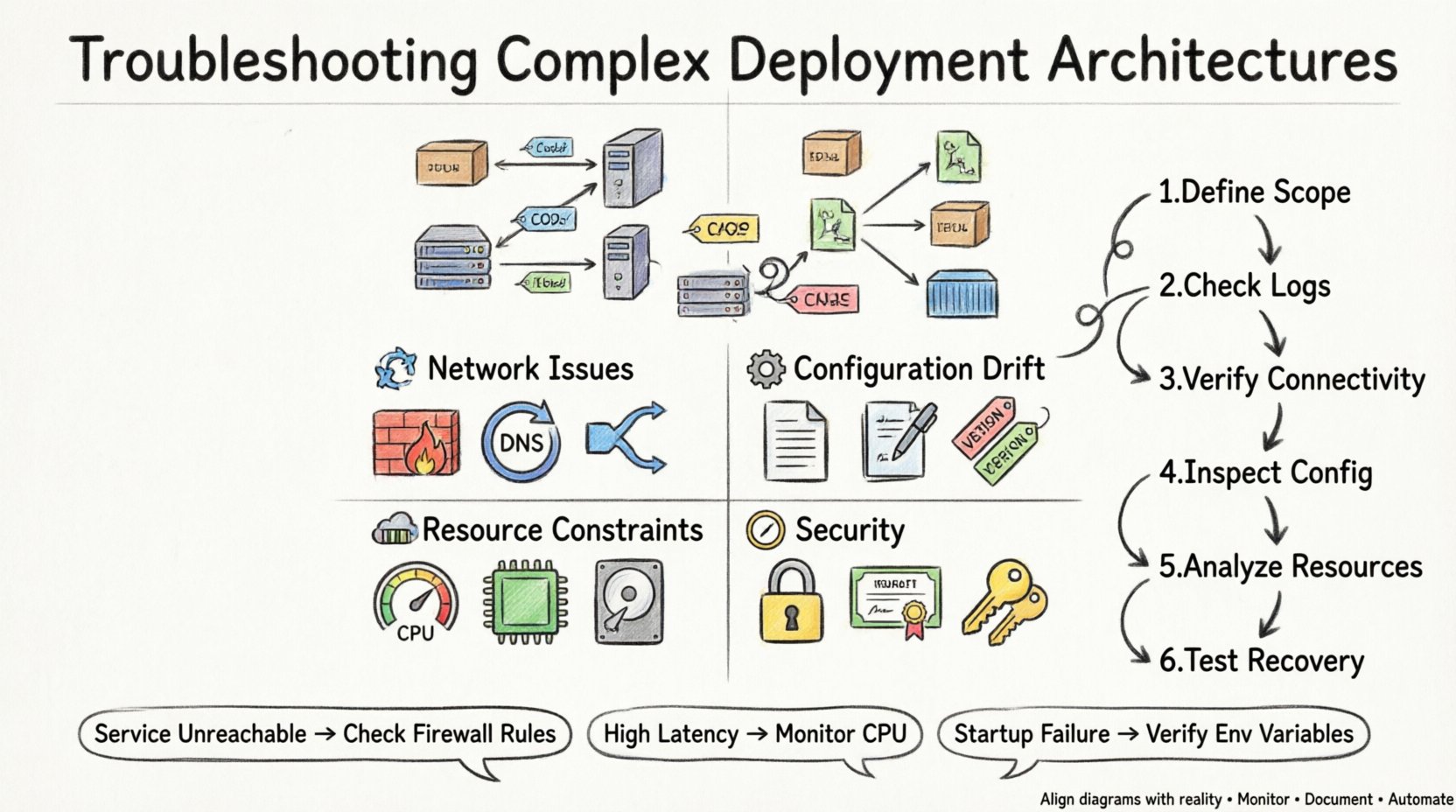
Sebelum mencoba memperbaiki suatu masalah, seseorang harus memahami apa yang diwakili oleh arsitektur tersebut. Diagram deploiemen menggambarkan struktur fisik atau logis dari sistem. Diagram ini menjelaskan di mana komponen perangkat lunak berada dan bagaimana mereka berkomunikasi. Dalam pengaturan yang kompleks, ini sering melibatkan beberapa lapisan abstraksi.
-
Node: Ini mewakili sumber daya komputasi tempat artefak dideploy. Mereka bisa berupa mesin fisik, instans virtual, atau container.
-
Artefak: Ini adalah paket perangkat lunak yang sedang diinstal pada node. Mereka mencakup biner, file konfigurasi, dan perpustakaan.
-
Koneksi: Ini menentukan jalur komunikasi antar node. Mereka menentukan protokol, port, dan tipe data.
-
Ketergantungan: Ini menunjukkan prasyarat yang diperlukan agar node dapat berfungsi dengan benar.
Ketika terjadi masalah, langkah pertama adalah membandingkan diagram dengan keadaan saat ini dari infrastruktur. Ketidaksesuaian di sini sering menjadi akar penyebab kegagalan.
Mode Kegagalan Umum ⚠️
Arsitektur yang kompleks memperkenalkan banyak titik kegagalan. Memahami mode kegagalan umum membantu menyempitkan investigasi dengan cepat. Masalah umumnya tergolong dalam kategori yang berkaitan dengan konektivitas, konfigurasi, sumber daya, atau keamanan.
1. Masalah Konektivitas dan Jaringan 🌐
Masalah jaringan merupakan salah satu penyebab paling umum kegagalan deploiemen. Bahkan jika diagram menunjukkan koneksi yang valid, jaringan bisa memblokir lalu lintas.
-
Aturan Firewall:Port yang diperlukan untuk komunikasi bisa ditutup oleh firewall antaranya atau grup keamanan.
-
Resolusi DNS:Layanan sering mengandalkan nama domain. Jika DNS tidak dikonfigurasi dengan benar, node tidak dapat saling menemukan.
-
Konfigurasi Subnet:Node di segmen jaringan yang berbeda mungkin tidak memiliki tabel rute yang diperlukan untuk berkomunikasi.
-
Load Balancer:Logika distribusi lalu lintas mungkin salah dikonfigurasi, mengirim permintaan ke node yang tidak sehat.
2. Perpindahan Konfigurasi ⚙️
Perpindahan konfigurasi terjadi ketika keadaan aktual dari sebuah node menyimpang dari keadaan yang dimaksudkan dalam rencana deploiemen. Hal ini sering terjadi ketika perubahan manual dilakukan langsung pada lingkungan produksi.
-
Variabel Lingkungan:Variabel yang hilang atau salah dapat menyebabkan layanan gagal memulai atau berperilaku tidak sesuai harapan.
-
Izin File:Izin yang salah pada file konfigurasi dapat mencegah aplikasi membaca data yang diperlukan.
-
Ketidaksesuaian Versi:Perpustakaan atau ketergantungan yang diinstal pada node mungkin tidak sesuai dengan versi yang ditentukan dalam artefak.
3. Kendala Sumber Daya 💾
Bahkan arsitektur yang dikonfigurasi sempurna akan gagal jika perangkat keras dasar tidak dapat mendukung beban. Kehabisan sumber daya adalah pembunuh diam-diam keandalan penyebaran.
-
Kejenuhan CPU:Penggunaan tinggi dapat menyebabkan latensi atau waktu habis untuk layanan.
-
Kebocoran Memori:Aplikasi yang tidak melepaskan memori dengan benar dapat menyebabkan host kehabisan RAM.
-
Ruangan Disk:Log dan file sementara dapat mengisi penyimpanan, mencegah data baru ditulis.
-
Bandwidth Jaringan:Throughput yang tidak mencukupi dapat menyebabkan kegagalan transfer data antar node.
4. Keamanan dan Izin 🔒
Protokol keamanan sangat penting untuk melindungi data, tetapi juga dapat memblokir lalu lintas yang sah jika dikonfigurasi terlalu ketat.
-
Manajemen Akses Identitas:Akun layanan mungkin tidak memiliki izin yang diperlukan untuk mengakses sumber daya lain.
-
Validasi Sertifikat:Sertifikat SSL/TLS yang kedaluwarsa atau dibuat sendiri dapat mengganggu koneksi terenkripsi.
-
Token Autentikasi:Token yang kedaluwarsa atau tidak valid dapat mencegah layanan untuk melakukan otentikasi satu sama lain.
Metodologi Diagnostik 🔍
Saat melakukan penyelesaian masalah, pendekatan terstruktur mencegah pemborosan waktu. Ikuti langkah-langkah ini untuk mengisolasi masalah secara efisien.
-
Tentukan Lingkup:Tentukan secara tepat bagian mana dari arsitektur yang gagal. Apakah seluruh sistem, node tertentu, atau koneksi tertentu?
-
Periksa Log:Tinjau log aplikasi dan sistem untuk pesan kesalahan. Cari timestamp yang sesuai dengan kejadian kegagalan.
-
Verifikasi Konektivitas:Gunakan alat jaringan untuk menguji ketersediaan antar node. Periksa apakah port terbuka dan merespons.
-
Periksa Konfigurasi: Bandingkan konfigurasi saat ini dengan dasar yang ditentukan dalam diagram penempatan.
-
Analisis Penggunaan Sumber Daya: Pantau penggunaan CPU, memori, dan disk selama jendela kegagalan.
-
Uji Pemulihan: Coba untuk memulai ulang layanan atau mengembalikan perubahan untuk melihat apakah masalah teratasi.
Tabel: Gejala Umum vs. Tindakan Diagnostik 📋
Tabel ini merangkum gejala yang sering terjadi dan tindakan yang diperlukan untuk mendiagnosis mereka.
|
Gejala |
Penyebab Potensial |
Tindakan Diagnostik |
|---|---|---|
|
Layanan Tidak Dapat Diakses |
Firewall Jaringan |
Periksa Grup Keamanan dan Aturan Firewall |
|
Latensi Tinggi |
Kepuasan CPU |
Pantau Metrik Utilisasi CPU |
|
Kegagalan Startup |
Konfigurasi yang Hilang |
Verifikasi Variabel Lingkungan dan Berkas |
|
Koneksi Direset |
Kehabisan Sumber Daya |
Periksa Penggunaan Memori dan Ruang Disk |
|
Kesalahan Otentikasi |
Kedaluwarsa Sertifikat |
Periksa Kelengkapan Validitas Sertifikat SSL/TLS |
|
Pipeline Terjebak |
Waktu Habis untuk Ketergantungan |
Ulas Konektivitas Jaringan ke Repositori Eksternal |
Mendalam: Diagnostik Jaringan 🌐
Masalah jaringan sangat sulit karena sering muncul secara tidak menentu. Ketika diagram penempatan menunjukkan koneksi antara Node A dan Node B, tetapi lalu lintas tidak mengalir, Anda harus menyelidiki jalurnya.
1. Melacak Rute
Gunakan alat pelacakan jaringan untuk mengidentifikasi di mana paket hilang. Ini membantu menentukan apakah masalah terletak dalam jaringan lokal, di seluruh internet, atau di node tujuan.
-
Penangkapan Paket:Analisis lalu lintas di sumber dan tujuan untuk melihat apakah paket dikirim dan diterima.
-
Tabel Routing:Verifikasi bahwa node-node tahu cara meneruskan lalu lintas satu sama lain.
-
Pengaturan MTU:Ketidaksesuaian Maximum Transmission Unit dapat menyebabkan fragmentasi paket dan kehilangan paket.
2. DNS dan Penemuan Layanan
Banyak arsitektur modern mengandalkan mekanisme penemuan layanan daripada alamat IP yang dikodekan secara tetap. Jika layanan penemuan tidak berfungsi, node tidak dapat saling menemukan.
-
Validasi Rekaman:Pastikan rekaman DNS mengarah ke alamat IP yang benar.
-
Masalah Cache:Penggunaan cache DNS dapat menyebabkan data yang usang. Kosongkan cache DNS jika diperlukan.
-
Internal vs Eksternal:Bedakan antara nama layanan internal dan nama domain eksternal.
Penyelidikan Mendalam: Manajemen Konfigurasi ⚙️
Manajemen konfigurasi memastikan semua node dalam arsitektur berada dalam keadaan yang diketahui. Ketika proses ini gagal, pengiriman menjadi tidak stabil.
1. Infrastruktur sebagai Kode
Mendefinisikan infrastruktur menggunakan kode memungkinkan kontrol versi dan kemampuan direplikasi. Namun, kesalahan sintaks atau kelemahan logis dalam kode dapat menyebabkan kegagalan pengiriman.
-
Validasi: Jalankan pemeriksaan sintaks sebelum menerapkan perubahan.
-
File Status:Pastikan file status secara akurat mencerminkan infrastruktur saat ini.
-
Deteksi Perubahan:Terapkan alat untuk mendeteksi ketika terjadi perubahan manual.
2. Manajemen Rahasia
Data sensitif seperti kata sandi dan kunci API harus disimpan secara aman. Penanganan yang tidak tepat dapat menyebabkan pelanggaran keamanan atau kegagalan pengiriman.
-
Enkripsi:Pastikan rahasia dienkripsi saat disimpan dan saat dalam perjalanan.
-
Rotasi:Secara rutin mengganti kredensial untuk meminimalkan risiko.
-
Kontrol Akses:Batasi akses ke rahasia hanya untuk layanan yang diperlukan.
Membahas Mendalam: Manajemen Sumber Daya 💾
Keterbatasan sumber daya sering muncul saat waktu penggunaan puncak. Perencanaan kapasitas sangat penting untuk mencegah gangguan.
1. Strategi Penskalaan
Arsitektur harus dirancang untuk dapat diskalakan secara horizontal atau vertikal berdasarkan permintaan. Jika penskalaan gagal, sistem dapat menjadi tidak responsif.
-
Penskalaan Horizontal: Tambahkan lebih banyak instans untuk menangani beban yang meningkat.
-
Penskalaan Vertikal: Tingkatkan sumber daya dari instans yang sudah ada.
-
Penskalaan Otomatis: Konfigurasikan aturan untuk secara otomatis menyesuaikan sumber daya berdasarkan metrik.
2. Pemantauan dan Peringatan
Pemantauan proaktif membantu mengidentifikasi masalah sumber daya sebelum menyebabkan kegagalan.
-
Ambang Batas: Atur peringatan untuk penggunaan CPU, memori, dan disk.
-
Log: Kumpulkan log dari semua node untuk analisis terpusat.
-
Pelacakan: Gunakan pelacakan terdistribusi untuk melacak permintaan di seluruh layanan.
Membahas Mendalam: Keamanan dan Izin 🔒
Keamanan bukan sesuatu yang dipikirkan belakangan; harus diintegrasikan ke dalam proses penyebaran.
1. Hak Akses Minimum
Layanan hanya boleh memiliki izin yang diperlukan untuk berfungsi. Layanan dengan izin berlebihan meningkatkan permukaan serangan.
-
Peran: Tentukan peran khusus untuk layanan yang berbeda.
-
Kebijakan: Terapkan kebijakan yang membatasi akses ke sumber daya tertentu.
-
Audit:Secara rutin audit izin untuk memastikan kepatuhan.
2. Keamanan Jaringan
Pemisahan jaringan membatasi jangkauan dampak dari kemungkinan pelanggaran keamanan.
-
VLANs:Pisahkan lalu lintas berdasarkan fungsi atau lingkungan.
-
Firewall:Blokir lalu lintas yang tidak sah di tepi jaringan.
-
Enkripsi:Enkripsi semua data yang sedang dalam perjalanan antar node.
Integritas Pipeline dan Otomasi 🔄
Pipeline yang memindahkan kode dari pengembangan ke produksi merupakan komponen kritis dari arsitektur penyebaran. Jika pipeline gagal, tidak ada kode yang sampai ke lingkungan.
1. Tahapan Pipeline
Pecah pipeline menjadi tahapan yang berbeda untuk memisahkan kegagalan.
-
Bangun:Kompilasi kode dan buat artefak.
-
Uji:Jalankan uji otomatis untuk memverifikasi fungsi.
-
Deploy:Kirim artefak ke lingkungan target.
-
Verifikasi:Lakukan pemeriksaan setelah penyebaran.
2. Prosedur Rollback
Ketika penyebaran gagal, rollback cepat meminimalkan waktu henti.
-
Versi:Simpan versi sebelumnya dari artefak agar tetap tersedia.
-
Otomasi:Otomatiskan proses rollback untuk mengurangi kesalahan manusia.
-
Uji Coba:Uji prosedur rollback secara rutin untuk memastikan berfungsi dengan baik.
Observabilitas dan Log 🔍
Observabilitas memberikan wawasan mengenai keadaan internal sistem. Tanpa itu, pemecahan masalah menjadi tebakan.
1. Pencatatan Terpusat
Kumpulkan log dari semua node di lokasi terpusat untuk analisis yang lebih mudah.
-
Agregasi:Gunakan pengumpul log untuk mengumpulkan data.
-
Indeksing:Indeks log untuk pencarian yang cepat.
-
Retensi:Tentukan kebijakan retensi untuk mengelola penyimpanan.
2. Metrik dan Dashboard
Visualisasikan indikator kinerja utama untuk mengidentifikasi anomali dengan cepat.
-
Metrik Kunci:Pantau tingkat permintaan, tingkat kesalahan, dan latensi.
-
Peringatan:Atur peringatan untuk ambang batas metrik.
-
Visualisasi:Gunakan dashboard untuk menampilkan data seiring waktu.
Respons Insiden dan Pemulihan 🚨
Bahkan dengan perencanaan terbaik, insiden tetap akan terjadi. Memiliki rencana respons menjamin pemulihan yang cepat.
1. Klasifikasi Insiden
Kategorikan insiden berdasarkan tingkat keparahan dan dampaknya.
-
Kritis:Sistem sedang down atau data telah dirusak.
-
Tinggi:Penurunan signifikan terhadap layanan.
-
Sedang:Masalah kecil yang memengaruhi sebagian pengguna.
-
Rendah:Masalah estetika atau masalah yang tidak mendesak.
2. Komunikasi
Jaga agar pemangku kepentingan tetap diberi tahu sepanjang insiden.
-
Pembaruan Status:Berikan pembaruan rutin mengenai kemajuan.
-
Post-Mortem:Analisis insiden setelah penyelesaian.
-
Item Tindakan:Tugaskan tugas untuk mencegah terulangnya kejadian.
Dokumentasi dan Kontrol Versi 📝
Dokumentasi memastikan pengetahuan tetap terjaga dan dibagikan. Kontrol versi memastikan perubahan tercatat.
1. Dokumentasi Arsitektur
Jaga diagram penyebaran tetap diperbarui.
-
Perubahan:Dokumentasikan setiap perubahan pada arsitektur.
-
Ketergantungan:Daftar semua ketergantungan eksternal dan internal.
-
Prosedur:Dokumentasikan prosedur operasional standar.
2. Manajemen Perubahan
Kontrol bagaimana perubahan dilakukan pada lingkungan.
-
Ulasan:Mewajibkan ulasan untuk perubahan signifikan.
-
Persetujuan:Dapatkan persetujuan sebelum menerapkan perubahan.
-
Pelacakan:Lacak semua perubahan dalam sistem.
Pertimbangan Akhir untuk Kesehatan Penyebaran 🏥
Menjaga arsitektur penyebaran yang sehat membutuhkan upaya terus-menerus. Ulasan dan pembaruan rutin diperlukan agar tetap sesuai dengan persyaratan yang berubah. Fokus pada area-area berikut untuk menjamin stabilitas jangka panjang.
-
Audit Berkala:Lakukan audit berkala terhadap arsitektur.
-
Perencanaan Kapasitas: Rencanakan pertumbuhan di masa depan.
-
Pelatihan: Latih tim tentang metodologi pemecahan masalah.
-
Otomasi: Otomatiskan tugas-tugas berulang untuk mengurangi kesalahan manusia.
-
Pengujian: Uji arsitektur secara rutin di lingkungan staging.
Dengan mengikuti pendekatan terstruktur dalam pemecahan masalah, tim dapat menyelesaikan masalah lebih cepat dan mengurangi waktu henti. Tujuannya bukan hanya memperbaiki masalah, tetapi membangun sistem yang tangguh dan mudah dipelihara. Diagram penyebaran adalah dokumen yang hidup dan harus berkembang bersama infrastruktur. Ketika hal ini terjadi, arsitektur tetap selaras dengan kebutuhan bisnis.
Ingatlah bahwa setiap kegagalan adalah kesempatan untuk belajar. Mendokumentasikan akar penyebab dan solusinya membantu mencegah masalah serupa di masa depan. Basis pengetahuan ini menjadi aset berharga bagi seluruh organisasi.

