












व्यवसाय प्रक्रिया मॉडल और नोटेशन (BPMN) की जटिल दुनिया में, नियंत्रण का प्रवाह रेखीय और पूर्वानुमानित होने के लिए डिज़ाइन किया गया है। हालांकि, वास्तविक दुनिया के संचालन बहुत ही सरल नहीं होते हैं। सिस्टम विफल हो जाते हैं, डेटा सत्यापन टूट जाता है, और बाहरी निर्भरताएं ऑफलाइन हो जाती हैं। इसी जगह पर एरर इवेंट्स महत्वपूर्ण हो जाते हैं। वे एक मानकीकृत तंत्र प्रदान करते हैं जो BPMN विनिर्माण में एक्सेप्शन को बिना समग्र प्रक्रिया मॉडल की अखंडता को नष्ट किए प्रबंधित करने की अनुमति देता है।
प्रभावी एक्सेप्शन हैंडलिंग हर विफलता की भविष्यवाणी करने के बारे में नहीं है। यह तब जब चीजें गलत हो जाएं, तो स्पष्ट मार्ग निर्धारित करने के बारे में है। यह गाइड एरर इवेंट्स के यांत्रिकी, कॉन्फ़िगरेशन और रणनीतिक अनुप्रयोग का अध्ययन करता है ताकि आपके वर्कफ्लो लचीले रहें। हम विभिन्न प्रकार के एरर ट्रिगर्स के बीच अंतर कैसे करें, एरर कोड को सही तरीके से कॉन्फ़िगर करें, और स्पष्ट प्रक्रिया डिज़ाइन बनाए रखें, इसका अध्ययन करेंगे।
एरर इवेंट्स की मूल अवधारणा को समझना ⚙️
एक एरर इवेंट एक विशिष्ट प्रकार का इवेंट है जो प्रक्रिया या वातावरण के भीतर एक विफलता की स्थिति के कारण ट्रिगर होता है। संदेश इवेंट्स के बाहरी संचार पर निर्भर होने या सिग्नल इवेंट्स के पूरे इंजन तक प्रसारित करने के विपरीत, एरर इवेंट्स एक विशिष्ट कार्य या गतिविधि के निष्पादन प्रवाह से निकटता से जुड़े होते हैं।
जब कोई प्रक्रिया उदाहरण समस्या से निपटता है, तो इंजन को यह जानने की आवश्यकता होती है कि निष्पादन कहां विचलित किया जाए। एरर इवेंट्स इस विचलन के लिए संकेतक के रूप में कार्य करते हैं। वे मॉडल को सुखद मार्ग (सामान्य निष्पादन) और दुखद मार्ग (एक्सेप्शन हैंडलिंग) को अलग करने की अनुमति देते हैं।
मुख्य विशेषताएं शामिल हैं:
- विशिष्टता: वे आमतौर पर उन कार्यों से जुड़े होते हैं जो विफलता के लिए जाने जाते हैं।
- प्रसारण: यदि स्थानीय रूप से पकड़े नहीं गए, तो वे श्रेणी में ऊपर तक बुलबुला बना सकते हैं।
- मानकीकरण: वे अंतरोपयोगिता के लिए BPMN 2.0 विनिर्माण का पालन करते हैं।
BPMN में एरर इवेंट्स के प्रकार 📋
एक वर्कफ्लो आरेख में एरर हैंडलिंग के दो मुख्य तरीके हैं। सही एक चुनना उस विफलता के विस्तार पर निर्भर करता है जिसे आप रिकॉर्ड करना चाहते हैं।
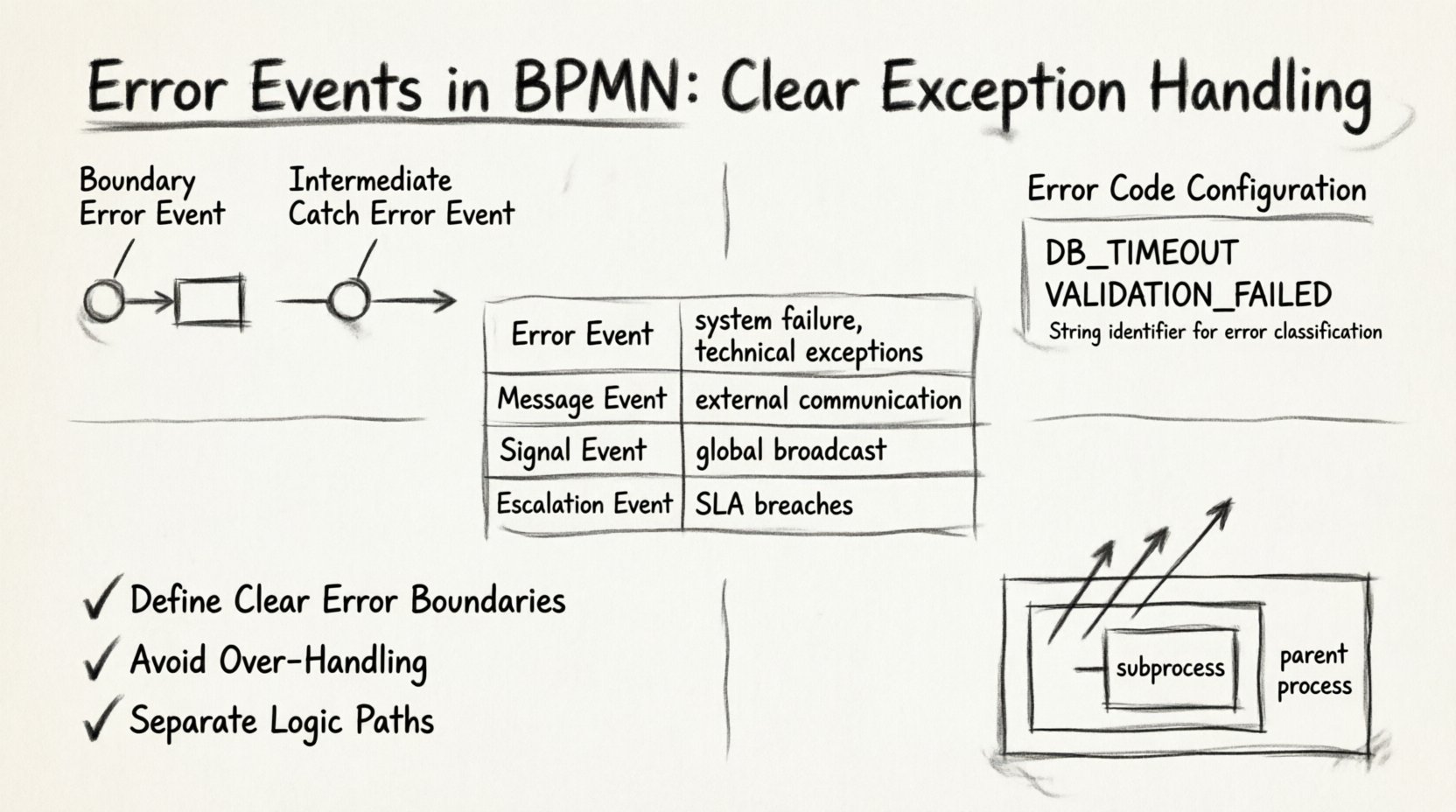
1. बाउंड्री एरर इवेंट्स 🎯
एक बाउंड्री एरर इवेंट एक कार्य, उपप्रक्रिया या कॉल गतिविधि की सीमा के सीधे बाहर लगाया जाता है। यह स्थानीय एक्सेप्शन हैंडलर का प्रतिनिधित्व करता है। यदि कार्य निष्पादित होता है और एक एरर फेंकता है, तो प्रवाह तुरंत बाउंड्री इवेंट से जुड़े मार्ग की ओर विचलित हो जाता है।
यह विशिष्ट विफलताओं को संभालने के लिए सबसे आम पैटर्न है। यह आपको गतिविधि के सीमा के भीतर त्रुटि को अलग करने की अनुमति देता है। उदाहरण के लिए, यदि डेटाबेस लेखन कार्य विफल हो जाता है, तो एक बाउंड्री इवेंट उस विशिष्ट विफलता को पकड़ सकता है बिना पूरे प्रक्रिया उदाहरण को रोके।
बाउंड्री इवेंट्स के लाभ:
- संवर्धन: एक्सेप्शन हैंडलिंग तर्क दृश्य रूप से उस कार्य के पास स्थित होता है जिसे वह सुरक्षित करता है।
- गैर-अवरोधक: मुख्य कार्य तब तक जारी रहता है जब तक एरर नहीं आता।
- स्पष्टता: आरेख स्पष्ट रूप से दिखाता है कि कौन से कार्यों में फॉलबैक तंत्र हैं।
2. मध्यवर्ती ग्रहण एरर इवेंट्स 🔄
एक मध्यवर्ती ग्रहण एरर इवेंट अनुक्रम प्रवाह पर बैठता है, एक कार्य सीमा से जुड़े होने के बजाय। इस प्रकार का इवेंट कम आम है लेकिन कार्यों के बीच या उपप्रक्रिया के भीतर होने वाली त्रुटियों को संभालने के लिए उपयोगी है जिसे मुख्य दायरे में पकड़ने की आवश्यकता होती है।
इस दृष्टिकोण का उपयोग अक्सर तब किया जाता है जब आप उन त्रुटियों को पकड़ना चाहते हैं जो उपप्रक्रिया से बाहर फैलती हैं लेकिन अभी तक मुख्य प्रक्रिया की सीमा तक नहीं पहुंची हैं। इससे एक विशिष्ट तर्क ब्लॉक के लिए केंद्रीकृत एरर प्रबंधन की अनुमति मिलती है।
कॉन्फ़िगरेशन और विशेषताएँ ⚙️
त्रुटि घटनाओं को कार्यात्मक बनाने के लिए, उन्हें मॉडलिंग टूल और निष्पादन इंजन के भीतर विशिष्ट कॉन्फ़िगरेशन की आवश्यकता होती है। इन कॉन्फ़िगरेशन्स के द्वारा त्रुटि क्या है और प्रणाली कैसे प्रतिक्रिया करती है, इसका निर्धारण किया जाता है।
त्रुटि कोड परिभाषा
प्रत्येक त्रुटि घटना को एक अद्वितीय होना चाहिएत्रुटि कोडयह एक स्ट्रिंग पहचानकर्ता है जो एक प्रकार की त्रुटि को दूसरी प्रकार की त्रुटि से अलग करता है। परिभाषित कोड के बिना, इंजन डेटाबेस समयांतर और सत्यापन विफलता के बीच अंतर नहीं कर सकता है।
- स्ट्रिंग पहचानकर्ता: एक संगत नामकरण पद्धति का उपयोग करें, जैसे कि
DB_TIMEOUTयाVALIDATION_FAILED. - विस्तार: सामान्य कोड जैसे कि बचें
ERROR_1विवरणात्मक पहचानकर्ताओं का उपयोग करें जो डिबगिंग में सहायता करें। - मैपिंग: सुनिश्चित करें कि बाहरी प्रणाली या स्क्रिप्ट घटना में परिभाषित ठीक कोड फेंके।
संदेश संबंध
कुछ कार्यान्वयन त्रुटि घटना को एक विशिष्ट संदेश परिभाषा से जोड़ने की अनुमति देते हैं। इससे त्रुटि को मानव-पठनीय संदेश से जोड़ा जाता है जिसे उपयोगकर्ता इंटरफेस में प्रदर्शित किया जा सकता है या लॉग किया जा सकता है।
- उपयोगकर्ता प्रतिक्रिया: प्रणाली को उपयोगकर्ता को बताने में सक्षम बनाता है कि क्या गलत हुआ।
- लॉगिंग: स्वचालित लॉगिंग प्रणालियों को त्रुटि प्रकार के आधार पर घटनाओं को वर्गीकृत करने में सहायता करता है।
त्रुटि निवारण रणनीतियों की तुलना 📊
BPMN के व्यापक संदर्भ में त्रुटि घटनाओं के स्थान को समझना आवश्यक है। नीचे घटना प्रकारों की तुलना दी गई है ताकि स्पष्ट हो कि त्रुटि घटना कब उपयोग करनी चाहिए और अन्य विकल्पों के बजाय कब नहीं।
| घटना प्रकार | ट्रिगर स्रोत | सामान्य उपयोग केस | परिसर |
|---|---|---|---|
| त्रुटि घटना | सिस्टम/कार्य विफलता | तकनीकी त्रुटियाँ, सत्यापन विफलताएँ | स्थानीय या प्रक्रिया |
| संदेश घटना | बाहरी संचार | उत्तर का इंतजार, डेटा प्राप्त करना | प्रक्रिया उदाहरण |
| सिग्नल घटना | वैश्विक प्रसारण | बहुत सारे उदाहरणों को रद्द करना, प्रणाली-स्तरीय चेतावनियाँ | वैश्विक |
| उत्क्रमण घटना | प्रक्रिया नियम | एसएलए के उल्लंघन, मैन्युअल हस्तक्षेप की आवश्यकता | प्रक्रिया पदानुक्रम |
दृढ़ता के लिए डिज़ाइन करना: सर्वोत्तम प्रथाएँ 🛡️
त्रुटियों को बेहतर तरीके से संभालने वाले प्रक्रिया मॉडल का निर्माण करने के लिए रणनीतिक दृष्टिकोण की आवश्यकता होती है। बस एक घटना को आरेख पर रखने के लिए पर्याप्त नहीं है; उसके चारों ओर की तर्कसंगतता को मजबूत होना चाहिए।
1. स्पष्ट त्रुटि सीमाएँ निर्धारित करें
वे त्रुटियाँ न ग्रहण करें जो प्रक्रिया को समाप्त करने के लिए होनी चाहिए। कुछ विफलताएँ अपुनर्जीवनीय होती हैं। यदि प्रक्रिया को विशिष्ट डेटा के बिना आगे बढ़ने में असमर्थ है, तो त्रुटि को ग्रहण करना और अनंत तक पुनर्प्रयास करना ज़ोम्बी प्रक्रिया के रूप में ले जाता है। इसके बजाय, त्रुटि को उच्च स्तर तक ऊपर उठने दें या उदाहरण को स्पष्ट रूप से समाप्त करें।
- महत्वपूर्ण कार्यों की पहचान करें:यह निर्धारित करें कि कौन से कार्य प्रक्रिया के कार्यान्वयन के लिए आवश्यक हैं।
- महान त्रुटियों पर समाप्त करें:प्रक्रिया आगे नहीं बढ़ सकती है, इसका संकेत देने के लिए त्रुटि घटनाओं का उपयोग करें।
- अस्थायी त्रुटियों पर पुनर्प्रयास करें:नेटवर्क समय सीमा समाप्त होने या अस्थायी उपलब्धता न होने के लिए सीमा घटनाओं का उपयोग करें।
2. अत्यधिक प्रबंधन से बचें
प्रत्येक कार्य को त्रुटि हैंडलर की आवश्यकता नहीं होती है। प्रत्येक कार्य में सीमा घटनाओं को जोड़ने से आरेख भारी हो जाता है और प्रवाह पढ़ने में कठिनाई होती है। केवल उन कार्यों में ही त्रुटि घटनाओं को जोड़ें जिन्हें जाना जाता है कि वे विफल हो सकते हैं या यदि वे विफल होते हैं तो उनके महत्वपूर्ण परिणाम होंगे।
3. तर्क पथों को अलग करें
यह सुनिश्चित करें कि त्रुटि के बाद लिया गया पथ सामान्य पथ से अलग हो। यदि त्रुटि पथ अंततः मुख्य प्रवाह में वापस जुड़ता है, तो उन्हें स्पष्ट रूप से मिलाने के लिए एक अद्वितीय गेटवे का उपयोग करें। त्रुटि प्रबंधन तर्क को व्यापार तर्क के साथ मिलाएं नहीं।
डेटा मैपिंग और प्रसार 📡
जब कोई त्रुटि होती है, तो डेटा अक्सर खो जाता है जब तक कि इसे स्पष्ट रूप से मैप नहीं किया जाता है। त्रुटि घटनाओं के सबसे अनदेखे पहलू में से एक चरों के प्रबंधन है।
त्रुटि डेटा स्थिरता
जब कोई अपवाद पकड़ा जाता है, तो सिस्टम आमतौर पर विफलता के बारे में जानकारी स्टोर करता है। इसमें त्रुटि कोड, समयचिह्न और विफलता के क्षण पर चरों की स्थिति शामिल हो सकती है।
- चर अभिलेखन:इंजन को त्रुटि के समय प्रक्रिया चरों की स्थिति सहेजने के लिए कॉन्फ़िगर करें।
- संदर्भ संरक्षण:सुनिश्चित करें कि त्रुटि हैंडलर को उस डेटा तक पहुंच हो जिसने विफलता का कारण बनाया।
त्रुटियों को ऊपर उठाना
यदि एक उपप्रक्रिया त्रुटि फेंकती है और उपप्रक्रिया के पकड़ने के लिए कोई सीमा घटना नहीं है, तो त्रुटि मुख्य प्रक्रिया तक ऊपर उठ जाती है। यह आरोही प्रक्रिया डिज़ाइन के लिए एक महत्वपूर्ण विशेषता है।
- मुख्य प्रक्रिया का प्रबंधन: मुख्य प्रक्रिया बच्चे की विफलता के प्रति कैसे प्रतिक्रिया करनी है, इसका निर्णय ले सकती है।
- सामान्य पुनर्स्थापना: संबंधित कार्यों के सेट के लिए केंद्रीकृत पुनर्स्थापना रणनीति की अनुमति देता है।
मानव कार्य त्रुटि प्रबंधन 👤
प्रक्रिया मॉडल में अक्सर मानव भागीदार शामिल होते हैं। जब कोई मानव कार्य विफल होता है, तो त्रुटि घटना एक सिस्टम कार्य की तुलना में थोड़ी अलग तरीके से व्यवहार करती है।
- कार्य त्याग: यदि एक उपयोगकर्ता किसी कार्य को त्याग देता है, तो इससे त्रुटि घटना चालू हो सकती है।
- समय सीमा: यदि किसी कार्य को निर्धारित समय के भीतर पूरा नहीं किया जाता है, तो एक उन्नयन या त्रुटि चालू की जा सकती है।
- पुनर्निर्देशन: यदि मूल निर्धारित व्यक्ति विफल हो जाता है, तो त्रुटि घटनाएं कार्य को एक अलग उपयोगकर्ता या कतार में रास्ता बना सकती हैं।
मानव कार्यों के लिए डिज़ाइन करते समय, त्रुटि मार्ग अक्सर सूचना तंत्र को शामिल करता है। यह एक ईमेल चेतावनी या सुपरवाइज़र को डैशबोर्ड सूचना हो सकती है।
परीक्षण और मान्यता 🔍
जब मॉडल बन जाता है, तो उसका परीक्षण किया जाना चाहिए ताकि त्रुटि मार्ग इच्छित तरीके से काम करें। स्थैतिक विश्लेषण पर्याप्त नहीं है।
सिमुलेशन परिदृश्य
प्रक्रिया सिमुलेशन चलाएं जो जानबूझकर त्रुटियों को ट्रिगर करें। सत्यापित करें कि:
- सीमा घटना सही तरीके से सक्रिय होती है।
- प्रक्रिया अपवाद प्रवाह का पालन करती है।
- डेटा को उचित रूप से सुरक्षित रखा या लॉग किया गया है।
- प्रक्रिया अनंत पुनर्प्रयासों के लूप में नहीं जाती है।
कोड कवरेज
सुनिश्चित करें कि त्रुटि संभालने की तर्क अपेक्षित विफलता परिदृश्यों की सीमा को कवर करता है। इसमें शामिल है:
- नेटवर्क कनेक्टिविटी की समस्याएं।
- अमान्य डेटा इनपुट।
- बाहरी API उपलब्ध नहीं होना।
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी मॉडलर त्रुटि घटनाओं के कार्यान्वयन के समय गलतियां करते हैं। सामान्य समस्याओं के प्रति जागरूकता एक टिकाऊ मॉडल को बनाए रखने में मदद करती है।
- त्रुटि कोड की अनुपस्थिति:इंजन कॉन्फ़िगरेशन में त्रुटि कोड को परिभाषित करने में विफलता से चुप्पी वाली विफलताएं होती हैं।
- पहुंच नहीं बनाने वाले मार्ग:तर्क सीमाओं के कारण कभी भी पहुंच नहीं बनाए जा सकने वाले त्रुटि मार्ग बनाना।
- लॉग को नजरअंदाज करना:एक त्रुटि को पकड़ना और उसके साथ कुछ नहीं करना। त्रुटि को हमेशा लॉग एंट्री या सूचना ट्रिगर करनी चाहिए।
- जटिल मर्जिंग:त्रुटि के कारण को अलग किए बिना बहुत सारे त्रुटि मार्गों को एक ही गेटवे में मिलाना।
अपवाद डिजाइन पर निष्कर्ष 🎓
त्रुटि घटनाओं को डिज़ाइन करने के लिए तकनीकी सटीकता और संचालन व्यावहारिकता के बीच संतुलन आवश्यक होता है। विशिष्ट प्रकार की घटनाओं को समझने, उन्हें सही तरीके से कॉन्फ़िगर करने और स्थापित बेस्ट प्रैक्टिस का पालन करने से आप विफलता के खिलाफ टिकाऊ प्रक्रियाएं बना सकते हैं।
लक्ष्य त्रुटियों को समाप्त करना नहीं है, जो असंभव है, बल्कि उन्हें कुशलता से प्रबंधित करना है। स्पष्ट अपवाद संभालने वाले एक अच्छी तरह से बनाए गए BPMN मॉडल से डाउनटाइम कम होता है, विफलताओं में दृश्यता में सुधार होता है, और यह सुनिश्चित करता है कि व्यापार संचालन तेजी से बहाल हो सकें। अपने कार्यों की विशिष्ट आवश्यकताओं पर ध्यान केंद्रित करें, स्पष्ट कोड परिभाषित करें, और विफलता के मार्गों का कठोर रूप से परीक्षण करें। इस दृष्टिकोण से विश्वसनीय वर्कफ्लो बनते हैं जो वास्तविक दुनिया की जटिलता के खिलाफ टिक सकते हैं।

