












W złożonym świecie modelowania i notacji procesów biznesowych (BPMN) przepływ sterowania jest zaprojektowany jako liniowy i przewidywalny. Jednak rzeczywiste operacje rzadko są tak proste. Systemy zawodzą, walidacja danych się zawiesza, a zewnętrzne zależności są niedostępne. To właśnie tutajzdarzenia błędówstają się krytyczne. Zapewniają one standardowy mechanizm w specyfikacji BPMN do zarządzania wyjątkami bez naruszania integralności ogólnego modelu procesu.
Skuteczna obsługa wyjątków nie polega na przewidywaniu każdego możliwego niepowodzenia. Polega na zdefiniowaniu jasnego przebiegu, gdy rzeczywiście coś pójdzie nie tak. Ten przewodnik bada mechanizmy, konfiguracje i strategiczne zastosowanie zdarzeń błędów, aby zapewnić odporność Twoich przepływów pracy. Przeanalizujemy, jak rozróżnić różne typy wyzwalaczy błędów, poprawnie skonfigurować kody błędów oraz utrzymać czysty projekt procesu.
Zrozumienie podstawowego pojęcia zdarzeń błędów ⚙️
Zdarzenie błędów to specyficzny rodzaj zdarzenia wywoływany warunkiem awarii wewnątrz procesu lub środowiska. W przeciwieństwie do zdarzeń komunikatów, które opierają się na komunikacji zewnętrznej, lub zdarzeń sygnałów, które rozsyłają informacje do całego silnika, zdarzenia błędów są ściśle powiązane z przepływem wykonania konkretnej zadania lub aktywności.
Gdy instancja procesu napotka problem, silnik musi wiedzieć, gdzie przekierować wykonanie. Zdarzenia błędów działają jak wskazówki w tym przekierowaniu. Pozwalają one na rozdzielenie ścieżki pozytywnej (normalne wykonanie) od ścieżki negatywnej (obsługa wyjątków).
Kluczowe cechy to:
- Specyficzność: Zazwyczaj są przypisane do zadań, które są znane z tendencji do awarii.
- Rozprzestrzenianie: Mogą się przemieszczać w górę hierarchii, jeśli nie zostaną złapane lokalnie.
- Standardyzacja: Dostosowują się do specyfikacji BPMN 2.0 w celu zapewnienia interoperacyjności.
Rodzaje zdarzeń błędów w BPMN 📋
Istnieją dwa główne sposoby implementacji obsługi błędów w diagramie przepływu pracy. Wybór odpowiedniego zależy od szczegółowości awarii, którą chcesz zarejestrować.
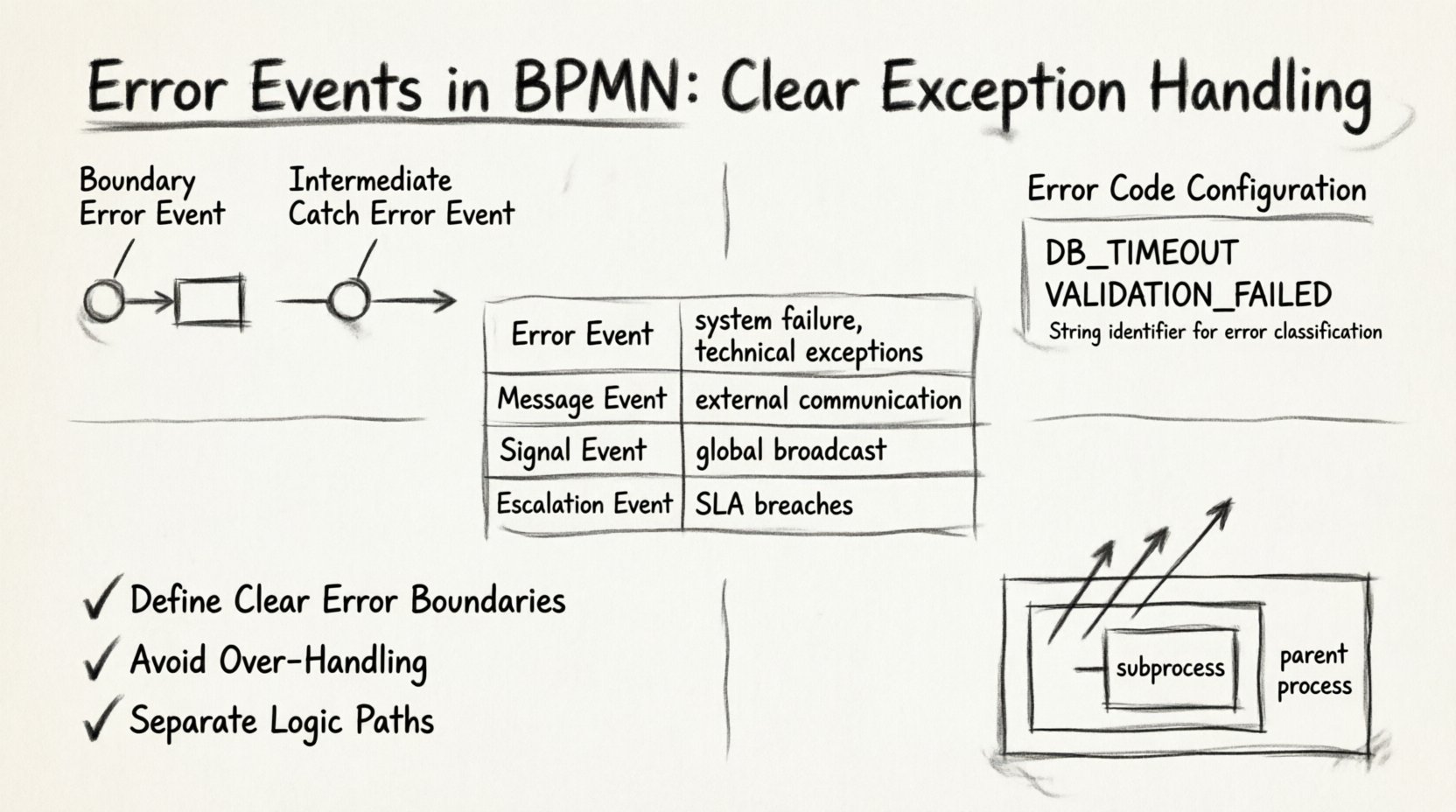
1. Zdarzenia błędów brzegowe 🎯
Zdarzenie błędów brzegowe jest bezpośrednio przypisane do brzegu zadania, podprocesu lub aktywności wywołania. Reprezentuje lokalny obsługę wyjątków. Jeśli zadanie zostanie wykonane i wygeneruje błąd, przepływ natychmiast zmienia kierunek na ścieżkę połączoną z zdarzeniem brzegowym.
Jest to najbardziej powszechny wzorzec obsługi określonych awarii. Pozwala on na izolację błędu w zakresie danej aktywności. Na przykład, jeśli operacja zapisu do bazy danych nie powiedzie się, zdarzenie brzegowe może złapać ten konkretny błąd bez zatrzymywania całej instancji procesu.
Zalety zdarzeń brzegowych:
- Zamknięcie (enkapsulacja): Logika obsługi wyjątków jest wizualnie umieszczona obok zadania, które chroni.
- Nieblokujące:Główne zadanie kontynuuje działanie, aż do wystąpienia błędu.
- Jasność:Diagram jasno pokazuje, które zadania mają mechanizmy alternatywne.
2. Zdarzenia przechwytywania błędów pośrednich 🔄
Zdarzenie przechwytywania błędów pośrednich znajduje się na przepływie sekwencji, a nie jest przypisane do brzegu zadania. Ten typ jest mniej powszechny, ale przydatny do obsługi błędów występujących między zadaniami lub wewnątrz podprocesu, który ma zostać złapany w zakresie nadrzędnym.
Ten podejście często stosuje się, gdy chcesz złapać błędy, które rozprzestrzeniają się poza podproces, ale jeszcze nie osiągnęły granicy głównego procesu. Pozwala to na centralne zarządzanie błędami dla konkretnego bloku logiki.
Konfiguracja i atrybuty ⚙️
Aby zdarzenia błędów działały poprawnie, wymagają określonej konfiguracji w narzędziu modelowania i silniku wykonawczym. Te konfiguracje definiują, co stanowi błąd, oraz jak system na nie reaguje.
Definicja kodu błędu
Każde zdarzenie błędu powinno mieć unikalny Kod błędu. Jest to identyfikator typu string, który rozróżnia jeden rodzaj błędu od drugiego. Bez zdefiniowanego kodu silnik nie może rozróżnić między przekroczonym timeoutem bazy danych a niepowodzeniem walidacji.
- Identyfikator typu string: Używaj spójnej konwencji nazewnictwa, np.
DB_TIMEOUTlubVALIDATION_FAILED. - Szczegółowość: Unikaj ogólnych kodów takich jak
ERROR_1. Używaj opisowych identyfikatorów, które ułatwiają debugowanie. - Mapowanie: Upewnij się, że zewnętrzny system lub skrypt rzuca dokładnie ten kod, który został zdefiniowany w zdarzeniu.
Powiązanie z wiadomością
Niektóre implementacje pozwalają powiązać zdarzenie błędu z konkretną definicją wiadomości. Powoduje to połączenie błędu z czytelną dla człowieka wiadomością, którą można wyświetlić w interfejsie użytkownika lub zalogować.
- Informacja dla użytkownika: Pozwala systemowi dokładnie poinformować użytkownika, co poszło nie tak.
- Rejestrowanie: Ułatwia systemom automatycznego rejestrowania kategoryzowanie incydentów według typu błędu.
Porównanie strategii obsługi błędów 📊
Zrozumienie, gdzie zdarzenia błędów pasują do szerszego kontekstu BPMN, jest istotne. Poniżej znajduje się porównanie typów zdarzeń, które wyjaśniają, kiedy należy użyć zdarzenia błędu zamiast innych opcji.
| Typ zdarzenia | Źródło wyzwalania | Typowy przypadek użycia | Zakres |
|---|---|---|---|
| Zdarzenie błędu | Awaria systemu/zadania | Wyjątki techniczne, błędy weryfikacji | Lokalne lub procesowe |
| Zdarzenie komunikatu | Komunikacja zewnętrzna | Czekanie na odpowiedź, odbieranie danych | Instancja procesu |
| Zdarzenie sygnału | Globalny rozgłos | Anulowanie wielu instancji, sygnały systemowe | Globalne |
| Zdarzenie eskalacji | Zasady procesu | Naruszenia SLA, wymagania interwencji ręcznej | Hierarchia procesu |
Projektowanie odporności: Najlepsze praktyki 🛡️
Tworzenie modelu procesu, który poradzi sobie z błędami zgodnie z zasadami, wymaga strategicznego podejścia. Nie wystarczy po prostu umieścić zdarzenia na schemacie; logika otaczająca je musi być poprawna.
1. Ustal jasne granice błędów
Nie przechwytywaj błędów, które powinny zakończyć proces. Niektóre błędy są nieodwracalne. Jeśli proces nie może kontynuować bez określonych danych, przechwytywanie błędu i nieustanne ponawianie próby prowadzi do procesu zombie. Zamiast tego pozwól błędowi dotrzeć do wyższego poziomu lub zakończyć instancję w sposób czysty.
- Zidentyfikuj zadania krytyczne:Określ, które zadania są niezbędne dla działania procesu.
- Zakończ w przypadku błędów krytycznych:Użyj zdarzeń błędów, aby sygnalizować, że proces nie może kontynuować.
- Powtarzaj w przypadku błędów tymczasowych:Użyj zdarzeń granicznych w przypadku przekroczenia limitu czasu sieciowego lub tymczasowej niedostępności.
2. Unikaj nadmiernego przetwarzania
Każde zadanie nie musi mieć obsługi błędów. Dodawanie zdarzeń granicznych do każdego zadania zanieczyszcza schemat i utrudnia odczytanie przebiegu. Przypisz zdarzenia błędów tylko do tych zadań, które są znane z błędów lub które mają istotne konsekwencje w przypadku niepowodzenia.
3. Oddziel ścieżki logiki
Upewnij się, że ścieżka po błędzie jest inna niż normalna ścieżka. Jeśli ścieżka błędów w końcu łączy się z głównym przebiegiem, użyj wyłącznego przejścia do ich czystego połączenia. Nie mieszkaj logiki obsługi błędów z logiką biznesową.
Mapowanie danych i ich propagacja 📡
Gdy występuje błąd, dane często ulegają utracie, chyba że są jawnie przypisane. Jednym z najbardziej pomijanych aspektów zdarzeń błędów jest obsługa zmiennych.
Trwałość danych o błędach
Gdy wyjątek zostaje złapany, system zwykle przechowuje informacje o niepowodzeniu. Mogą to być kod błędu, znacznik czasu oraz stan zmiennych w momencie niepowodzenia.
- Zachowanie zmiennych:Skonfiguruj silnik w taki sposób, aby zapisywał stan zmiennych procesu w przypadku błędu.
- Zachowanie kontekstu:Upewnij się, że obsługujący błędy ma dostęp do danych, które spowodowały niepowodzenie.
Przepływ błędów do wyższych poziomów
Jeśli podproces zgłasza błąd, a podproces nie ma zdarzenia brzegowego, które go złapie, błąd przepływa do procesu nadrzędnego. Jest to kluczowa cecha dla projektowania hierarchicznego procesów.
- Obsługa przez proces nadrzędny:Proces nadrzędny może decydować, jak reagować na niepowodzenie dziecka.
- Ogólna odbudowa:Zezwala na zcentralizowaną strategię odbudowy dla zestawu powiązanych zadań.
Obsługa błędów zadań ludzkich 👤
Modele procesów często obejmują uczestników ludzkich. Gdy zadanie ludzkie zawiedzie, zdarzenie błędu zachowuje się nieco inaczej niż zadanie systemowe.
- Zaniechanie zadania:Jeśli użytkownik zaniecha zadania, może to spowodować wywołanie zdarzenia błędu.
- Przekroczenia czasu:Jeśli zadanie nie zostanie ukończone w ustalonym czasie, może zostać wywołana eskalacja lub błąd.
- Przypisanie ponowne:Zdarzenia błędów mogą przekierować zadanie do innego użytkownika lub kolejki, jeśli oryginalny przypisany nie powiedzie się.
Podczas projektowania zadań ludzkich ścieżka błędów często obejmuje mechanizm powiadomień. Może to być powiadomienie e-mail lub powiadomienie na pulpicie dla nadzorcy.
Testowanie i weryfikacja 🔍
Po zbudowaniu modelu musi zostać przetestowany, aby upewnić się, że ścieżki błędów działają zgodnie z oczekiwaniami. Analiza statyczna nie wystarcza.
Scenariusze symulacji
Uruchom symulacje procesów, które celowo wywołują błędy. Upewnij się, że:
- Zdarzenie brzegowe aktywuje się poprawnie.
- Proces przepływa poprawnie ścieżką wyjątku.
- Dane są zachowywane lub zapisywane odpowiednio.
- Proces nie wchodzi w nieskończoną pętlę ponownych prób.
Obejmowanie kodu
Upewnij się, że logika obsługi błędów obejmuje oczekiwany zakres scenariuszy awarii. Obejmuje to:
- Problemy z łącznością sieciową.
- Nieprawidłowe dane wejściowe.
- Niedostępność zewnętrznych interfejsów API.
Typowe pułapki do unikania ⚠️
Nawet doświadczeni modelerzy popełniają błędy podczas implementacji zdarzeń błędów. Znajomość typowych problemów pomaga w utrzymaniu solidnego modelu.
- Brakujące kody błędów:Nieokreślenie kodu błędu w konfiguracji silnika prowadzi do niezauważalnych awarii.
- Nieosiągalne ścieżki: Tworzenie ścieżek błędów, które nigdy nie mogą zostać osiągnięte z powodu ograniczeń logiki.
- Ignorowanie dzienników: Przechwytywanie błędu i niepodjęcie żadnych działań. Błąd powinien zawsze wywoływać wpis w dzienniku lub powiadomienie.
- Złożone scalania: Scalanie zbyt wielu ścieżek błędów w jednym bramie bez rozróżniania przyczyny błędu.
Wnioski dotyczące projektowania wyjątków 🎓
Projektowanie zdarzeń błędów wymaga równowagi między precyzją techniczną a praktycznym podejściem operacyjnym. Zrozumienie konkretnych typów zdarzeń, poprawna konfiguracja i przestrzeganie ustanowionych najlepszych praktyk pozwala stworzyć procesy odporności na awarie.
Celem nie jest całkowite usunięcie błędów, co jest niemożliwe, ale skuteczne zarządzanie nimi. Dobrze zorganizowany model BPMN z jasną obsługą wyjątków zmniejsza czas przestoju, poprawia widoczność awarii i zapewnia szybkie odbudowanie działalności biznesowej. Skup się na konkretnych potrzebach swoich zadań, określ jasne kody błędów i testuj ścieżki awaryjne z dużą starannością. Taki podejście prowadzi do niezawodnych przepływów pracy, które wytrzymują złożoność rzeczywistego świata.

