












Nowoczesne dostarczanie oprogramowania często opiera się na skomplikowanych systemach zaprojektowanych do przenoszenia kodu z środowisk deweloperskich do środowiska produkcyjnego. Gdy te systemy zawiodą, skutki mogą być znaczne. Diagram wdrażania pełni rolę projektu tych infrastruktur, pokazując węzły, artefakty oraz ich wzajemne interakcje. Jednak diagram jest użyteczny tylko wtedy, gdy jest zgodny z rzeczywistym środowiskiem działania. Gdy pojawiają się rozbieżności, systematyczne rozwiązywanie problemów staje się niezbędne. Niniejszy przewodnik omawia sposób diagnozowania i rozwiązywania problemów w złożonych architekturach wdrażania bez korzystania z konkretnych narzędzi lub produktów dostawcy.
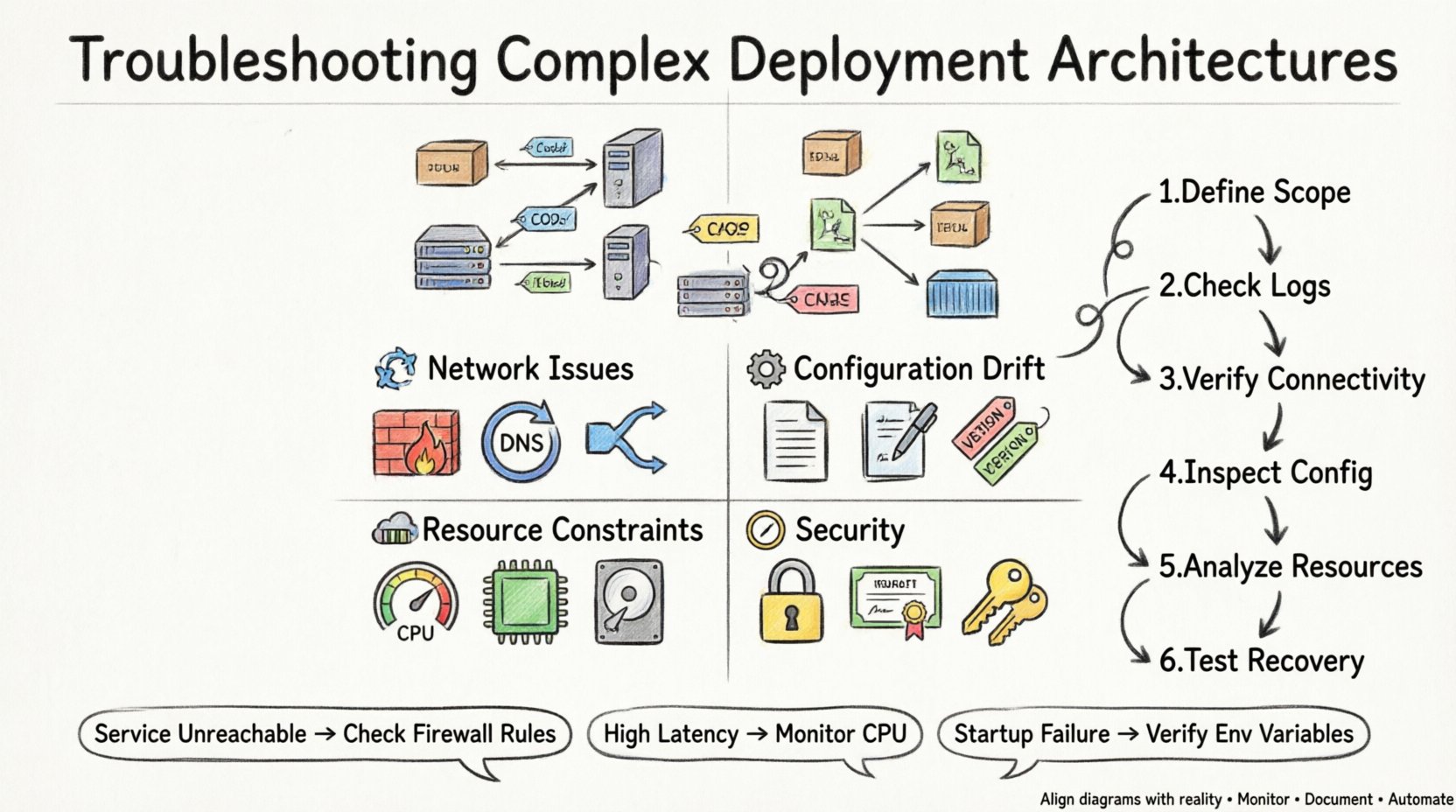
Zrozumienie diagramu wdrażania 📐
Zanim spróbujesz naprawić problem, musisz zrozumieć, co reprezentuje architektura. Diagram wdrażania ilustruje strukturę fizyczną lub logiczną systemu. Dokładnie pokazuje, gdzie znajdują się składniki oprogramowania i jak ze sobą komunikują się. W skomplikowanych konfiguracjach często występuje wiele warstw abstrakcji.
-
Węzły: Odnoszą się do zasobów obliczeniowych, na których wdrażane są artefakty. Mogą to być maszyny fizyczne, wirtualne instancje lub kontenery.
-
Artefakty: Są to pakiety oprogramowania instalowane na węzłach. Obejmują one pliki binarne, pliki konfiguracyjne oraz biblioteki.
-
Połączenia: Określają ścieżki komunikacji między węzłami. Wskazują protokoły, porty oraz typy danych.
-
Zależności: Pokazują wymagania wstępne potrzebne do prawidłowego działania węzła.
Gdy występuje problem, pierwszym krokiem jest porównanie diagramu z aktualnym stanem infrastruktury. Rozbieżności w tym miejscu często są przyczyną awarii.
Typowe tryby awarii ⚠️
Złożone architektury wprowadzają wiele punktów awarii. Zrozumienie typowych trybów awarii pozwala szybko ograniczyć zakres poszukiwań. Problemy zazwyczaj należą do kategorii związanych z łącznością, konfiguracją, zasobami lub bezpieczeństwem.
1. Problemy z łącznością i siecią 🌐
Problemy z siecią są jednym z najczęściej występujących powodów awarii wdrażania. Nawet jeśli diagram pokazuje poprawne połączenie, sieć może blokować ruch.
-
Zasady zapory ogniowej: Porty wymagane do komunikacji mogą być zamknięte przez pośrednie zapory ogniowe lub grupy zabezpieczeń.
-
Rozpoznawanie DNS: Usługi często opierają się na nazwach domen. Jeśli DNS nie jest poprawnie skonfigurowane, węzły nie mogą się wzajemnie znaleźć.
-
Konfiguracja podsieci: Węzły w różnych segmentach sieciowych mogą nie mieć potrzebnych tabel routingu do komunikacji.
-
Balansery obciążenia: Logika dystrybucji ruchu może być źle skonfigurowana, wysyłając żądania do niezdrowych węzłów.
2. Odchylenie konfiguracji ⚙️
Odchylenie konfiguracji występuje, gdy rzeczywisty stan węzła różni się od stanu zamierzonego określonego w planie wdrażania. Zazwyczaj dzieje się to, gdy zmiany ręczne są wprowadzane bezpośrednio w środowisku produkcyjnym.
-
Zmienne środowiskowe:Brakujące lub niepoprawne zmienne mogą powodować awarie uruchamiania usług lub ich nieoczekiwane zachowanie.
-
Uprawnienia plików: Nieprawidłowe uprawnienia do plików konfiguracyjnych mogą uniemożliwić aplikacji odczytanie niezbędnych danych.
-
Różnice w wersjach:Biblioteki lub zależności zainstalowane na węźle mogą nie odpowiadać wersji określonej w artefakcie.
3. Ograniczenia zasobów 💾
Nawet doskonale skonfigurowana architektura zawiedzie, jeśli podstawowe sprzęty nie będą w stanie obsłużyć obciążenia. Wyczerpanie zasobów to cichy zabójca niezawodności wdrażania.
-
Nasycenie procesora:Wysokie wykorzystanie może prowadzić do opóźnień lub wygaśnięcia usług.
-
Wycieki pamięci:Aplikacje, które nie zwalniają pamięci odpowiednio, mogą spowodować, że host wyczerpie pamięć RAM.
-
Przestrzeń dysku:Dzienniki i pliki tymczasowe mogą wypełnić pamięć, uniemożliwiając zapis nowych danych.
-
Przepustowość sieci:Niewystarczająca przepustowość może spowodować niepowodzenie transferu danych między węzłami.
4. Bezpieczeństwo i uprawnienia 🔒
Protokoły bezpieczeństwa są kluczowe dla ochrony danych, ale mogą również blokować prawidłowy ruch, jeśli są zbyt restrykcyjnie skonfigurowane.
-
Zarządzanie dostępem do tożsamości:Konta usług mogą nie mieć uprawnień wymaganych do dostępu do innych zasobów.
-
Weryfikacja certyfikatów:Certyfikaty SSL/TLS, które wygasły lub są samodzielnie podpisane, mogą przerwać połączenia szyfrowane.
-
Tokeny uwierzytelniania:Wygasłe lub nieprawidłowe tokeny mogą uniemożliwić usługom uwierzytelnianie się wzajemnie.
Metodologia diagnostyki 🔍
Podczas rozwiązywania problemów strukturalny podejście zapobiega marnowaniu czasu. Postępuj zgodnie z tymi krokami, aby skutecznie izolować problem.
-
Zdefiniuj zakres:Określ dokładnie, który element architektury się nie powiada. Czy to cały system, konkretny węzeł czy konkretne połączenie?
-
Sprawdź dzienniki:Przejrzyj dzienniki aplikacji i systemu pod kątem komunikatów o błędach. Szukaj godzin, które odpowiadają czasowi wystąpienia błędu.
-
Weryfikuj łączność:Użyj narzędzi sieciowych do testowania dostępności między węzłami. Sprawdź, czy porty są otwarte i odpowiedziane.
-
Sprawdź konfigurację: Porównaj bieżące ustawienia z bazą wyznaczoną na diagramie wdrożenia.
-
Analiza zużycia zasobów: Monitoruj zużycie CPU, pamięci i dysku w oknie awarii.
-
Test odzyskiwania: Spróbuj ponownie uruchomić usługi lub cofnąć zmiany, aby sprawdzić, czy problem zostanie rozwiązany.
Tabela: Najczęstsze objawy vs. działania diagnostyczne 📋
Ta tabela podsumowuje częste objawy oraz odpowiednie działania wymagane do ich zdiagnozowania.
|
Objaw |
Prawdopodobna przyczyna |
Działanie diagnostyczne |
|---|---|---|
|
Usługa niedostępna |
Zapora sieciowa |
Sprawdź grupy zabezpieczeń i zasady zapory |
|
Wysokie opóźnienie |
Nasycenie CPU |
Monitoruj metryki wykorzystania CPU |
|
Niepowodzenie uruchomienia |
Brakująca konfiguracja |
Weryfikuj zmienne środowiskowe i pliki |
|
Reset połączenia |
Wyczerpanie zasobów |
Sprawdź zużycie pamięci i przestrzeni dyskowej |
|
Błąd uwierzytelniania |
Wygaśnięcie certyfikatu |
Sprawdź ważność certyfikatu SSL/TLS |
|
Potok zawiesił się |
Przekroczony limit czasu zależności |
Sprawdź łączność sieciową z zewnętrznymi repozytoriami |
Szczegółowa analiza: Diagnostyka sieciowa 🌐
Problemy sieciowe są szczególnie trudne do rozwiązywania, ponieważ często pojawiają się nieregularnie. Gdy diagram wdrożenia pokazuje połączenie między węzłem A a węzłem B, ale ruch nie płynie, musisz zbadać trasę.
1. Śledzenie trasy
Użyj narzędzi do śledzenia sieci, aby określić, gdzie pakiety są tracone. Pomaga to ustalić, czy problem znajduje się w lokalnej sieci, przez internet lub na węźle docelowym.
-
Przechwytywanie pakietów:Analizuj ruch na źródle i miejscu docelowym, aby sprawdzić, czy pakiety są wysyłane i odbierane.
-
Tabele routingu:Upewnij się, że węzły wiedzą, jak kierować ruchem do siebie.
-
Ustawienia MTU:Niezgodności ustawień MTU mogą powodować fragmentację pakietów i ich utratę.
2. DNS i odkrywanie usług
Wiele nowoczesnych architektur opiera się na mechanizmach odkrywania usług zamiast stałe adresy IP. Jeśli usługa odkrywania jest niedostępna, węzły nie mogą się wzajemnie znaleźć.
-
Weryfikacja rekordów:Upewnij się, że rekordy DNS wskazują na poprawne adresy IP.
-
Problemy z pamięcią podręczną:Buforowanie DNS może prowadzić do przestarzałych danych. Wyczyść pamięć podręczną DNS, jeśli to konieczne.
-
Wewnętrzne vs Zewnętrzne:Rozróżnij nazwy wewnętrznych usług i zewnętrznych nazw domen.
Głęboka analiza: Zarządzanie konfiguracją ⚙️
Zarządzanie konfiguracją zapewnia, że wszystkie węzły w architekturze znajdują się w znanym stanie. Gdy ten proces zawiedzie, wdrożenie staje się niestabilne.
1. Infrastruktura jako kod
Definiowanie infrastruktury za pomocą kodu pozwala na kontrolę wersji i powtarzalność. Jednak błędy składniowe lub błędy logiczne w kodzie mogą powodować awarie wdrożenia.
-
Weryfikacja:Uruchom sprawdzanie składni przed zastosowaniem zmian.
-
Pliki stanu:Upewnij się, że plik stanu dokładnie odzwierciedla aktualną infrastrukturę.
-
Wykrywanie odchyleń:Zaimplementuj narzędzia do wykrywania zmian ręcznych.
2. Zarządzanie tajemnicami
Dane poufne, takie jak hasła i klucze API, muszą być przechowywane w sposób bezpieczny. Nieodpowiednie zarządzanie może prowadzić do naruszeń bezpieczeństwa lub awarii wdrożenia.
-
Szyfrowanie:Upewnij się, że tajemnice są szyfrowane w spoczynku i w trakcie przesyłania.
-
Obroty: Regularnie zmieniaj poświadczenia, aby zmniejszyć ryzyko.
-
Kontrola dostępu: Ogranicz dostęp do tajemnic tylko do niezbędnych usług.
Zaawansowana analiza: Zarządzanie zasobami 💾
Ograniczenia zasobów często pojawiają się w okresach największego obciążenia. Planowanie pojemności jest kluczowe, aby zapobiec awariom.
1. Strategie skalowania
Architektury powinny być projektowane tak, aby mogły skalować się poziomo lub pionowo w zależności od zapotrzebowania. Jeśli skalowanie nie powiedzie się, system może stać się nieodpowiedni.
-
Skalowanie poziome: Dodaj więcej wystąpień, aby obsłużyć wzrost obciążenia.
-
Skalowanie pionowe: Zwiększ zasoby istniejących wystąpień.
-
Automatyczne skalowanie: Skonfiguruj zasady, aby automatycznie dostosować zasoby na podstawie metryk.
2. Monitorowanie i ostrzegania
Proaktywne monitorowanie pomaga wykryć problemy z zasobami przed ich powodowaniem awarii.
-
Próg: Ustaw ostrzeżenia dla zużycia CPU, pamięci i dysku.
-
Dzienniki: Zbierz dzienniki ze wszystkich węzłów do centralnej analizy.
-
Śledzenie: Użyj rozproszonego śledzenia, aby śledzić żądania między usługami.
Zaawansowana analiza: Bezpieczeństwo i uprawnienia 🔒
Bezpieczeństwo nie jest myślą wtórną; musi być zintegrowane z procesem wdrażania.
1. Najmniejsze uprawnienia
Usługi powinny mieć tylko uprawnienia niezbędne do działania. Nadmiernie uprawnione usługi zwiększają powierzchnię ataku.
-
Role: Zdefiniuj konkretne role dla różnych usług.
-
Polityki: Zastosuj polityki ograniczające dostęp do określonych zasobów.
-
Audyt: Regularnie audytuj uprawnienia w celu zapewnienia zgodności.
2. Bezpieczeństwo sieci
Segmentacja sieci ogranicza zakres potencjalnej ujawnienia.
-
VLANy: Oddziel ruch według funkcji lub środowiska.
-
Branżowe zapory ogniowe: Blokuj nieautoryzowany ruch na krawędzi sieci.
-
Szyfrowanie: Szyfruj wszystkie dane przesyłane między węzłami.
Integralność potoku i automatyzacji 🔄
Potok przemieszczający kod z środowiska deweloperskiego do produkcyjnego jest kluczowym elementem architektury wdrażania. Jeśli potok zawiedzie, żaden kod nie dotrze do środowiska.
1. Etapy potoku
Podziel potok na odrębne etapy w celu izolacji awarii.
-
Kompilacja: Kompiluj kod i twórz artefakty.
-
Test: Uruchamiaj testy automatyczne w celu weryfikacji funkcjonalności.
-
Wdrażanie: Przesyłaj artefakty do środowiska docelowego.
-
Weryfikacja: Wykonuj kontrole po wdrożeniu.
2. Procedury cofnięcia wdrożenia
Gdy wdrożenie zawiedzie, szybkie cofnięcie minimalizuje czas przestoju.
-
Wersjonowanie: Zachowaj poprzednie wersje artefaktów dostępne.
-
Automatyzacja: Automatyzuj proces cofnięcia wdrożenia w celu zmniejszenia błędów ludzkich.
-
Testowanie: Regularnie testuj procedury cofnięcia wdrożenia, aby upewnić się, że działają.
Obserwowanie i dzienniki 🔍
Obserwowanie zapewnia wgląd w wewnętrzny stan systemu. Bez niego diagnozowanie problemów to zgadywanie.
1. Zespołowe logowanie
Zbieraj dzienniki ze wszystkich węzłów w jednym miejscu, aby ułatwić analizę.
-
Agregacja: Użyj agregatora dzienników do zbierania danych.
-
Indeksowanie: Indeksuj dzienniki, aby szybko je przeszukiwać.
-
Zachowanie: Zdefiniuj zasady zachowania, aby zarządzać przechowywaniem danych.
2. Metryki i pulpitów
Wizualizuj kluczowe wskaźniki wydajności, aby szybko wykrywać odchylenia.
-
Kluczowe metryki: Śledź tempo żądań, tempo błędów oraz opóźnienia.
-
Powiadomienia: Skonfiguruj powiadomienia dla progów metryk.
-
Wizualizacja: Użyj pulpitu do wyświetlania danych w czasie.
Reakcja na incydenty i odbudowa 🚨
Nawet przy najlepszym planowaniu incydenty będą się zdarzać. Posiadanie planu reakcji zapewnia szybką odbudowę.
1. Klasyfikacja incydentów
Kategoryzuj incydenty w zależności od powagi i skutków.
-
Krytyczny: System jest niedostępny lub dane zostały naruszone.
-
Wysoki:Znaczne pogorszenie jakości usługi.
-
Średni:Małe problemy wpływające na część użytkowników.
-
Niski:Estetyczne lub niepilne problemy.
2. Komunikacja
Dawaj znanie wszystkim zaangażowanym w trakcie incydentu.
-
Aktualizacje stanu: Daj regularne aktualizacje postępów.
-
Analiza po incydencie: Przeanalizuj incydent po jego rozwiązaniu.
-
Zadania do wykonania: Przypisz zadania w celu zapobiegania ponownemu wystąpieniu.
Dokumentacja i kontrola wersji 📝
Dokumentacja zapewnia, że wiedza jest zachowywana i udostępniana. Kontrola wersji zapewnia śledzenie zmian.
1. Dokumentacja architektury
Utrzymuj diagram wdrożenia w aktualnym stanie.
-
Zmiany: Dokumentuj każdą zmianę architektury.
-
Zależności: Wymień wszystkie zależności zewnętrzne i wewnętrzne.
-
Procedury: Dokumentuj standardowe procedury operacyjne.
2. Zarządzanie zmianami
Kontroluj sposób wprowadzania zmian w środowisku.
-
Recenzja: Wymagaj recenzji dla istotnych zmian.
-
Zatwierdzenie: Uzyskaj zgodę przed wprowadzeniem zmian.
-
Śledzenie: Śledź wszystkie zmiany w systemie.
Ostateczne rozważania dotyczące zdrowia wdrożenia 🏥
Utrzymanie zdrowej architektury wdrożenia wymaga ciągłych starań. Regularne przeglądy i aktualizacje są niezbędne, aby nadążyć za zmieniającymi się wymaganiami. Skup się na poniższych obszarach, aby zapewnić stabilność na dłuższą metę.
-
Regularne audyty: Przeprowadzaj okresowe audyty architektury.
-
Planowanie pojemności: Zaprojektuj przyszły wzrost.
-
Szczegółowe szkolenie: Szkolenie zespołu w zakresie metodologii rozwiązywania problemów.
-
Automatyzacja: Automatyzuj powtarzające się zadania, aby zmniejszyć błędy ludzkie.
-
Testowanie: Testuj architekturę regularnie w środowisku testowym.
Śledząc strukturalny podejście do rozwiązywania problemów, zespoły mogą szybciej rozwiązywać problemy i zmniejszać czas przestoju. Celem nie jest tylko naprawa problemów, ale budowanie systemu odpornego i łatwego do utrzymania. Diagramy wdrożeń to żywe dokumenty, które powinny ewoluować wraz z infrastrukturą. Gdy się to dzieje, architektura pozostaje zgodna z potrzebami biznesowymi.
Pamiętaj, że każdy niepowodzenie to okazja do nauki. Dokumentowanie przyczyny głównej i rozwiązania pomaga zapobiegać podobnym problemom w przyszłości. Ta baza wiedzy staje się cennym aktywem dla całej organizacji.

