












A entrega moderna de software muitas vezes depende de sistemas intrincados projetados para mover código de ambientes de desenvolvimento para produção. Quando esses sistemas falham, o impacto pode ser significativo. Um diagrama de implantação serve como um projeto para essas infraestruturas, mapeando nós, artefatos e suas interações. No entanto, um diagrama só é tão útil quanto sua alinhamento com o ambiente em execução. Quando surgem discrepâncias, a solução sistemática de problemas torna-se essencial. Este guia explora como diagnosticar e resolver problemas em arquiteturas de implantação complexas sem depender de ferramentas ou produtos específicos de fornecedores.
Compreendendo o Diagrama de Implantação 📐
Antes de tentar corrigir um problema, é necessário entender o que a arquitetura representa. Um diagrama de implantação ilustra a estrutura física ou lógica do sistema. Detalha onde os componentes de software residem e como se comunicam. Em configurações complexas, isso envolve frequentemente múltiplas camadas de abstração.
-
Nós: Eles representam os recursos computacionais onde os artefatos são implantados. Podem ser máquinas físicas, instâncias virtuais ou contêineres.
-
Artefatos: São os pacotes de software sendo instalados nos nós. Incluem binários, arquivos de configuração e bibliotecas.
-
Conexões: Elas definem os caminhos de comunicação entre os nós. Especificam protocolos, portas e tipos de dados.
-
Dependências: Elas mostram os pré-requisitos necessários para que um nó funcione corretamente.
Quando ocorre um problema, o primeiro passo é comparar o diagrama com o estado atual da infraestrutura. Discrepâncias aqui são frequentemente a causa raiz das falhas.
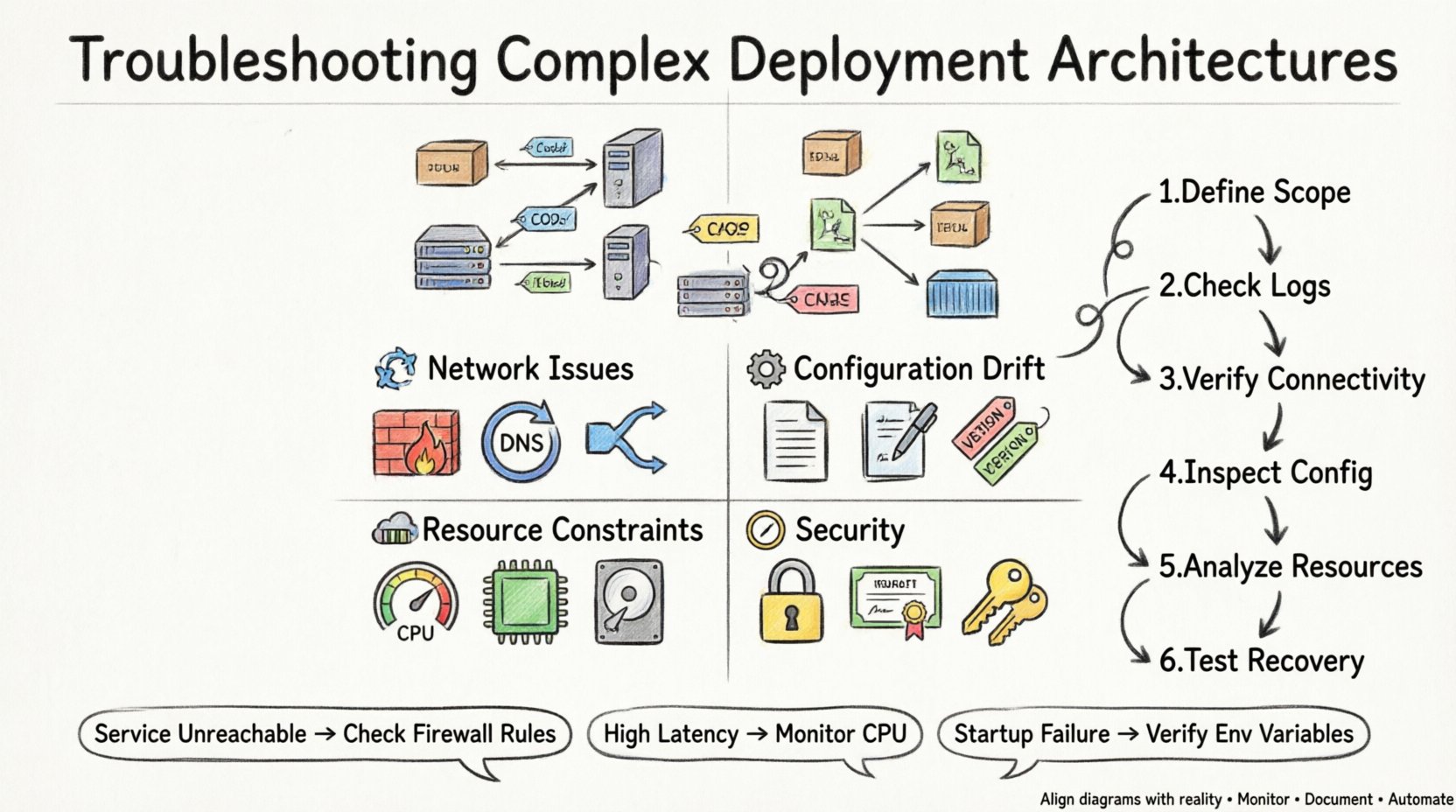
Modos Comuns de Falha ⚠️
Arquiteturas complexas introduzem múltiplos pontos de falha. Compreender os modos comuns de falha ajuda a reduzir rapidamente a investigação. Problemas geralmente se encaixam em categorias relacionadas à conectividade, configuração, recursos ou segurança.
1. Problemas de Conectividade e Redes 🌐
Problemas de rede são entre as causas mais frequentes de falha na implantação. Mesmo que o diagrama mostre uma conexão válida, a rede pode bloquear o tráfego.
-
Regras de Firewall: As portas necessárias para a comunicação podem estar fechadas por firewalls intermediários ou grupos de segurança.
-
Resolução de DNS: Serviços muitas vezes dependem de nomes de domínio. Se o DNS não estiver configurado corretamente, os nós não conseguem localizar uns aos outros.
-
Configuração de Subrede: Nós em segmentos de rede diferentes podem não ter as tabelas de roteamento necessárias para se comunicar.
-
Balanceadores de Carga: A lógica de distribuição de tráfego pode estar mal configurada, enviando solicitações para nós não saudáveis.
2. Desvio de Configuração ⚙️
O desvio de configuração ocorre quando o estado real de um nó diverge do estado pretendido definido no plano de implantação. Isso acontece frequentemente quando alterações manuais são feitas diretamente em um ambiente de produção.
-
Variáveis de Ambiente:Variáveis ausentes ou incorretas podem causar falhas no início dos serviços ou comportamentos inesperados.
-
Permissões de Arquivo:Permissões incorretas em arquivos de configuração podem impedir que o aplicativo leia dados necessários.
-
Incompatibilidades de versão:Bibliotecas ou dependências instaladas no nó podem não corresponder à versão especificada no artefato.
3. Restrições de recursos 💾
Mesmo uma arquitetura perfeitamente configurada falhará se o hardware subjacente não puder suportar a carga. A exaustão de recursos é um assassino silencioso da confiabilidade da implantação.
-
Saturação da CPU:Alta utilização pode levar a latência ou tempo limite de serviço.
-
Vazamentos de memória:Aplicações que não liberam memória corretamente podem fazer com que o host esgote a RAM.
-
Espaço em disco:Logs e arquivos temporários podem preencher o armazenamento, impedindo que novos dados sejam gravados.
-
Largura de banda de rede:Throughput insuficiente pode causar falhas na transferência de dados entre nós.
4. Segurança e permissões 🔒
Protocolos de segurança são críticos para proteger dados, mas também podem bloquear tráfego legítimo se configurados de forma excessivamente restritiva.
-
Gestão de identidade e acesso:Contas de serviço podem não ter as permissões necessárias para acessar outros recursos.
-
Validação de certificados:Certificados SSL/TLS expirados ou autoassinados podem interromper conexões criptografadas.
-
Tokens de autenticação:Tokens expirados ou inválidos podem impedir que serviços se autentiquem mutuamente.
Metodologia de diagnóstico 🔍
Ao solucionar problemas, uma abordagem estruturada evita perda de tempo. Siga estas etapas para isolar o problema de forma eficiente.
-
Defina o escopo: Determine exatamente qual parte da arquitetura está falhando. É todo o sistema, um nó específico ou uma conexão específica?
-
Verifique os logs: Revise os logs do aplicativo e do sistema em busca de mensagens de erro. Procure horários que coincidam com o evento de falha.
-
Verifique a conectividade: Use ferramentas de rede para testar a acessibilidade entre nós. Verifique se as portas estão abertas e respondendo.
-
Inspeção da configuração:Compare a configuração atual com a baseline definida no diagrama de implantação.
-
Analise o uso de recursos:Monitore o uso de CPU, memória e disco durante a janela de falha.
-
Teste de Recuperação:Tente reiniciar os serviços ou reverter as alterações para ver se o problema é resolvido.
Tabela: Sintomas Comuns vs. Ações de Diagnóstico 📋
Esta tabela resume sintomas frequentes e as ações correspondentes necessárias para diagnosticá-los.
|
Sintoma |
Causa Potencial |
Ação de Diagnóstico |
|---|---|---|
|
Serviço Inacessível |
Firewall de Rede |
Verifique Grupos de Segurança e Regras de Firewall |
|
Latência Alta |
Saturação da CPU |
Monitore Métricas de Utilização da CPU |
|
Falha na Inicialização |
Configuração Ausente |
Verifique Variáveis de Ambiente e Arquivos |
|
Conexão Reiniciada |
Exaustão de Recursos |
Verifique o Uso de Memória e Espaço em Disco |
|
Erro de Autenticação |
Expiração do Certificado |
Verifique a Validez do Certificado SSL/TLS |
|
Pipeline Preso |
Tempo Limite de Dependência |
Revise a Conectividade de Rede com Repositórios Externos |
Aprofundamento: Diagnóstico de Rede 🌐
Problemas de rede são particularmente complicados porque muitas vezes parecem intermitentes. Quando um diagrama de implantação mostra uma conexão entre o Nó A e o Nó B, mas o tráfego não está fluindo, você deve investigar o caminho.
1. Rastreando o Caminho
Use ferramentas de rastreamento de rede para identificar onde os pacotes são perdidos. Isso ajuda a determinar se o problema está dentro da rede local, pela internet ou no nó de destino.
-
Captura de Pacotes: Analise o tráfego na origem e no destino para verificar se os pacotes são enviados e recebidos.
-
Tabelas de Roteamento: Verifique se os nós sabem como rotear o tráfego entre si.
-
Configurações de MTU: Diferenças nas configurações de Unidade Máxima de Transmissão podem causar fragmentação e perda de pacotes.
2. DNS e Descoberta de Serviços
Muitas arquiteturas modernas dependem de mecanismos de descoberta de serviços em vez de endereços IP codificados. Se o serviço de descoberta estiver fora do ar, os nós não conseguem se encontrar.
-
Validação de Registros: Certifique-se de que os registros DNS apontam para os endereços IP corretos.
-
Problemas de Cache: O cache do DNS pode levar a dados desatualizados. Limpe os caches do DNS se necessário.
-
Interno vs Externo: Diferencie entre nomes de serviço internos e nomes de domínio externos.
Aprofundamento: Gerenciamento de Configuração ⚙️
O gerenciamento de configuração garante que todos os nós na arquitetura estejam em um estado conhecido. Quando esse processo falha, a implantação torna-se instável.
1. Infraestrutura como Código
Definir a infraestrutura usando código permite controle de versão e reprodutibilidade. No entanto, erros de sintaxe ou falhas lógicas no código podem causar falhas na implantação.
-
Validação: Execute verificações de sintaxe antes de aplicar alterações.
-
Arquivos de Estado: Certifique-se de que o arquivo de estado reflita com precisão a infraestrutura atual.
-
Detecção de Desvio: Implemente ferramentas para detectar quando alterações manuais ocorrem.
2. Gerenciamento de Segredos
Dados sensíveis, como senhas e chaves de API, devem ser armazenados com segurança. O manuseio inadequado pode levar a violações de segurança ou falhas na implantação.
-
Criptografia: Certifique-se de que os segredos estão criptografados em repouso e em trânsito.
-
Rotação:Roteie regularmente as credenciais para minimizar o risco.
-
Controle de Acesso:Restrinja o acesso a segredos apenas aos serviços necessários.
Aprofundamento: Gerenciamento de Recursos 💾
Restrições de recursos muitas vezes se manifestam durante os períodos de maior uso. Planejar a capacidade é essencial para evitar falhas.
1. Estratégias de Escalonamento
Arquiteturas devem ser projetadas para escalar horizontal ou verticalmente com base na demanda. Se o escalonamento falhar, o sistema pode tornar-se inativo.
-
Escalonamento Horizontal:Adicione mais instâncias para lidar com a carga aumentada.
-
Escalonamento Vertical:Aumente os recursos das instâncias existentes.
-
Escalonamento Automático:Configure regras para ajustar automaticamente os recursos com base em métricas.
2. Monitoramento e Alertas
O monitoramento proativo ajuda a identificar problemas de recursos antes que causem falhas.
-
Limites:Defina alertas para uso de CPU, memória e disco.
-
Logs:Agregue logs de todos os nós para análise centralizada.
-
Rastreamento:Use o rastreamento distribuído para rastrear solicitações entre serviços.
Aprofundamento: Segurança e Permissões 🔒
Segurança não é uma consideração posterior; deve ser integrada ao processo de implantação.
1. Menor Privilégio
Serviços devem ter apenas as permissões necessárias para funcionar. Serviços com permissões excessivas aumentam a superfície de ataque.
-
Funções:Defina funções específicas para diferentes serviços.
-
Políticas:Aplicar políticas que restringem o acesso a recursos específicos.
-
Auditoria:Audite regularmente permissões para garantir conformidade.
2. Segurança de Rede
A segmentação de rede limita o raio de impacto de uma possível violação.
-
VLANs:Separe o tráfego por função ou ambiente.
-
Firewalls:Bloqueie tráfego não autorizado na borda da rede.
-
Criptografia:Criptografe todos os dados em trânsito entre os nós.
Integridade da Pipeline e da Automação 🔄
A pipeline que move código do desenvolvimento para produção é um componente crítico da arquitetura de implantação. Se a pipeline falhar, nenhum código chegará ao ambiente.
1. Etapas da Pipeline
Divida a pipeline em etapas distintas para isolar falhas.
-
Build:Compile o código e crie artefatos.
-
Teste:Execute testes automatizados para verificar a funcionalidade.
-
Implantação:Envie os artefatos para o ambiente de destino.
-
Verifique:Realize verificações pós-implantação.
2. Procedimentos de Retorno
Quando uma implantação falha, um retorno rápido minimiza o tempo de inatividade.
-
Versionamento:Mantenha versões anteriores dos artefatos disponíveis.
-
Automação:Automatize o processo de retorno para reduzir erros humanos.
-
Testes:Teste regularmente os procedimentos de retorno para garantir que funcionem.
Observabilidade e Logs 🔍
A observabilidade fornece visão sobre o estado interno do sistema. Sem ela, o diagnóstico de problemas é apenas adivinhação.
1. Registro Centralizado
Colete logs de todos os nós em um local central para uma análise mais fácil.
-
Agregação:Use um agregador de logs para coletar dados.
-
Indexação:Indexe os logs para busca rápida.
-
Retenção:Defina políticas de retenção para gerenciar o armazenamento.
2. Métricas e Painéis
Visualize indicadores-chave de desempenho para identificar anomalias rapidamente.
-
Métricas-Chave:Monitore as taxas de solicitação, taxas de erro e latência.
-
Alertas:Configure alertas para os limites das métricas.
-
Visualização:Use painéis para exibir dados ao longo do tempo.
Resposta a Incidentes e Recuperação 🚨
Mesmo com o melhor planejamento, incidentes ocorrerão. Ter um plano de resposta garante uma recuperação rápida.
1. Classificação de Incidentes
Classifique incidentes com base na gravidade e no impacto.
-
Crítico:O sistema está fora do ar ou os dados foram comprometidos.
-
Alto:Degradção significativa do serviço.
-
Médio:Problemas menores que afetam um subconjunto de usuários.
-
Baixo:Problemas estéticos ou não urgentes.
2. Comunicação
Mantenha os interessados informados durante todo o incidente.
-
Atualizações de Status:Forneça atualizações regulares sobre o progresso.
-
Pós-Mortem:Analise o incidente após a resolução.
-
Itens de Ação:Atribua tarefas para prevenir recorrência.
Documentação e Controle de Versão 📝
A documentação garante que o conhecimento seja retido e compartilhado. O controle de versão garante que as alterações sejam rastreadas.
1. Documentação da Arquitetura
Mantenha o diagrama de implantação atualizado.
-
Alterações:Documente cada alteração na arquitetura.
-
Dependências:Liste todas as dependências externas e internas.
-
Procedimentos:Documente os procedimentos operacionais padrão.
2. Gestão de Mudanças
Controle como as alterações são feitas no ambiente.
-
Revisão:Requer revisões para mudanças significativas.
-
Aprovação:Obtenha aprovação antes de aplicar alterações.
-
Rastreamento:Rastreie todas as alterações em um sistema.
Considerações Finais para a Saúde da Implantação 🏥
Manter uma arquitetura de implantação saudável exige esforço contínuo. Revisões e atualizações regulares são necessárias para acompanhar as mudanças nas exigências. Foque nas seguintes áreas para garantir estabilidade de longo prazo.
-
Auditorias Regulares:Realize auditorias periódicas da arquitetura.
-
Planejamento de Capacidade: Planeje o crescimento futuro.
-
Treinamento: Treine a equipe sobre metodologias de solução de problemas.
-
Automação: Automatize tarefas repetitivas para reduzir erros humanos.
-
Testes: Teste a arquitetura regularmente em um ambiente de homologação.
Ao seguir uma abordagem estruturada para solução de problemas, as equipes conseguem resolver questões mais rapidamente e reduzir o tempo de inatividade. O objetivo não é apenas corrigir problemas, mas construir um sistema resiliente e fácil de manter. Os diagramas de implantação são documentos vivos que devem evoluir junto com a infraestrutura. Quando isso acontece, a arquitetura permanece alinhada às necessidades do negócio.
Lembre-se de que cada falha é uma oportunidade de aprendizado. Documentar a causa raiz e a solução ajuda a prevenir problemas semelhantes no futuro. Essa base de conhecimento torna-se um ativo valioso para toda a organização.

