












現代のソフトウェア配信は、開発環境から本番環境へコードを移動するように設計された複雑なシステムに依存することが多い。これらのシステムが障害を起こすと、影響は重大になることがある。デプロイ図は、こうしたインフラの設計図として機能し、ノード、アーティファクト、およびそれらの相互作用を可視化する。しかし、図の価値は、実際の稼働環境との整合性に依存する。整合性のズレが生じた場合、体系的なトラブルシューティングが不可欠になる。このガイドでは、特定のベンダー製ツールや製品に依存せずに、複雑なデプロイアーキテクチャ内の問題を診断・解決する方法を検討する。
デプロイ図の理解 📐
問題を修正しようとする前に、アーキテクチャが何を表しているかを理解する必要がある。デプロイ図は、システムの物理的または論理的な構造を示す。ソフトウェアコンポーネントがどこに配置されているか、どのように通信しているかを詳細に記述する。複雑な構成では、しばしば複数の抽象化レイヤーが関与する。
-
ノード: これらは、アーティファクトがデプロイされる計算リソースを表す。物理マシン、仮想インスタンス、またはコンテナである。
-
アーティファクト: これらは、ノードにインストールされるソフトウェアパッケージを指す。バイナリ、設定ファイル、ライブラリを含む。
-
接続: これらはノード間の通信経路を定義する。プロトコル、ポート、データ型を指定する。
-
依存関係: これらは、ノードが正しく動作するために必要な事前条件を示す。
問題が発生した際の最初のステップは、図をインフラの現在の状態と比較することである。ここでの不一致は、障害の根本原因であることが多い。
一般的な障害モード ⚠️
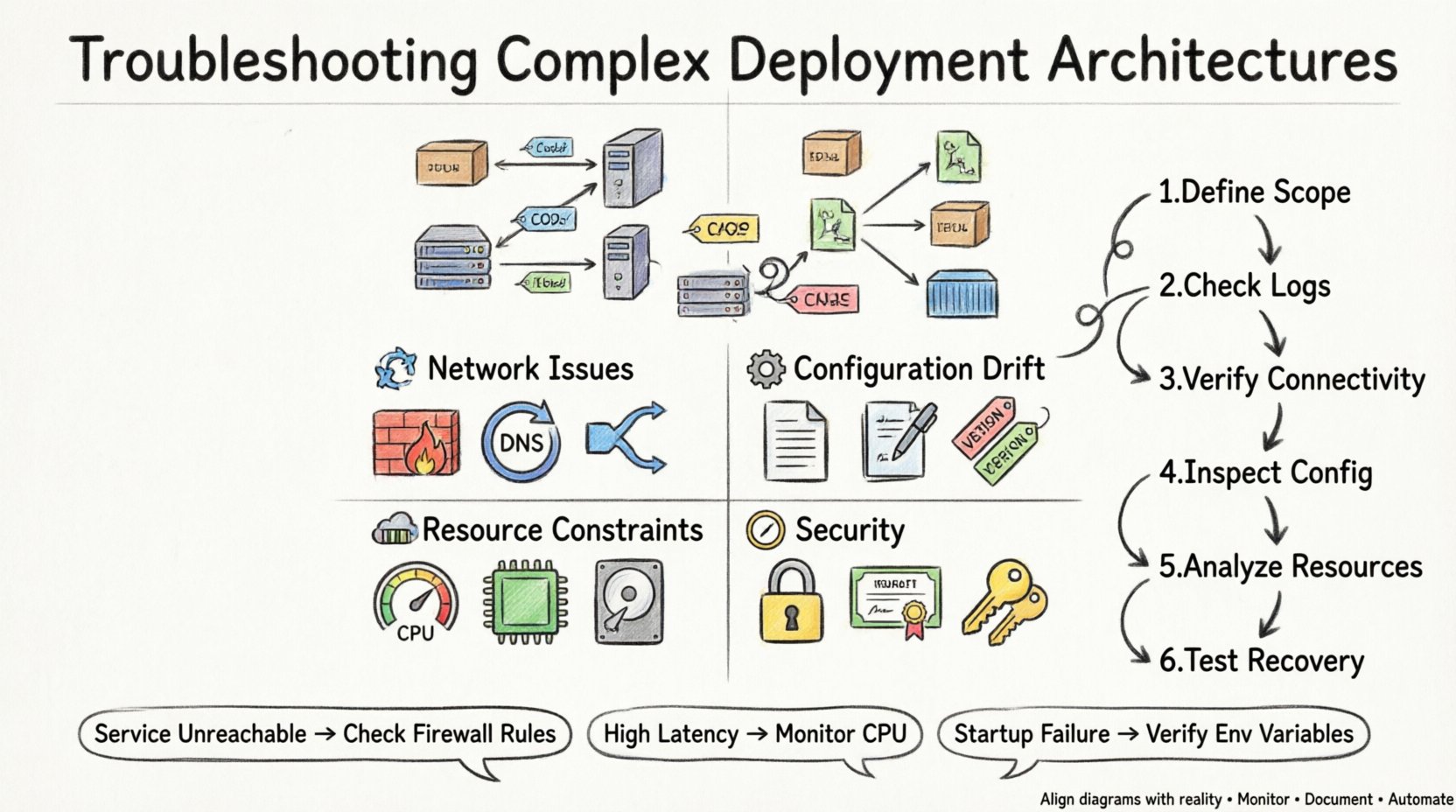
複雑なアーキテクチャは、複数の障害ポイントをもたらす。一般的な障害モードを理解することで、調査を迅速に絞り込める。問題は、接続性、構成、リソース、セキュリティに関連するカテゴリに大別される。
1. 接続性およびネットワーク問題 🌐
ネットワーク問題は、デプロイ障害の最も一般的な原因の一つである。図に有効な接続が示されている場合でも、ネットワークがトラフィックをブロックしている可能性がある。
-
ファイアウォールルール: 通信に必要なポートが、中間のファイアウォールやセキュリティグループによって閉じられている可能性がある。
-
DNS解決: サービスはしばしばドメイン名に依存する。DNSが正しく設定されていないと、ノード同士がお互いを見つけることができない。
-
サブネット構成: 異なるネットワークセグメントにあるノードは、通信に必要なルーティングテーブルを持っていない可能性がある。
-
ロードバランサー: トラフィック分散ロジックが誤って設定されている可能性があり、リクエストが健全でないノードに送信される。
2. 構成のずれ ⚙️
構成のずれとは、ノードの実際の状態がデプロイ計画で定義された意図された状態から逸脱した状態を指す。これは、生産環境に直接手動で変更を加えた場合に頻繁に発生する。
-
環境変数: 環境変数が欠落している、または誤った値が設定されていると、サービスが起動しなかったり、予期しない動作をしたりする。
-
ファイル権限:設定ファイルの権限が正しくない場合、アプリケーションが必要なデータを読み取れなくなることがあります。
-
バージョンの不一致:ノードにインストールされたライブラリや依存関係が、アーティファクトで指定されたバージョンと一致しない可能性があります。
3. リソース制約 💾
たとえアーキテクチャが完璧に設定されていても、基盤となるハードウェアが負荷をサポートできなければ失敗します。リソースの枯渇は、デプロイの信頼性を静かに破壊する要因です。
-
CPUの飽和:高い利用状況は、遅延やサービスのタイムアウトを引き起こすことがあります。
-
メモリリーク:適切にメモリを解放しないアプリケーションは、ホストのRAMが枯渇する原因になります。
-
ディスク容量:ログや一時ファイルがストレージを埋め尽くし、新しいデータの書き込みを妨げる可能性があります。
-
ネットワーク帯域幅:十分なスループットが確保できないと、ノード間のデータ転送に失敗する可能性があります。
4. セキュリティと権限 🔒
セキュリティプロトコルはデータを保護するために重要ですが、過度に厳格に設定すると正当なトラフィックもブロックする可能性があります。
-
アイデンティティアクセス管理:サービスアカウントが他のリソースにアクセスするために必要な権限を持っていない可能性があります。
-
証明書の検証:有効期限が切れているか自己署名されたSSL/TLS証明書は、暗号化された接続を破綻させる可能性があります。
-
認証トークン:有効期限が切れているか無効なトークンは、サービス同士が相互に認証できなくなる原因になります。
診断手法 🔍
トラブルシューティングを行う際は、構造的なアプローチを取ることで無駄な時間を避けられます。問題を効率的に特定するために、以下の手順に従ってください。
-
範囲を定義する:アーキテクチャのどの部分が障害しているかを正確に特定してください。全体のシステム、特定のノード、または特定の接続でしょうか?
-
ログを確認する:アプリケーションログとシステムログを確認し、エラーメッセージを探してください。障害発生時刻と一致するタイムスタンプを確認してください。
-
接続性を確認する:ネットワークツールを使用してノード間の到達可能性をテストしてください。ポートが開いているか、応答しているかを確認してください。
-
構成を確認する: デプロイ図で定義されたベースラインと現在の構成を比較する。
-
リソース使用状況の分析: 故障発生期間中にCPU、メモリ、ディスク使用状況を監視する。
-
復旧テスト: サービスの再起動や変更のロールバックを試み、問題が解消されるか確認する。
表:一般的な症状と診断アクションの比較 📋
この表は、頻発する症状とそれらを診断するために必要な対応アクションを要約している。
|
症状 |
潜在的な原因 |
診断アクション |
|---|---|---|
|
サービスに到達できない |
ネットワークファイアウォール |
セキュリティグループとファイアウォールルールを確認する |
|
高レイテンシ |
CPU飽和 |
CPU利用状況メトリクスを監視する |
|
起動失敗 |
設定の欠落 |
環境変数とファイルを確認する |
|
接続がリセットされた |
リソース枯渇 |
メモリおよびディスク容量使用状況を確認する |
|
認証エラー |
証明書の有効期限切れ |
SSL/TLS証明書の有効性を確認する |
|
パイプラインが停止している |
依存関係のタイムアウト |
外部リポジトリへのネットワーク接続を確認する |
詳細調査:ネットワーク診断 🌐
ネットワーク問題は特に厄介で、しばしば断続的に発生するように見える。デプロイ図でノードAとノードBの間に接続があるにもかかわらず、トラフィックが流れていなければ、経路を調査しなければならない。
1. ルートの追跡
パケットがどこで失われるかを特定するためにネットワークトレーシングツールを使用する。これにより、問題がローカルネットワーク内、インターネットを跨いで、または宛先ノードに存在するかを判断するのに役立つ。
-
パケットキャプチャ:送信元および宛先でのトラフィックを分析し、パケットが送信および受信されているかを確認する。
-
ルーティングテーブル:ノードが互いにトラフィックをルーティングする方法を把握していることを確認する。
-
MTU設定:最大送信単位(MTU)の不一致は、パケットのフラグメンテーションや損失を引き起こす可能性がある。
2. DNSとサービスディスカバリ
多くの現代的なアーキテクチャは、ハードコードされたIPアドレスではなく、サービスディスカバリメカニズムに依存している。ディスカバリサービスが停止している場合、ノード同士が互いを見つけることができない。
-
レコードの検証:DNSレコードが正しいIPアドレスを指していることを確認する。
-
キャッシュの問題:DNSキャッシュは古くなったデータを引き起こす可能性がある。必要に応じてDNSキャッシュをクリアする。
-
内部と外部:内部サービス名と外部ドメイン名の違いを明確にする。
詳細調査:構成管理 ⚙️
構成管理は、アーキテクチャ内のすべてのノードが既知の状態にあることを保証する。このプロセスが失敗すると、デプロイが不安定になる。
1. インフラストラクチャとしてのコード
インフラストラクチャをコードで定義することで、バージョン管理と再現性が可能になる。しかし、コード内の構文エラーや論理的な欠陥は、デプロイ失敗を引き起こす可能性がある。
-
検証:変更を適用する前に構文チェックを実行する。
-
ステートファイル:ステートファイルが現在のインフラストラクチャを正確に反映していることを確認する。
-
ずれ検出:手動での変更が発生したときに検出できるツールを導入する。
2. シークレット管理
パスワードやAPIキーなどの機密データは、安全に保管する必要がある。適切でない取り扱いは、セキュリティ侵害やデプロイ失敗を引き起こす可能性がある。
-
暗号化:シークレットが静止時および送信中において暗号化されていることを確認する。
-
ローテーション:資格情報を定期的にローテーションして、リスクを最小限に抑える。
-
アクセス制御:シークレットへのアクセスを、必要なサービスに限定する。
ディープダイブ:リソース管理 💾
リソース制約はしばしばピーク使用時に現れる。障害を防ぐために、容量計画は必須である。
1. スケーリング戦略
アーキテクチャは、需要に応じて水平方向または垂直方向にスケーリングできるように設計すべきである。スケーリングに失敗すると、システムが応答しなくなる可能性がある。
-
水平スケーリング:負荷増加に対応するため、より多くのインスタンスを追加する。
-
垂直スケーリング:既存のインスタンスのリソースを増加する。
-
自動スケーリング:メトリクスに基づいてリソースを自動的に調整するルールを設定する。
2. 監視とアラート
プロアクティブな監視は、障害が発生する前にリソースの問題を特定するのを助ける。
-
しきい値:CPU、メモリ、ディスク使用率のアラートを設定する。
-
ログ:すべてのノードからのログを集約し、中央で分析する。
-
トレーシング:分散トレーシングを使用して、サービス間をまたぐリクエストを追跡する。
ディープダイブ:セキュリティと権限 🔒
セキュリティは後から考えるものではない。デプロイプロセスに組み込む必要がある。
1. 最小権限
サービスは、機能するために必要な権限のみを持つべきである。過剰な権限を持つサービスは、攻撃面を広げる。
-
ロール:異なるサービスに特定のロールを定義する。
-
ポリシー:特定のリソースへのアクセスを制限するポリシーを適用する。
-
監査:権限を定期的に監査して、準拠を確保する。
2. ネットワークセキュリティ
ネットワークセグメンテーションは、潜在的な侵害の影響範囲を制限する。
-
VLAN:機能または環境ごとにトラフィックを分離する。
-
ファイアウォール:ネットワークエッジで不正なトラフィックをブロックする。
-
暗号化:ノード間を移動するすべてのデータを暗号化する。
パイプラインおよび自動化の整合性 🔄
開発から本番環境へコードを移動するパイプラインは、デプロイアーキテクチャの重要な構成要素である。パイプラインが失敗すると、コードは環境に到達しない。
1. パイプラインステージ
障害を隔離するために、パイプラインを明確なステージに分ける。
-
ビルド:コードをコンパイルし、アーティファクトを作成する。
-
テスト:自動テストを実行して機能を検証する。
-
デプロイ:アーティファクトを対象環境にプッシュする。
-
検証:デプロイ後のチェックを実行する。
2. ロールバック手順
デプロイが失敗した場合、迅速なロールバックによりダウンタイムを最小限に抑える。
-
バージョン管理:アーティファクトの以前のバージョンを常に利用可能にしておく。
-
自動化:ロールバックプロセスを自動化して人的ミスを減らす。
-
テスト:ロールバック手順を定期的にテストして、正常に動作することを確認する。
可観測性とログ 🔍
可観測性はシステムの内部状態に関する洞察を提供します。これがないと、問題のトラブルシューティングは当てずっぽうになります。
1. 集中型ログ記録
すべてのノードからのログを中央の場所に集約し、分析を容易にする。
-
集約:ログ集約ツールを使用してデータを収集する。
-
インデックス作成:ログをインデックス化して高速検索を可能にする。
-
保持期間:ストレージを管理するための保持ポリシーを定義する。
2. メトリクスとダッシュボード
重要なパフォーマンス指標を可視化して、異常を迅速に発見する。
-
重要なメトリクス:リクエスト頻度、エラー頻度、遅延を追跡する。
-
アラート:メトリクスのしきい値に対してアラートを設定する。
-
可視化:ダッシュボードを使用して、時間経過に伴うデータを表示する。
インシデント対応と復旧 🚨
最良の計画を立てても、インシデントは発生します。対応計画を用意することで、迅速な復旧が保証されます。
1. インシデントの分類
深刻度と影響度に基づいてインシデントを分類する。
-
深刻:システムが停止している、またはデータが損傷している。
-
高:サービスの著しい劣化。
-
中:一部のユーザーに影響を与える軽微な問題。
-
低:外観上の問題または緊急でない問題。
2. 連絡・情報共有
出来事の間中、関係者に情報を提供し続ける。
-
状況の更新:進捗状況について定期的に更新する。
-
振り返り:解決後に出来事の分析を行う。
-
対応事項:再発防止のためのタスクを割り当てる。
ドキュメント作成とバージョン管理 📝
ドキュメント作成により、知識が保持され共有される。バージョン管理により、変更が追跡される。
1. アーキテクチャのドキュメント作成
デプロイメント図を最新の状態に保つ。
-
変更:アーキテクチャのすべての変更を記録する。
-
依存関係:すべての外部および内部の依存関係をリストアップする。
-
手順:標準作業手順を文書化する。
2. 変更管理
環境への変更の仕方を制御する。
-
レビュー:重要な変更にはレビューを必須とする。
-
承認:変更を適用する前に承認を得る。
-
追跡:システム内のすべての変更を追跡する。
デプロイメントの健全性に関する最終的な考慮事項 🏥
健全なデプロイメントアーキテクチャを維持するには継続的な努力が必要である。変化する要件に対応するため、定期的なレビューと更新が不可欠である。長期的な安定性を確保するため、以下の分野に注力する。
-
定期的な監査:アーキテクチャに対して定期的な監査を行う。
-
容量計画:将来の成長に備えた計画を立てる。
-
トレーニング:チームにトラブルシューティングの手法を訓練する。
-
自動化:繰り返し作業を自動化して人的ミスを減らす。
-
テスト:ステージング環境でアーキテクチャを定期的にテストする。
トラブルシューティングに対して構造的なアプローチを取ることで、チームは問題をより迅速に解決し、ダウンタイムを削減できる。目標は単に問題を修正することではなく、耐障害性があり、保守が容易なシステムを構築することにある。デプロイメント図は、インフラ構成とともに進化すべき動的な文書である。それらが進化するとき、アーキテクチャはビジネスニーズと一致したままになる。
すべての失敗は学ぶ機会であることを忘れないでください。原因と解決策を記録することで、将来同様の問題を防ぐことができる。この知識ベースは、組織全体にとって貴重な資産となる。

