












ビジネスプロセスモデルと表記法(BPMN)の複雑な世界では、制御の流れは線形的で予測可能になるように設計されています。しかし、現実の運用はそう単純ではありません。システムは障害し、データ検証が破綻し、外部の依存関係がオフラインになります。ここがエラーイベントが重要になるのです。これらは、全体のプロセスモデルの整合性を損なうことなく、例外を管理するための標準化されたメカニズムをBPMN仕様内で提供します。
効果的な例外処理とは、すべての障害を予測することではありません。問題が発生した際の明確な対応経路を定義することです。このガイドでは、エラーイベントのメカニズム、設定、戦略的活用法を検討し、ワークフローが耐障害性を保つようにします。異なる種類のエラー発生要因の区別方法、エラーコードの適切な設定、クリーンなプロセス設計の維持についても検討します。
エラーイベントの核心的概念を理解する ⚙️
エラーイベントは、プロセスまたは環境内の障害状態によって発生する特定のイベントです。外部通信に依存するメッセージイベントや、エンジン全体にブロードキャストするシグナルイベントとは異なり、エラーイベントは特定のタスクまたはアクティビティの実行フローと密接に結びついています。
プロセスインスタンスが問題に直面したとき、エンジンは実行をどこに転送すべきかを把握する必要があります。エラーイベントはその転送の目印となります。これにより、モデルは通常の実行(ハッピーパス)と例外処理(アンハッピーパス)を分離できるようになります。
主な特徴は以下の通りです:
- 特定性: 通常、障害が発生しやすいと知られているタスクに接続されています。
- 伝播性: ローカルでキャッチされない場合、階層構造を上へと伝播することができます。
- 標準化: 互換性を確保するために、BPMN 2.0仕様に従います。
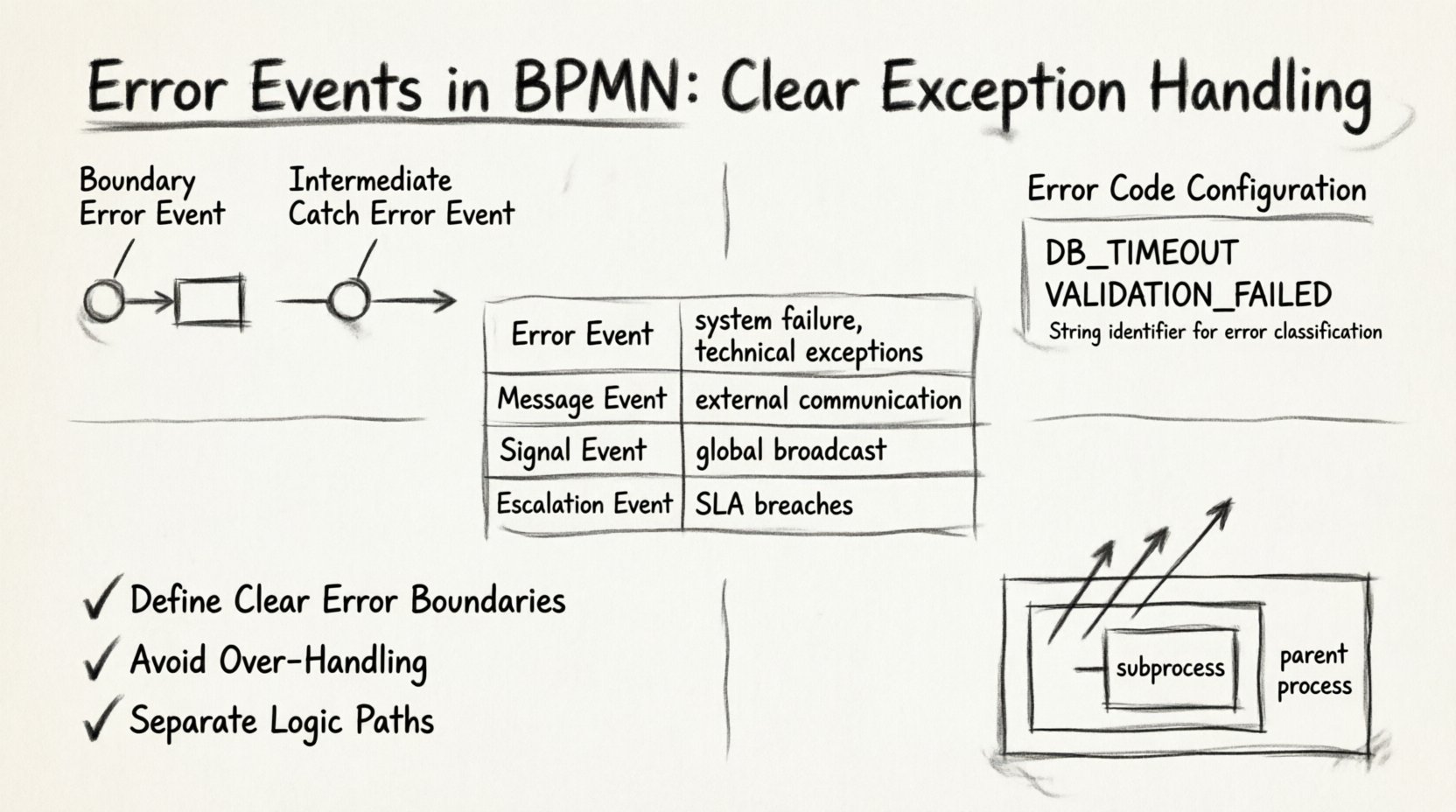
BPMNにおけるエラーイベントの種類 📋
ワークフローダイアグラムで例外処理を実装する主な方法は2つあります。適切な選択は、捕捉したい障害の粒度に依存します。
1. バウンダリー・エラーイベント 🎯
バウンダリー・エラーイベントは、タスク、サブプロセス、またはコールアクティビティの境界に直接接続されます。これはローカルな例外ハンドラを表します。タスクが実行され、エラーを送出した場合、フローはすぐにバウンダリー・イベントに接続されたパスに即座に転送されます。
これは特定の障害を処理するための最も一般的なパターンです。エラーをアクティビティのスコープ内に限定できます。たとえば、データベースへの書き込み操作が失敗した場合、バウンダリー・イベントはその特定の障害をキャッチでき、プロセスインスタンス全体を停止せずに済みます。
バウンダリー・イベントの利点:
- 封入性: 例外処理ロジックは、保護対象のタスクの近くに視覚的に配置されています。
- 非ブロッキング: メインタスクはエラーが発生するまで継続します。
- 明確性: ダイアグラムは、どのタスクにフォールバック機構があるかを明確に示しています。
2. 中間キャッチ・エラーイベント 🔄
中間キャッチ・エラーイベントは、タスクの境界に接続されるのではなく、シーケンスフロー上に配置されます。このタイプはあまり一般的ではありませんが、タスクの間に発生するエラーや、親スコープでキャッチする必要があるサブプロセス内のエラーを処理するのに役立ちます。
このアプローチは、サブプロセスから伝播してきたエラーをキャッチしたいが、まだメインプロセスの境界に到達していない場合に頻繁に使用されます。特定の論理ブロックに対する集中型のエラー管理を可能にします。
構成と属性 ⚙️
エラーイベントを機能させるには、モデリングツールおよび実行エンジン内で特定の構成が必要です。これらの構成により、エラーとは何か、システムがどのように反応するかが定義されます。
エラーコードの定義
すべてのエラーイベントには一意のエラーコードがあります。これは、1つのエラーの種類と他の種類を区別する文字列識別子です。定義されたコードがないと、エンジンはデータベースのタイムアウトと検証失敗を区別できません。
- 文字列識別子:一貫した命名規則を使用してください。たとえば
DB_TIMEOUTまたはVALIDATION_FAILED. - 粒度:一般的なコード(例:
ERROR_1)を避けてください。デバッグを支援する説明的な識別子を使用してください。 - マッピング:外部システムまたはスクリプトが、イベントで定義された正確なコードをスローすることを確認してください。
メッセージ関連付け
一部の実装では、エラーイベントを特定のメッセージ定義に関連付けることができます。これにより、エラーが人間が読めるメッセージにリンクされ、ユーザーインターフェースに表示されるか、ログに記録されるようになります。
- ユーザーへのフィードバック:システムがユーザーに、何が問題だったかを正確に伝えることを可能にします。
- ログ記録:自動ログ記録システムが、エラーの種類ごとにインシデントを分類できるように支援します。
エラー処理戦略の比較 📊
BPMNの広い文脈の中でエラーイベントがどのように位置づけられるかを理解することは不可欠です。以下のイベントタイプの比較により、エラーイベントを他の選択肢と比較して、いつ使用すべきかを明確にします。
| イベントの種類 | トリガーの発生元 | 典型的な使用例 | スコープ |
|---|---|---|---|
| エラーイベント | システム/タスクの障害 | 技術的例外、検証失敗 | ローカルまたはプロセス |
| メッセージイベント | 外部通信 | 返信待ち、データ受信中 | プロセスインスタンス |
| シグナルイベント | グローバルブロードキャスト | 複数インスタンスのキャンセル、システム全体のアラート | グローバル |
| エスカレーションイベント | プロセスルール | SLA違反、手動介入の要件 | プロセス階層 |
レジリエンスを考慮した設計:ベストプラクティス 🛡️
エラーを適切に処理できるプロセスモデルを構築するには戦略的なアプローチが必要です。図面上にイベントを配置するだけでは不十分であり、その周囲の論理が妥当でなければならない。
1. 明確なエラー境界を定義する
プロセスを終了すべきエラーをキャッチしてはならない。一部の障害は回復不能である。特定のデータがなければプロセスが進行できない場合、エラーをキャッチして無限に再試行するとゾンビプロセスになる。代わりに、エラーを上位レベルに伝搬させるか、インスタンスを明確に終了させるべきである。
- 重要なタスクを特定する:プロセスが機能するために不可欠なタスクを特定する。
- 致命的なエラーで終了する:プロセスが継続できないことを示すためにエラーイベントを使用する。
- 一時的なエラーでは再試行する:ネットワークタイムアウトや一時的な利用不可に対して境界イベントを使用する。
2. 過剰な処理を避ける
すべてのタスクにエラー処理が必要というわけではない。すべてのタスクに境界イベントを追加すると図面が複雑になり、フローの読みにくさが増す。エラーが発生する可能性がある、または発生した場合に重大な影響を及ぼすタスクにのみエラーイベントを付けるべきである。
3. ロジックパスを分離する
エラー発生後のパスが通常のパスと明確に異なることを確認する。エラー経路が最終的にメインフローと再結合する場合は、排他的ゲートウェイを使用してクリーンにマージする。エラー処理ロジックとビジネスロジックを混同してはならない。
データマッピングとプロパゲーション 📡
エラーが発生すると、明示的にマッピングされない限りデータは失われる傾向があります。エラーイベントの最も見過ごされがちな側面の一つは、変数の処理です。
エラー時のデータ永続化
例外がキャッチされると、システムは通常、障害に関する情報を保存します。これにはエラーコード、タイムスタンプ、障害発生時の変数の状態などが含まれる可能性があります。
- 変数のキャプチャ:エラー発生時にプロセス変数の状態を保存するようにエンジンを設定する。
- コンテキストの保持:エラー処理者が障害の原因となったデータにアクセスできるようにする。
エラーの上位伝播
サブプロセスがエラーをスローし、そのサブプロセスにエラーをキャッチする境界イベントがない場合、エラーは親プロセスに伝播します。これは階層的なプロセス設計において重要な機能です。
- 親プロセスの処理: 親プロセスは、子プロセスの障害に対してどのように反応するかを決定できます。
- グローバルな回復:関連するタスク群に対して、集中型の回復戦略を可能にする。
人間タスクのエラー処理 👤
プロセスモデルはしばしば人間の参加者を含みます。人間タスクが失敗した場合、エラーイベントはシステムタスクの場合とわずかに異なる挙動を示します。
- タスクの放棄: ユーザーがタスクを放棄すると、エラーイベントが発生する可能性があります。
- タイムアウト: タスクが設定された時間内に完了しない場合、エスカレーションまたはエラーが発生する可能性があります。
- 再割当: もし元の担当者が失敗した場合、エラーイベントによってタスクが別のユーザーまたはキューにルーティングされることがあります。
人間タスクを想定した設計では、エラー経路はしばしば通知メカニズムを含みます。これはメールアラートや監督者へのダッシュボード通知などです。
テストと検証 🔍
モデルが構築された後は、エラー経路が意図した通りに機能することを確認するためにテストが必要です。静的解析だけでは不十分です。
シミュレーションシナリオ
意図的にエラーを発生させるプロセスシミュレーションを実行する。以下の点を確認する:
- 境界イベントが正しくアクティブ化される。
- プロセスが例外フローに従う。
- データが適切に保持されたりログに記録されたりする。
- プロセスは無限の再試行ループに入ることはありません。
コードカバレッジ
エラー処理ロジックが想定される障害シナリオの範囲をカバーしていることを確認してください。これには以下が含まれます:
- ネットワーク接続の問題。
- 無効なデータ入力。
- 外部APIの利用不可。
避けるべき一般的な落とし穴 ⚠️
経験豊富なモデラーでさえ、エラーイベントを実装する際にミスを犯すことがあります。一般的な問題への意識を持つことで、堅牢なモデルを維持できます。
- エラーコードの欠落:エンジン設定でエラーコードを定義しないと、静黙的な失敗が発生します。
- 到達不可能なパス:論理的な制約により、決して到達できないエラーパスを作成すること。
- ログの無視:エラーをキャッチして何もしないこと。エラーは常にログ記録または通知をトリガーすべきです。
- 複雑なマージ:エラーの原因を区別せずに、あまりにも多くのエラーパスを1つのゲートウェイにマージすること。
例外設計に関する結論 🎓
エラーイベントの設計には、技術的な正確さと運用上の現実主義のバランスが必要です。特定のイベントタイプを理解し、適切に設定し、確立されたベストプラクティスに従うことで、障害に対して堅牢なプロセスを構築できます。
目標は、不可能なエラーの完全な排除ではなく、効率的に管理することです。明確な例外処理を備えた適切に構造化されたBPMNモデルは、ダウンタイムを削減し、障害の可視性を向上させ、ビジネス運用が迅速に回復できることを保証します。タスクの具体的なニーズに注目し、明確なコードを定義し、障害パスを徹底的にテストしてください。このアプローチにより、現実世界の複雑さに耐えうる信頼性の高いワークフローが実現します。

