












ソフトウェアシステムの物理アーキテクチャを理解することは、成功裏な導入と保守にとって不可欠です。デプロイメント図は、ハードウェアおよびソフトウェアインフラの高レベルな視点を提供し、コンポーネントが物理ノードにどのようにマッピングされているかを示します。これらの可視化は単なる図面ではなく、システムの安定性、スケーラビリティ、セキュリティのための設計図です。
このガイドでは、デプロイメント図で最も頻繁に見られるパターンを検討します。これらの構造を認識することで、アーキテクトや開発者はシステム要件をより効果的に伝えることができ、インフラの課題を発生する前に予測できます。各要素、パターン、および実用的な考慮事項について検討します。
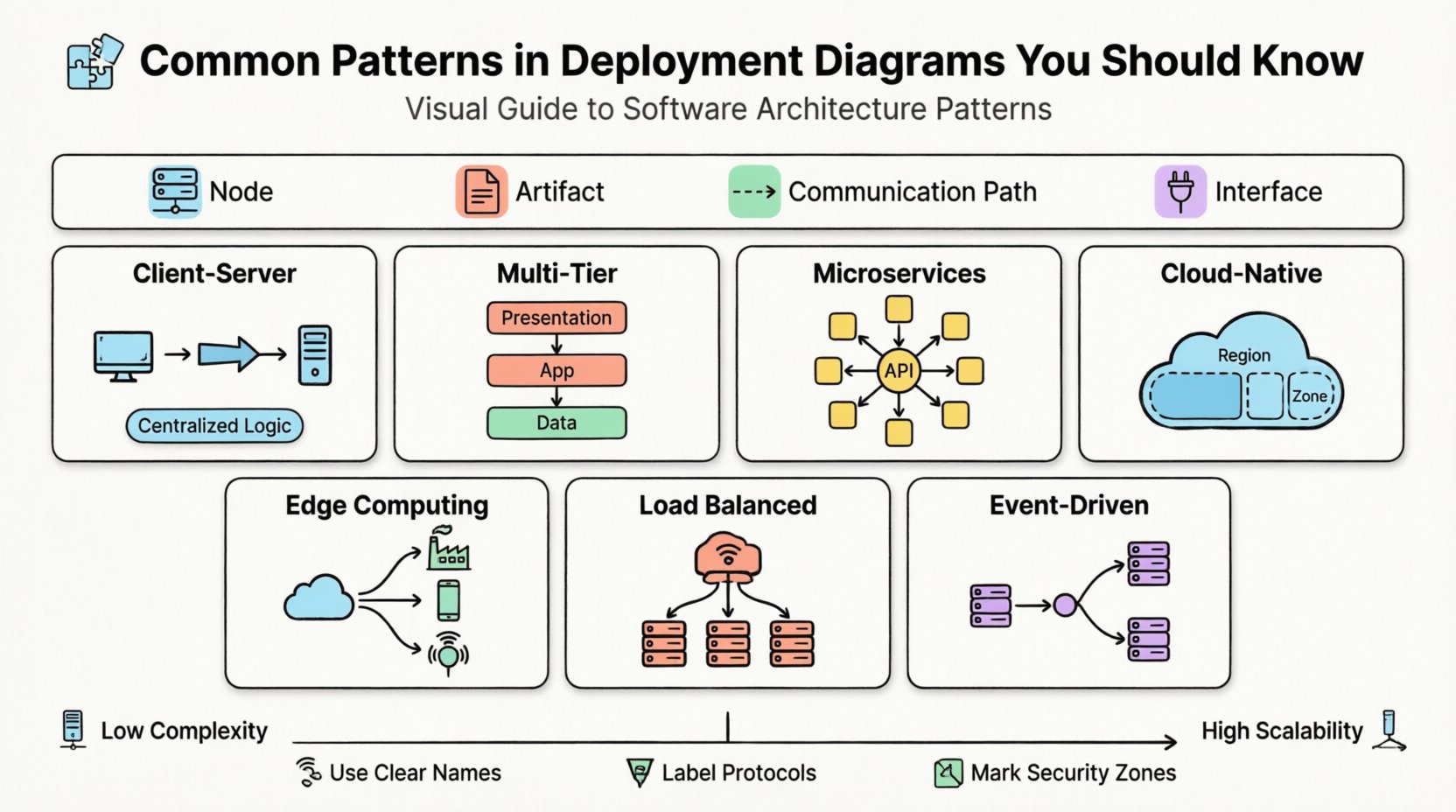
デプロイメント図の核心となる要素 🧩
特定のパターンに深入りする前に、これらの図を構築するために使用される基本構成要素を理解することが必要です。標準的なデプロイメントビューはいくつかの重要な概念に依存しています:
- ノード:物理的または仮想的なコンピューティングデバイスです。サーバー、モバイルデバイス、IoTセンサー、コンテナインスタンスなどが含まれます。ノードは実行環境を表します。
- アーティファクト:ノードにデプロイされる物理的な情報またはコードです。実行可能ファイル、データベーススキーマ、構成ファイル、ライブラリなどが例です。
- 通信経路:ノード間の接続です。データがどのように移動するかを定義し、通常はLAN、WAN、またはインターネットなどのネットワークを表します。
- インターフェース:ノードが他のノードやアーティファクトに機能を公開するための相互作用のポイントです。
図を作成する際の目的は、アーティファクトがどこに配置されているか、そしてどのように相互作用しているかを示すことです。詳細度は対象となる audience によって異なります。高レベルのビューではクラウドとデータベースだけを示すこともありますが、詳細なビューでは個々のアプリケーションサーバーやロードバランサーを示すこともあります。
1. クライアント・サーバーパターン 🖥️
クライアント・サーバーモデルは、ほとんどの従来型コンピューティングシステムの基盤です。ユーザーインターフェースとリクエストロジック(クライアント)を、データ処理とストレージロジック(サーバー)から分離します。
図の構造
- クライアントノード:ユーザーのデバイスを表します。デスクトップコンピュータ、タブレット、またはモバイルフォンが含まれます。ユーザーインターフェースのアーティファクトをホストします。
- サーバーノード:リクエストを処理する専用のマシンまたはクラスタです。アプリケーションロジックをホストし、ストレージに接続します。
- 接続:通常は「HTTP」または「TCP/IP」とラベル付けされたネットワークリンクです。
主な特徴
- 集中型ロジック: ビジネスルールはサーバー上に存在します。
- ステートレスなクライアント: クライアントは通常、重要なデータを永続的に保存しません。
- スケーラビリティ: スケーリングは、クライアントのアップグレードよりも、ロードバランサーの背後により多くのサーバーノードを追加することに依存することが多いです。
このパターンは視覚的に把握しやすい。ユーザー環境とバックエンドインフラストラクチャの境界を明確に示している。しかし、現代の文脈では、要件が増大するにつれて、このパターンはしばしばより複雑な構造へと進化する。
2. マルチティア(Nティア)パターン 🏢
アプリケーションの複雑さが増すにつれ、単純な2ティアのクライアントサーバーモデルはボトルネックとなった。マルチティアパターンは、関心の分離を目的として中間層を導入し、通常はプレゼンテーション層、アプリケーション層、データ層にシステムを分割する。
図の構造
| レイヤー | デプロイメントノード | 主要アーティファクト |
|---|---|---|
| 1. プレゼンテーション | Webサーバー/クライアントデバイス | HTML、CSS、JavaScript |
| 2. アプリケーション | アプリケーションサーバー | コンパイル済みコード、ビジネスロジック |
| 3. データ | データベースサーバー | データベースインスタンス、スキーマ |
主な特徴
- 関心の分離: 各ティアは、独立して開発・テスト・スケーリングが可能である。
- セキュリティ: データベース層はしばしばパブリックインターネットから隔離され、アプリケーション層を介してのみアクセス可能である。
- 保守性: ユーザーインターフェースの変更が必ずしもデータ層に影響を与えるわけではない。
この図を描く際には、通信フローを明示することが重要である。クライアントはWebサーバーと通信し、Webサーバーはアプリケーションサーバーと通信し、アプリケーションサーバーはデータベースと通信する。各ティアに明確なノードを使用することで、この分離が視覚的に明確になる。
3. マイクロサービスパターン 🧱
マイクロサービスアーキテクチャは、大きなアプリケーションを小さな独立したサービスに分割する。各サービスは独自のプロセスで実行され、軽量なメカニズムを介して通信する。デプロイメント図では、モノリシックなマルチティアモデルとは大きく異なる外観となる。
図の構造
- サービスノード: 複数のノードがあり、それぞれが特定のマイクロサービスをホストする。これらはしばしば共有されたオーケストレーションプラットフォーム上で実行されるコンテナである。
- APIゲートウェイ: 要求を適切なサービスにルーティングする単一のエントリポイントノード。
- サービスメッシュ: サービス間通信、セキュリティ、監視を処理するオプションのインフラストラクチャノード。
主な特徴
- 独立したデプロイ: 1つのサービスを、システム全体を再デプロイせずに更新できる。
- 技術の多様性: 異なるサービスは、異なるランタイム環境やデータベースを使用できる。
- レジリエンス: 1つのサービスで障害が発生しても、システム全体がダウンするとは限らない。
マイクロサービスを可視化するには、線の管理に注意が必要である。接続が多すぎると「スパゲッティ図」になってしまう。ドメイン(例:「注文サービス」、「ユーザー サービス」)ごとにサービスをグループ化することで、アーキテクチャを明確にできる。また、すべてのノードをサポートする共有インフラストラクチャ層(例:メッセージキュー、集中型ログ記録サービスなど)を表示することも一般的である。
4. クラウドネイティブおよび分散型パターン ☁️
現代のシステムはしばしばパブリッククラウドインフラに依存している。これらの図は、物理的なハードウェアが抽象化されているため、オンプレミスの図とは異なる。焦点は論理的なリージョン、可用性ゾーン、およびマネージドサービスに移る。
図の構造
- リージョンノード: インフラストラクチャが展開される大きな地理的領域。
- 可用性ゾーン: リージョン内の明確なデータセンターで、しばしばサブノードとして表示される。
- マネージドサービス: ストレージバケット、キュー ブローカー、またはサーバーレス関数などのサービスを表すアーティファクト。
主な特徴
- 弾性: ノードは需要に応じて自動的にスケーリングアップまたはスケーリングダウンできる。
- 冗長性: クリティカルなコンポーネントは可用性ゾーン across にレプリケートされ、稼働時間を確保する。
- コスト管理: 図はクラウドリソースのコスト構造(例:使用課金 vs. 予約済みインスタンス)を反映している。
これらの図を描く際には、ノードをリージョンごとにグループ化すると便利である。たとえば、プライマリリージョンと災害復旧リージョンを並べて表示する。これによりフェイルオーバー戦略が明確になる。また、どの接続がパブリックインターネットを通過するか、どの接続がプライベートクラウドネットワーク内に留まるかを明示することも重要である。
5. エッジコンピューティングパターン 🌍
エッジコンピューティングは、計算をデータの発生源に近づける。これはIoT、ゲーム、リアルタイム分析で一般的である。このパターンのデプロイ図は、中央データセンターを超えて、周辺デバイスを含むように拡張される。
図構造
- エッジノード:データソースの近くに配置されたローカルサーバーまたは強力なデバイス(例:工場ゲートウェイ、基地局)。
- 中央クラウド:重い処理および長期保存のための主要なバックエンド。
- 同期接続:エッジとクラウドの間の接続で、通常は非同期である。
主な特徴
- 低遅延:処理はローカルで行われ、応答時間を短縮する。
- 帯域幅効率:重要なデータのみが中央クラウドに送信される。
- 自律性:ネットワーク接続が失われた場合でも、エッジノードはしばしば独立して機能できる。
エッジコンピューティングを図示するには階層を示す必要がある。中央クラウドがルートであり、地域のエッジノードへと枝が伸びる。これによりステークホルダーはデータがどこで処理され、どこに保存されるかを理解できる。エッジノードがセキュリティが低い物理的場所にある可能性があるため、セキュリティの考慮もここでは重要である。
6. ロードバランシングクラスターパターン 🔄
高可用性は企業システムにとって一般的な要件である。このパターンでは、同一の複数のノードを使用して作業負荷を共有し、1つのノードが障害を起こした場合でも他のノードが引き継ぐことを保証する。
図構造
- ロードバランサー ノード:受信トラフィックを分散する専用ノード。
- サーバークラスタ:同一のアプリケーションサーバーのグループ。
- ヘルスチェック:ロードバランサーがサーバーノードの状態を監視していることを示す論理リンク。
主な特徴
- 高可用性:メンテナンス時やハードウェア障害時でもシステムは稼働を維持する。
- パフォーマンス:トラフィックが分散され、単一のノードがボトルネックになるのを防ぐ。
- 状態管理: セッションデータの取り扱いには注意が必要です(例:スタイキー・セッションや共有状態)
この構成を表現する際には、クラスターノードを囲むボックスを描くことが一般的です。これにより、それらが単一の論理単位として機能していることを示します。ロードバランサーはこのボックスの外側に配置され、エントリーポイントとして機能します。これにより、運用チームに冗長性戦略が明確に伝わります。
7. イベント駆動型アーキテクチャパターン ⚡
イベント駆動型システムでは、コンポーネントは直接のリクエストを待つのではなく、イベントに反応します。これにより、データの生産者と消費者が分離されます。デプロイメント図は、この非同期通信を反映しています。
図の構造
- プロデューサー・ノード: イベントを生成するサービス。
- コンシューマー・ノード: イベントの受信と処理を行うサービス。
- メッセージブローカー: プロデューサーとコンシューマーの間でメッセージをルーティングする責任を持つ中央ノード。
主な特徴
- 分離: プロデューサーは、どのコンシューマーが存在するかを知る必要がありません。
- スケーラビリティ: コンシューマーは、メッセージキューの深さに基づいて個別にスケーリングできます。
- 信頼性: メッセージはブローカーに永続化されることが多く、データ損失を防ぎます。
このパターンを可視化するには、メッセージブローカーをハブとして表示します。プロデューサーからブローカーへ、そしてブローカーからコンシューマーへと線が流れます。これらの経路に特定のプロトコル(例:「MQTT」や「AMQP」)をラベル付けすることで、明確さが増します。また、どのコンシューマーがアクティブで、どのコンシューマーが停止状態かを明記すると便利です。
デプロイメントパターンの比較 📊
違いを要約するために、以下の表は各パターンに関連するトレードオフを概説しています。
| パターン | 複雑さ | スケーラビリティ | 最適な使用ケース |
|---|---|---|---|
| クライアント・サーバー | 低 | 中程度 | シンプルな社内ツール |
| マルチティア | 中程度 | 高 | エンタープライズ向けWebアプリケーション |
| マイクロサービス | 高 | 非常に高い | 大規模で進化するプラットフォーム |
| クラウドネイティブ | 中程度 | 弾性 | 公開向けSaaS |
| エッジコンピューティング | 高 | 変動する | IoTとリアルタイム処理 |
| 負荷分散 | 中程度 | 高 | 稼働時間の重要なサービス |
| イベント駆動型 | 高 | 高 | 非同期ワークフロー |
図示のためのベストプラクティス 📝
デプロイメント図を作成することは、技術的な作業と同じくらい芸術的な側面があります。既存のガイドラインに従うことで、図が長期間にわたり有用なまま保たれます。
1. 抽象化レベルを維持する
1つの図ではほとんどすべての詳細を捉えることはありません。異なる対象者向けに異なる視点を使用してください。経営層向けの視点では、地域や主要なサービスを示すことができます。エンジニアリング向けの視点では、特定のノード、ポート、プロトコルを示すべきです。これらのレベルを1つの画像に混在させないでください。
2. 明確な命名規則を使用する
ノードには意味のある名前を付けるべきです。「ノード1」や「サーバA」のような汎用的なラベルを避けてください。代わりに「Webサーバクラスタ」や「本番データベース」を使用してください。アーティファクトも、その機能を反映するように名前を付けるべきです。たとえば「App.jar」ではなく「決済処理モジュール」といった名前です。
3. 通信プロトコルを定義する
接続をラベル付けましょう。リンクが「HTTPS」であることを知ることで、一般的な線よりも多くの情報を得られます。これにより、セキュリティチームは潜在的な脆弱性を特定し、ネットワークエンジニアは帯域幅の要件を計画できます。
4. セキュリティ境界を示す
破線または陰影付き領域を使用してセキュリティゾーンを示しましょう。システムのどの部分がパブリックインターネットに公開されているか、どの部分が内部専用であるかを明確にマークしてください。これはコンプライアンスおよびリスク評価において不可欠です。
5. 更新を維持する
現実と一致しないデプロイメント図は、まったく図がないよりも悪いです。図の更新をデプロイメントパイプラインに統合しましょう。インフラ構成が変更されるたびに、図は見直され、修正されるべきです。
避けたい一般的なミス ⚠️
経験豊富なアーキテクトでも、インフラの可視化において誤りを犯すことがあります。これらの落とし穴を認識することで、図の品質を維持できます。
- 過剰設計:クラスタ内のすべての物理サーバーを含めると、図が読みにくくなります。論理的にグループ化しましょう。
- 遅延を無視する:異なる大陸にある2つのノード間の接続を示す際に、遅延の影響を記載しないと、パフォーマンス上の問題が生じる可能性があります。
- 依存関係の欠落:サービスが特定のデータベースや設定ファイルに依存していることを示さないことで、デプロイメントの失敗が発生する可能性があります。
- 静的表現:クラウドシステムは動的です。固定されたリソース割り当てを示す静的スナップショットを避けてください。
- 論理的と物理的を混同する:図が物理的なデプロイメントを表していることを確認してください。論理的なコンポーネントは複数の物理ノード上に存在する可能性があります。
図をインフラ構成の現実にマッピングする 🌐
デプロイメント図はモデルです。最終的には実際のインフラ構成に変換される必要があります。この変換プロセスにはいくつかのステップがあります:
- リソースサイズの決定:図内のノードに基づいて、CPU、メモリ、ストレージの要件を決定します。
- ネットワーク構成:通信経路がファイアウォールルール、サブネット、ルーティングテーブルを決定します。
- 自動化:現代のインフラ構成は、コードを使って図を定義します。ツールを使用すると、テキストファイルでノードと接続を定義でき、それによって実際の環境がプロビジョニングされます。
- モニタリング:図内のノードは、モニタリング対象のエンティティに対応している必要があります。ノードがモニタリングされていない場合、運用チームには見えません。
この整合性により、実装過程で設計意図が保持されます。図にロードバランサーが表示されている場合、プロビジョニングスクリプトはそれを作成しなければなりません。図にデータベースレプリカが表示されている場合、インフラ構成はそれをサポートしなければなりません。
結論 🏁
デプロイメント図は、ソフトウェアシステムの物理構造を伝えるための必須ツールです。シンプルなクライアント・サーバーモデルから複雑なマイクロサービスやエッジコンピューティングの構成まで、一般的なパターンを理解することで、チームはより強固で保守性の高いアーキテクチャを設計できます。
成功の鍵は明確さにあります。良い図は質問が投げられる前に答えを示します。データがどこに存在するか、どのように移動するか、そして何が問題になったときに何が起こるかを示します。ベストプラクティスを守り、一般的な落とし穴を避けることで、アーキテクトはシステムのライフサイクル全体において信頼できるガイドとなる図を構築できます。
新しいインフラを計画している場合でも、既存のものを文書化している場合でも、これらのパターンを適用することで、視覚的表現が技術的現実と一致することを保証します。この整合性こそが信頼性の高いソフトウェア配信の基盤です。

